
Cursor编程-从入门到精通
# qwen系列
文本 qwen-turbo API
qewe3-0.6,8B,32B开源模型(企业内部进行部署)VL模型
qwen-vl多模态,可以对图像内容进行理解code模型
qwen3-coder
# AI编程
Cursor是基于VSCode开发的AI代码编辑器,提供智能代码补全、代码生成、代码修改、代码搜索和代码解释等。
与其他工具不同,Cursor将AI辅助编码直接融入到编辑器的核心功能中,比如Curosr可以理解整个工程的代码,同时修改多个文件。
可以通过.cursorrules文件定制AI的行为。
使用通义灵码也行,trae,codebuddy也行
# AI编程的问题
- bug修改问题
- 过度修改现象: AI在修复指定bug时,可能会连带修改其他原本正确的功能代码
- 解决方案: 明确指令要求"只修改当前指定功能,不要改动其他功能"
- 效果评估: 该指令不能保证100%有效,但能显著减少非必要修改的情况
- 中文乱码问题
- 常见表现: 生成的注释出现乱码或自动转为英文
- 编码要求: 需明确指定使用"中文UTF-8编码"
- 检查机制: 要求AI在生成中文内容后自动检查是否存在乱码,发现后立即修正
# 函数修改原则
- 逻辑保留
- 核心原则: 修改函数时必须先理解原有实现逻辑
- 禁止操作: 不得移除原有的函数路由结构
- 修改方式: 在原有逻辑基础上进行增量修改
- 功能专注
- 指令规范: 当指定完成功能A时,AI应专注该功能不涉及功能B
- 实践意义: 避免AI自作主张重构整个代码逻辑
# 规则设置
通义灵码支持项目专属规则(Project Rules)的设定, 这些规则存储在 .lingma/rules 目录下,仅对当前工程生效。通过设定项目专属规则,可以帮助模型更精准地理解并适应您的编码偏好,例如理解项目框架和代码风格等。
据引入和触发方式的不同,我们将规则分为以下4个类型,以灵活适配各类业务场景。
