
RAGFlow详解
# 什么是RAGFlow
Retrieval-Augmented Generation:检索增强生成
RAG是一种将信息检索组件与文本生成模型相结合的技术,它通过检索外部知识源中的相关信息来增强语言模型的生成能力,从而生成更准缺,符合上下文且减少幻觉的答案。
# 基础配置
配置方面上一节已经说过了,更详细的可以参考 https://ragflow.io/docs/configurations (opens new window)
# 配置数据集
RAGFlow 中的大多数聊天助手和 Agent 都是基于数据集。每个 RAGFlow 数据集都作为知识来源,将从您本地机器上传的文件以及 RAGFlow 文件系统中生成的文件引用解析为未来的 AI 聊天所使用的实际“知识”。
RAGFlow 提供多种内置的分块模板,以帮助处理不同布局的文件并确保语义完整性。
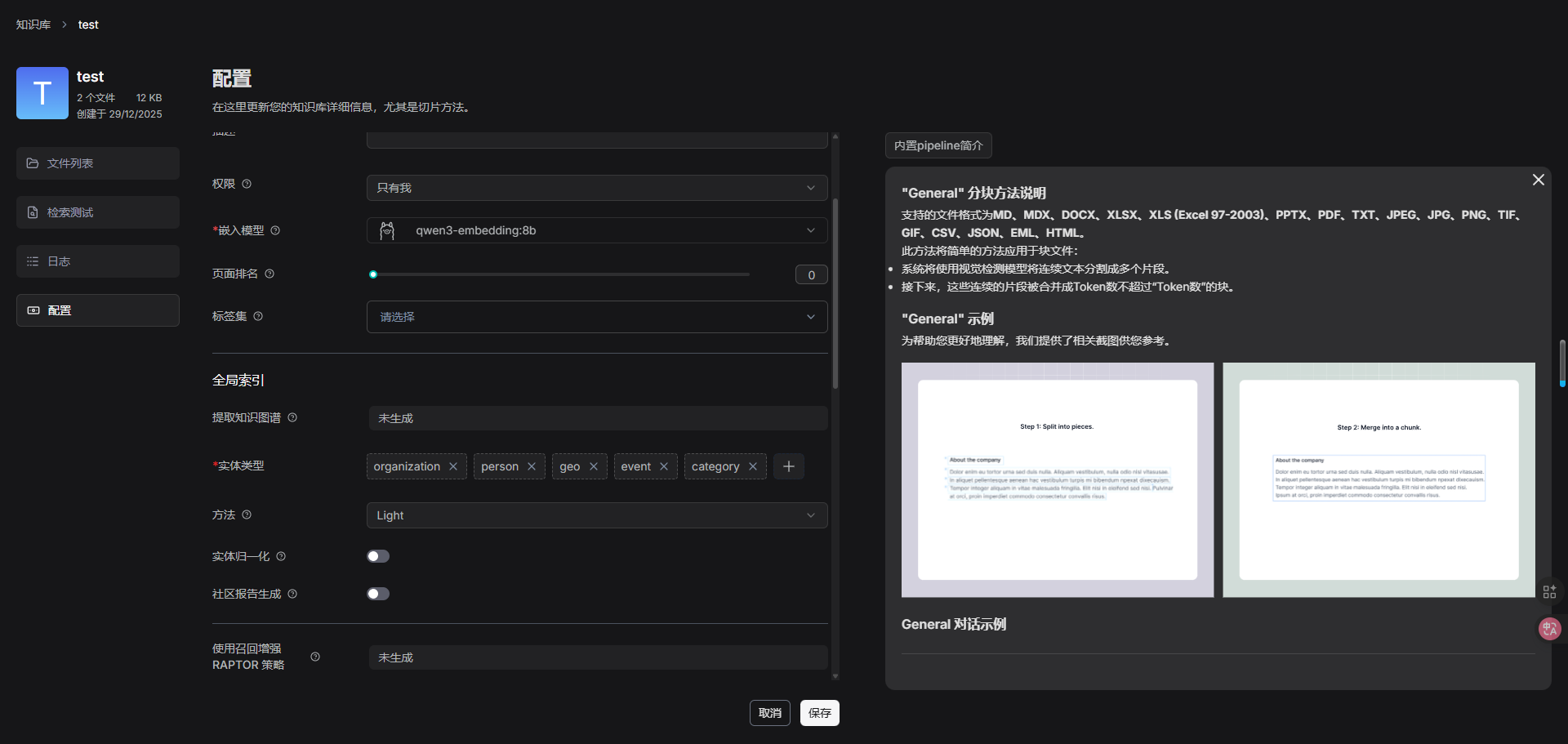
每种分块方式在介绍中都有
# 上传文件
- RAGFlow 的文件系统允许您将一个文件链接到多个数据集,此时每个目标数据集都保存对该文件的引用。
- 在知识库中,您也可以选择从本地机器上传单个文件或整个文件夹(批量上传)到数据集,此时数据集会保存文件的副本。
虽然直接上传文件到数据集似乎更方便,但我们强烈建议您先将文件上传到 RAGFlow 的文件系统,然后再将其链接到目标数据集。这样可以避免因删除数据集中的文件而导致的永久性丢失。
# 解析文件
文件解析是数据集配置中的一个重要主题。在 RAGFlow 中,文件解析的含义包含两个方面:根据文件布局对文件进行分块处理,并在这些分块上构建嵌入向量和全文(关键词)索引。在选择好分块方法和嵌入模型后,您可以开始解析文件:
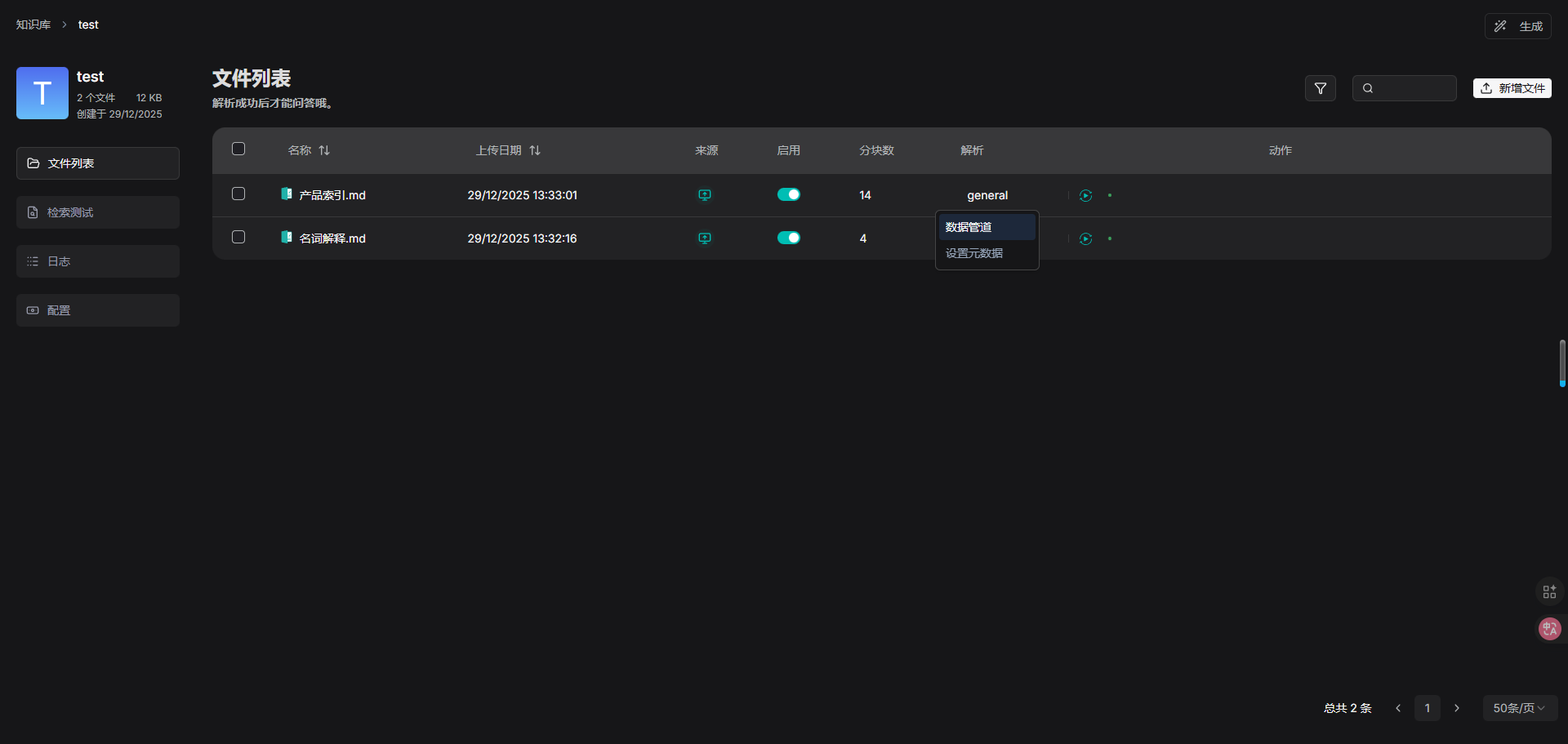
- 如上所示,RAGFlow 允许你为特定文件使用不同的分块方法,提供了超越默认方法的灵活性。
- 如上所示,RAGFlow 允许您启用或禁用单个文件,从而对基于数据集的 AI 聊天进行更精细的控制。