| 类型 | 触发方式 | 适用场景 |
|---|---|---|
| 手动引入(Manual) | 在智能会话或行间会话中通过#rule手动引入才生效。 | 按需执行一次性或特定的工作流、自定义提示词等。 |
| 模型决策(Model Decision) | 在智能会话中使用智能体模式时,或在智能问答开启工具使用后,模型将根据用户定义规则的描述内容,自主决策是否应用该规则。 | 由模型自主决策,仅在特定场景下生效的规则,例如生成单测时生效,或生成注释时生效等。 |
| 始终生效(Always) | 在智能会话与行间会话中的所有请求中均会生效。 | 设定项目级的通用规范,如编码风格、偏好格式、默认的回答角色等 |
| 指定文件生效(Specific Files) | 在智能会话和行间会话中,根据用户指定的文件匹配模式(如 .js、src/**/.ts),此规则将应用于所有符合该模式的文件。 | 可以根据通配符精准匹配生效的文件范围,为特定语言或目录创建专属规则。例如,针对某类语言生效的规则,或针对某个文件夹生效的校验规则。 |
如果不知道怎么写规则,可以参考https://atomgit.com/lingma-org/lingma-project-rule-template (opens new window)
# CASE:多张Excel报表处理
TO DO:两张Excel报表合并
比如 将员工基本信息表与员工绩效表合并,比如在主表基础上,添加员工2024年第4季度的绩效评分
打开灵码,配置python编译环境
Agent模式下输入指令:帮我将员工基本信息表.xlsx, 员工绩效表.xlsx这两张Excel合并,即在 员工基本信息表.xlsx的基础上,增加该员工2024年第4季度的绩效评分
然后就自动写好了,妈耶好简单
提示
写提示词时,要在正确的基础上,继续做下面的事情; 分步骤来做会比较方便
先思考人是怎么做的,分成几个步骤,步骤之间有逻辑顺序
锻炼人的思维 =》 撰写需求分析,拆成不同的步骤
# CASE:疫情实时监控
CASE:疫情实时监控
数据表data.xlsx,原始数据见https://github.com/cystanford/dashboard_epidemic
整合了疫情的关键指标数据,适用于疫情可视化大屏展示及数据分析。
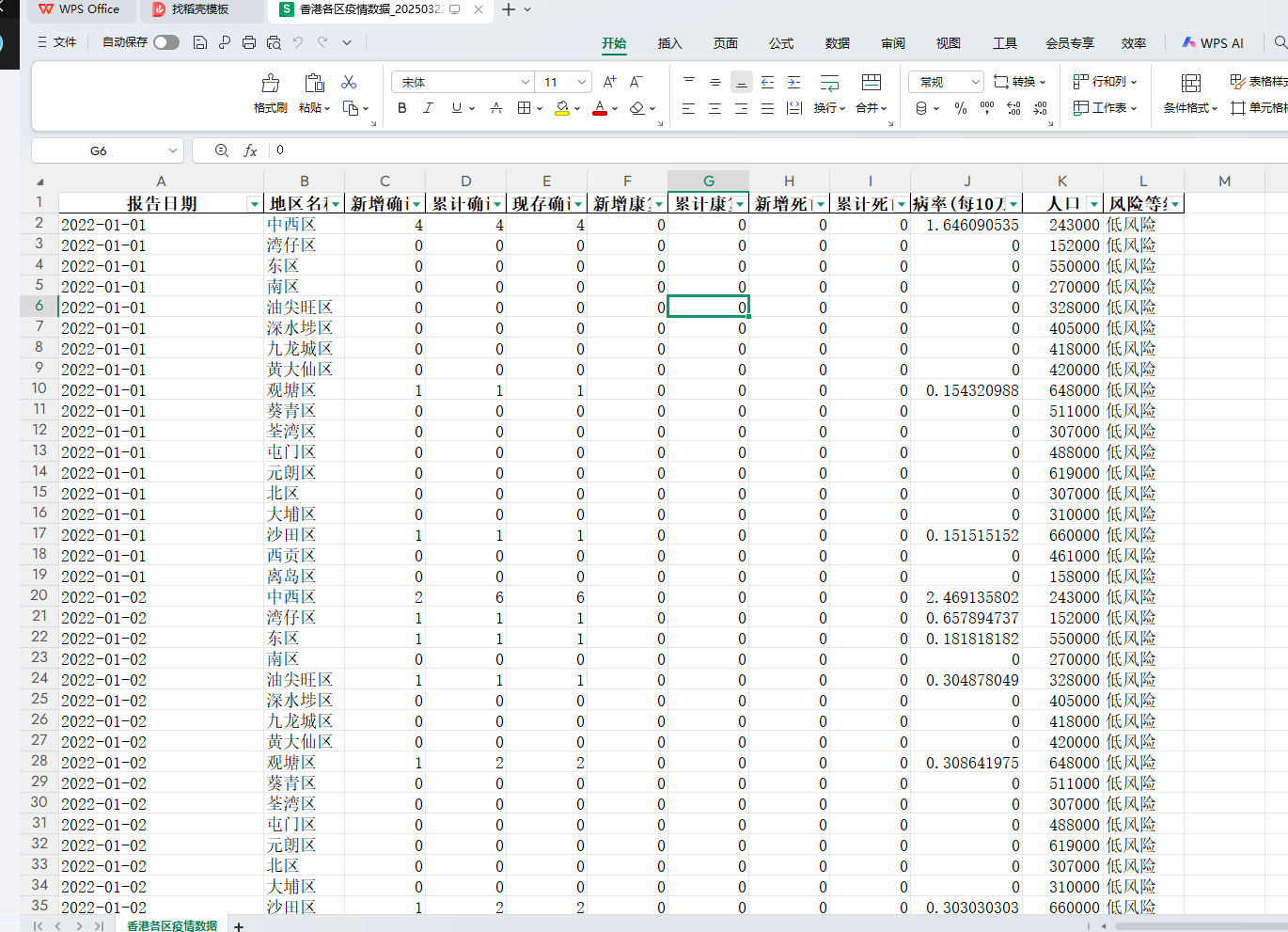
数据表记录了香港各区每日疫情变化情况,包含确诊、康复、死亡等核心指标,以及区域风险评估结果。
TO DO:
1)确诊病例数:每日新增与累计确诊数据
2)地理分布图:各区域疫情分布及热点区域标识
3)趋势分析图:病例增长趋势、增长率变化图表
……
数据表长这样
# 开始理解需求,拆分步骤
- 理解数据表的字段含义
- 画图:横坐标是报告日期,纵坐标是新增确诊认数