# 干预文件解析结果
RAGFlow 具备可见性和可解释性,允许您查看分块结果并在必要时进行干预。操作步骤如下:
- 点击完成文件解析的文件以查看分块结果,你被带到分块页面
- 悬停在每个快照上,可快速查看每个片段。
- 双击分块文本以添加关键词、问题、标签或在必要时进行手动修改,你可以为一个文件片段添加关键词,以提高其在包含这些关键词的查询中的排名。此操作会增加其关键词权重,并可以改善其在搜索列表中的位置。
- 在检索测试中,通过在测试文本中提出一个快速问题来验证你的配置是否有效
# 元数据
# 设置元数据
在您的数据集页面上,您可以为任何已上传的文件添加元数据。这种方法使您能够为现有文件“标记”额外的信息,例如 URL、作者、日期等。在 AI 驱动的聊天中,这些信息将与检索到的片段一起发送给 LLM,用于内容生成。
例如,如果您有一个 HTML 文件的数据集,并希望 LLM 在回答您的查询时引用源 URL,请为每个文件的元数据添加一个 "url" 参数。
请确保您的元数据为 JSON 格式;否则,您的更改将不会被应用。
# 设置页面排名
在 AI 聊天中,您可以配置聊天助手或代理,使其使用从多个指定数据集(datasets)中检索到的知识进行回答,前提是这些数据集使用相同的嵌入模型。如果您希望某些数据集的信息优先或首先被检索,可以使用 RAGFlow 的页面排名功能来提升这些数据集中的片段排名。例如,如果您配置了一个聊天助手从两个数据集中获取信息,数据集 A 用于 2024 年的新闻,数据集 B 用于 2023 年的新闻,但希望优先获取 2024 年的新闻,此功能尤其有用。
# 自动关键词 自动问题
使用聊天模型从数据集中的每个片段生成关键词或问题。
在选择分块方法时,您也可以启用自动关键词或自动问题生成以提高检索率。此功能使用聊天模型从每个创建的片段中生成指定数量的关键词和问题,从而从原始内容中生成“额外的信息层”。
# 什么是自动关键词?
自动关键词指的是 RAGFlow 的自动关键词生成功能。它使用聊天模型从每个片段中生成一组关键词或同义词,以纠正错误并提高检索准确性。此功能在数据集配置页面的 Page rank 下以滑块形式实现。