# AI编程
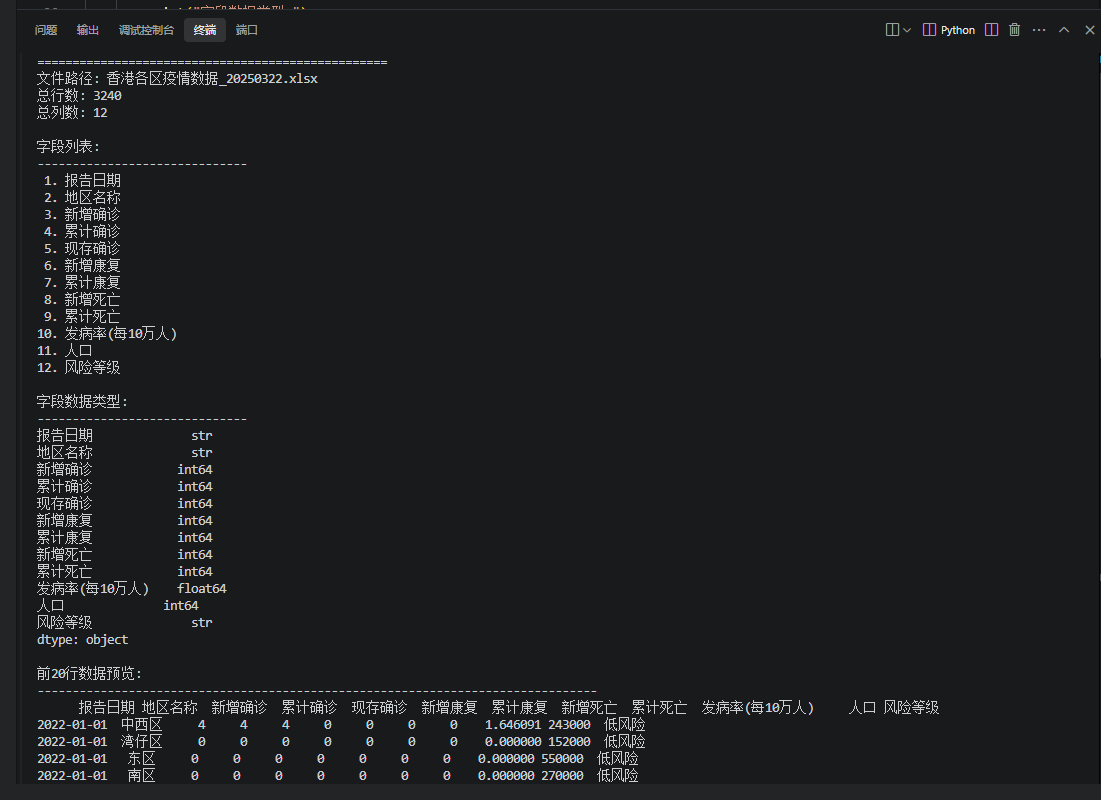
编写Python,查看 香港各区疫情数据_20250322.xlsx的字段和前20行数据
帮我画图,显示新增确诊人数,横坐标是报告日期
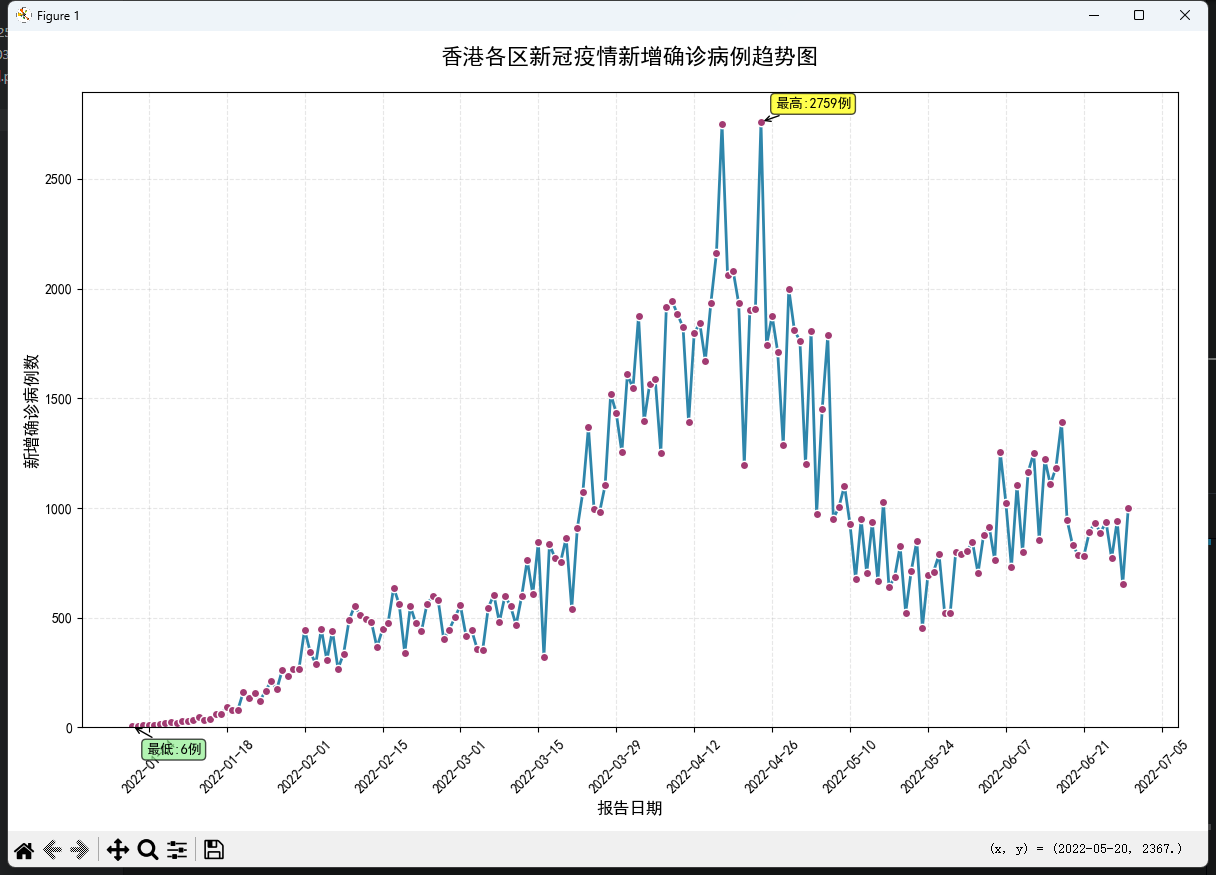
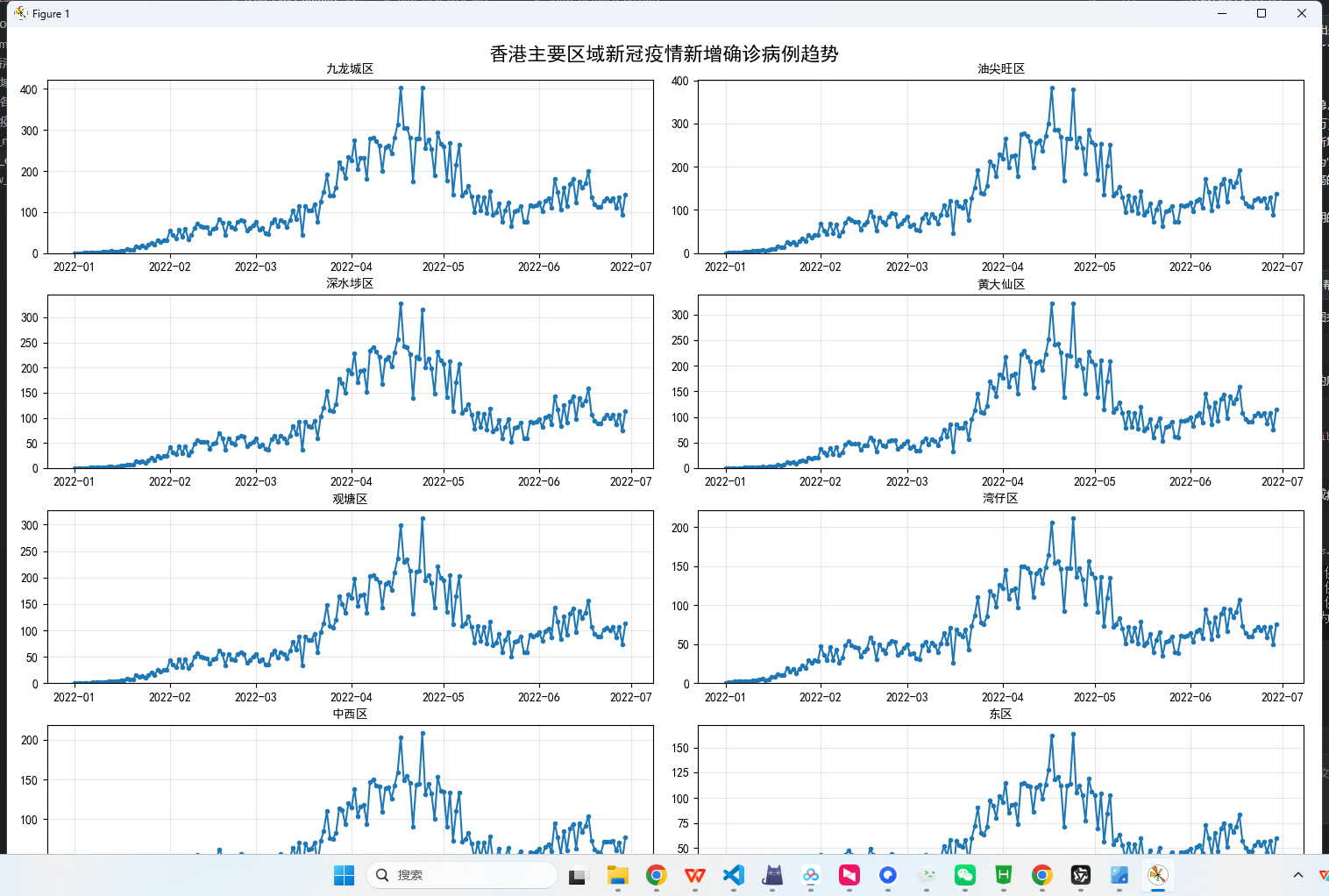
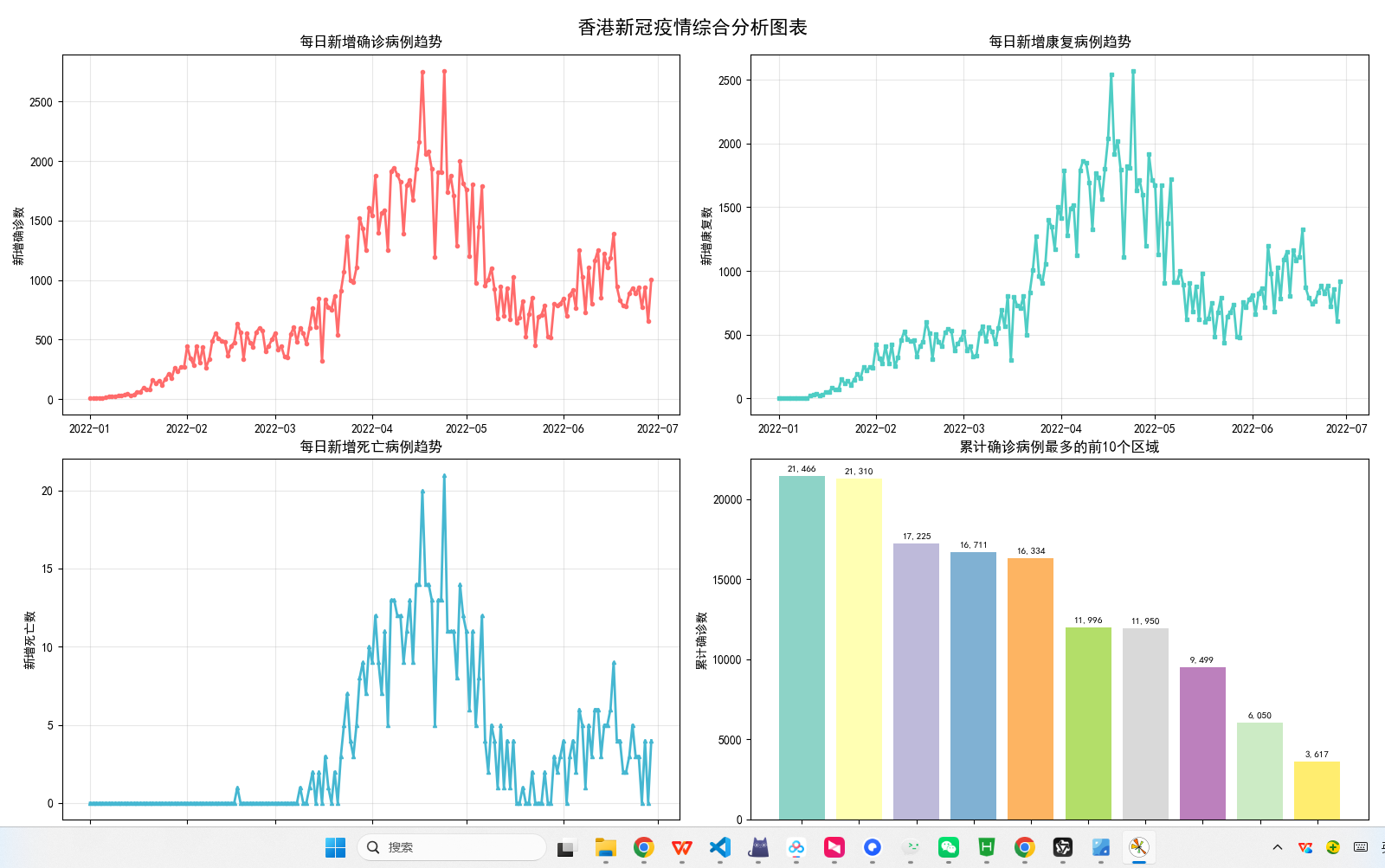
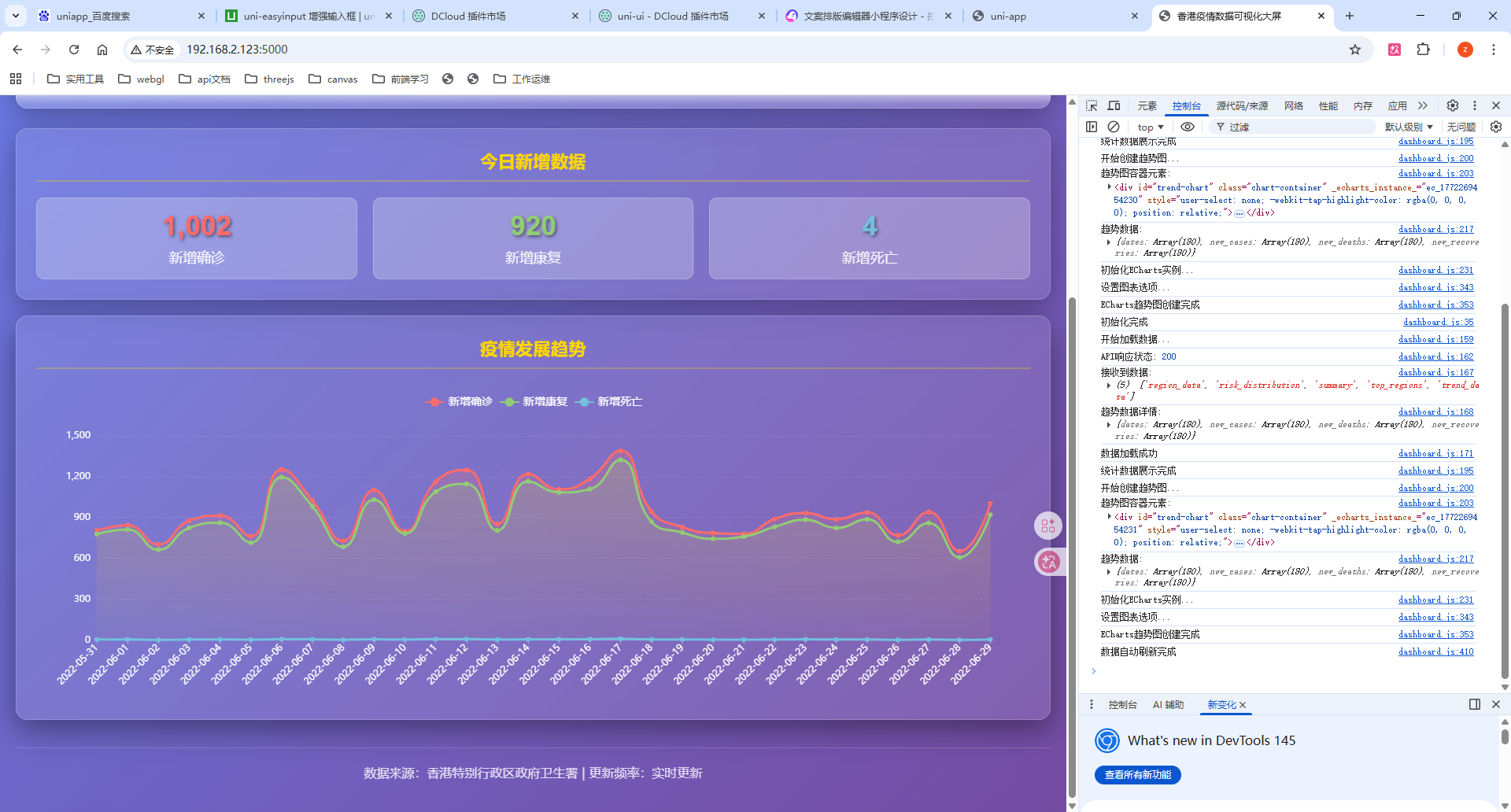
帮我制作可视化大屏,选择适合的图表样式,图表的数量不超过5个,用Flask + Echarts实现
提示
- Flask后端框架
- 功能定位:作为数据服务的后端支撑
- 交互流程:接收请求→处理数据→返回可视化结果
- Echarts可视化库
- 图表类型:支持折线图等多样化展示形式
- 数据绑定:需确保前端展示与后端数据严格对应
- 动态更新:可实现疫情数据的实时可视化呈现
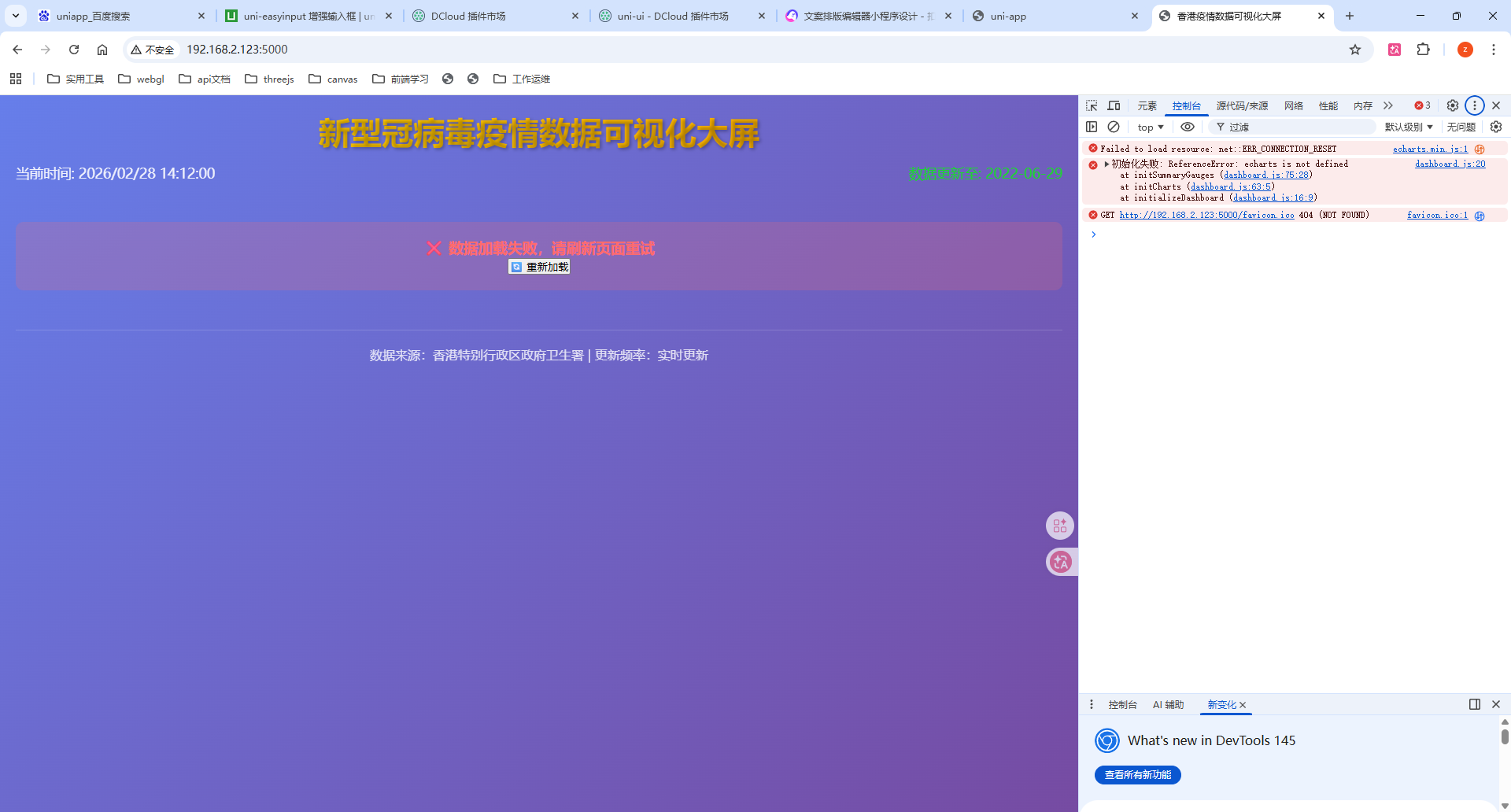
可以看到,AI写的可视化大屏并不是第一次就能成功的
- 把报错的截屏给AI,然后我们慢慢调整
# AI产品评估
- 评估指标分析
- 响应速度:AI产品的关键指标,理想响应时间应在5秒内,最长不超过10秒。超过10秒用户可能流失(举例:与豆包等AI交互时的用户体验)
- 准确度要求:企业级应用通常要求99.9%的高准确率。以客服场景为例,2000通电话中1%错误率意味着20次错误回答,可能导致产品报价等关键信息错误
- 安全防护:需防范"奶奶攻击"等社会工程学攻击手段(案例:攻击者诱使AI泄露Windows密钥),企业私有数据(如知识库文件、内部表格)需特别保护
- 数据安全性评估
- 验证机制:通过prompt要求AI对比原始数据,回复时标注参考来源(如必应搜索的角标功能),实现回答可追溯
- 风险场景:企业私有化部署时,需防范通过精心设计的问题套取敏感数据(如财务表格、机密文档)
- 防护方案:建立数据来源检测流程,验证回答与来源的一致性,这是企业IT部门的核心验收标准
# 模型部署
本地化部署Qwen3-coder
部署成本:以7B模型为例,硬件成本约需100万元,主要因模型文件体积庞大(需H100等高端显卡)
资源获取:通过ModelScope平台可下载模型(如通义千问3-Coder),支持私有化部署但受限于硬件配置
模型切换:在阿里云等平台可通过密钥管理实现模型切换(如切换至3-plus模型)并发性能评估
- 单卡承载:H100显卡运行2B规模模型时,最佳并发数为8-10人,超过16人将出现明显延迟
- 服务分级:免费用户可能受全局资源池限制出现排队,会员服务可保证响应速度(如零码平台前50轮高质量响应)
- 优化方案:通过模型量化等技术提升并发能力,但需平衡精度损失与性能提升的关系