Values: 值:
- 0: (默认)禁用。
- 3 到 5(包含):如果你的片段大约有 1000 个字符,推荐使用此范围。
- 30(最大值)
# 什么是 Auto-question?
自动提问是 RAGFlow 的一个功能,它使用聊天模型从数据块中自动生成问题。这些问题(例如谁、什么、为什么)也有助于纠正错误并提高用户查询的匹配度。该功能通常用于涉及产品手册或政策文件的 FAQ 检索场景。您可以在数据集的配置页面上,在“页面排名”下找到这个功能,它以滑块的形式呈现。
Values: 值:
- 0: (默认)禁用。
- 1 或 2:如果您有大约 1,000 个字符的数据块,推荐使用此设置。
- 10(最大值)
# 社区提示
自动关键词或自动问题的值与您数据集中的分块大小密切相关。然而,如果您是第一次使用此功能,不确定应该从哪个值开始,以下是一些我们从社区中收集的值设置。虽然这些值可能并不完全准确,但至少可以作为起点。
| 使用场景或典型情况 | 文档数量/长度 | Auto_keyword (0–30) | Auto_question (0–10) |
|---|---|---|---|
| 员工手册内部处理指引 | 小型,少于 10 页 | 0 | 0 |
| 客户服务常见问题解答 | 中等,10–100 页 | 3–7 | 1–3 |
| 技术白皮书:开发标准,协议细节 | 大,超过 100 页 | 2–4 | 1–2 |
| 合同 / 规章 / 法律条款检索 | 超过 50 页 | 2–5 | 0–1 |
| 多仓库分层新文档 + 旧档案 | 许多 | 适当调整 | 适当调整 |
| 社交媒体评论池:多语言 & 混合拼写 | 大量短文本 | 8–12 | 0 |
| 用于故障排除的操作日志 | 大量短文本 | 3–6 | 0 |
| 营销素材库:多语言产品描述 | 中等 | 6–10 | 1–2 |
| 培训课程 / 电子书 | 大 | 2–5 | 1–2 |
| 维护手册:设备图示 + 步骤 | 中等 | 3–7 | 1–2 |
# 启用 Excel2HTML
当使用通用分块方法时,您可以启用 Excel 转 HTML 开关,将表格文件转换为 HTML 表格。如果该功能被禁用,表格将被表示为键值对。对于无法简单以这种方式表示的复杂表格,您必须启用此功能。
注意
该功能默认是禁用的。如果您的数据集中包含具有复杂表格的 Excel 文件,并且未启用此功能,RAGFlow 不会报错,但您的表格可能会出现乱码。
适用于无法表示为键值对的复杂表格。例如,包含多个列的电子表格表格、包含合并单元格的表格,或同一工作表中的多个表格。在这种情况下,请考虑将这些电子表格表格转换为 HTML 表格。
# 提取目录
从文档中提取目录(TOC),以提供长上下文的 RAG 并提高检索效果。
在索引过程中,该技术使用 LLM 提取并生成章节信息,将其添加到每个片段中以提供充分的全局上下文。在检索阶段,它首先使用搜索匹配的片段,然后根据目录结构补充缺失的片段。这解决了由于片段碎片化和上下文不足导致的问题,提高回答质量。
注意
启用 TOC 提取需要大量的内存、计算资源和令牌。
# 使用标签集
使用一个标签集来自动标记数据集中的片段。
检索准确性是生产就绪型 RAG 框架的关键。除了自动关键词、自动问题和知识图谱等提升检索效果的方法,RAGFlow 引入了自动标签功能以解决语义差距问题。自动标签功能会根据每个片段与标签集中的标签之间的相似性,自动将用户定义的标签集中的标签映射到数据集中的相关片段。这种自动化机制允许您在现有数据集上应用额外的“层”领域知识,这在处理大量片段时特别有用。
使用此功能时,请确保您至少配置了一个正确的标签集,在数据集的配置页面上指定标签集(s),然后重新解析文档以启动自动标签过程。在此过程中,数据集中的每个片段都会与指定标签集中的每个条目进行比较,并根据相似性自动应用标签。
# 启用 RAPTOR
一种用于长上下文知识检索和摘要的递归抽象方法,在广泛语义理解和细节之间取得平衡。
# 基本原理
在原始文档被分割成块之后,这些块是根据语义相似性进行聚类,而不是按照文本中的原始顺序。然后,您的系统默认聊天模型将这些聚类进一步总结成更高层次的块。这个过程是递归应用的,从而形成一个从下到上的多级摘要树结构。如下面的图所示,初始块形成叶节点(蓝色所示),并递归地被总结成根节点(橙色所示)。
对于涉及复杂、多步骤推理的多跳问答任务,问题与其答案之间常常存在语义鸿沟。因此,仅使用问题进行搜索往往无法获取有助于正确答案的相关片段。RAPTOR 通过为聊天模型提供更丰富、更具上下文感知性和相关性的片段来解决这一挑战,使模型能够全面理解而不丢失细节信息。
RAPTOR 功能默认是禁用的。如需启用,手动在数据集的配置页面上打开“使用 RAPTOR 增强检索”开关。
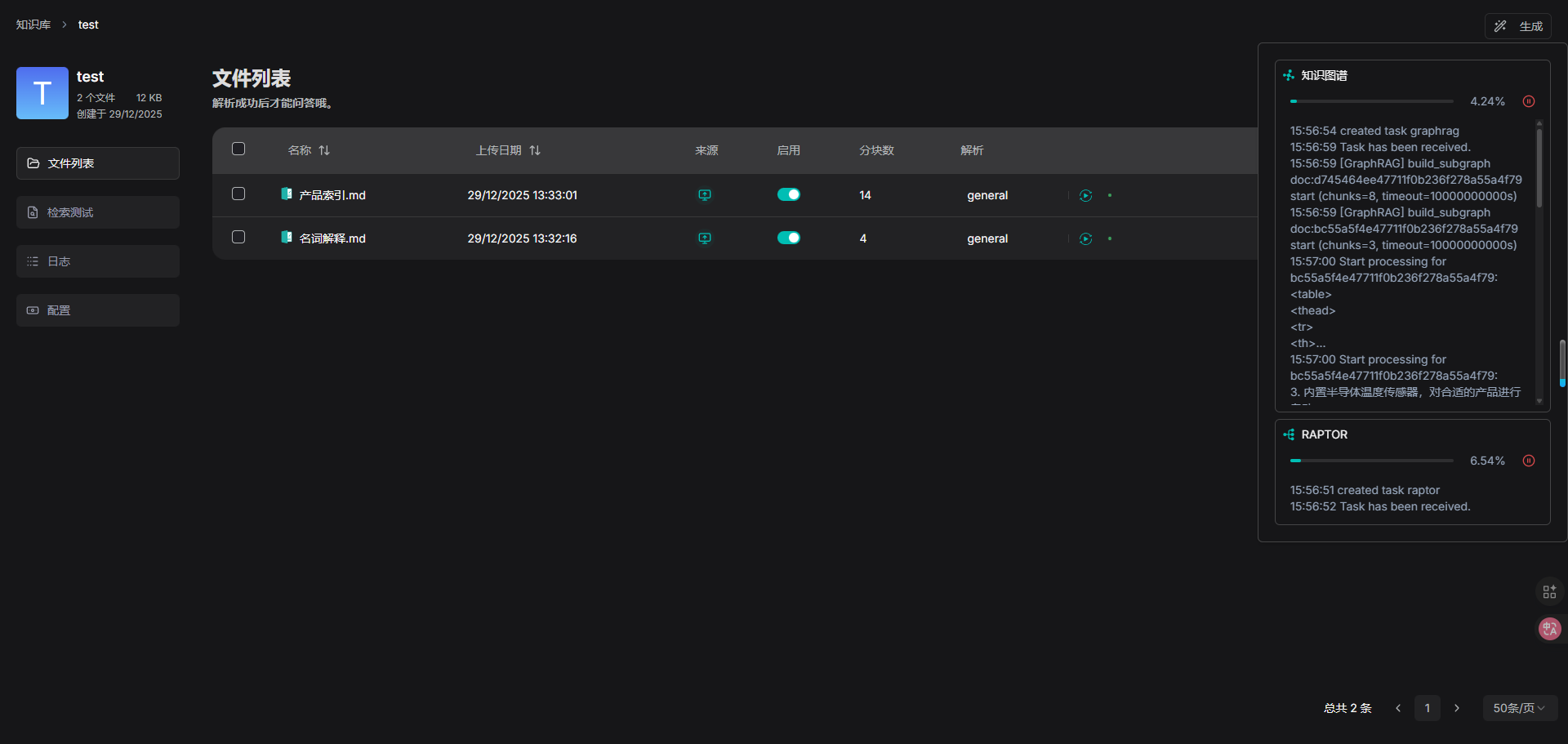
前往您的数据集的配置页面并更新:
- 提示:可选 - 我们建议您在了解其机制之前保持原样。
- 最大标记数:可选
- 阈值:可选
- 最大聚类数:可选
导航到你的数据集的文件页面,点击页面右上角的生成按钮,然后从下拉菜单中选择 RAPTOR 以启动 RAPTOR 构建过程。你可以在下拉菜单中点击暂停按钮,在必要时停止构建过程。
返回配置页面: RAPTOR 字段在生成 RAPTOR 分层树结构时会从 Not generated 变为 Generated at a specific timestamp 。你可以点击字段右侧的回收站按钮将其删除。
一旦生成了 RAPTOR 层次树结构,你的聊天助手和检索代理组件将默认使用它进行检索。
# 构建知识图谱
为您的数据集生成知识图谱。
知识图谱在涉及嵌套逻辑的多跳问答任务中特别有用。在对具有复杂实体和关系的书籍或作品进行问答时,它们的表现优于传统的抽取方法。
- 前往您的数据集的配置页面并更新:
实体类型:必填 - 指定在知识图谱中生成的实体类型。您不需要拘泥于默认设置,但需要根据您的文档进行自定义。 方法:可选 实体解析:可选 社区报告:可选 您的数据集的默认知识图谱配置已设置。
导航到你的数据集的文件页面,点击页面右上角的生成按钮,然后从下拉菜单中选择知识图谱以启动知识图谱生成过程。 你可以在下拉菜单中点击暂停按钮,在必要时停止构建过程。
返回配置页面:
一旦生成了知识图谱,知识图谱字段将从 Not generated 变为 Generated at a specific timestamp 。你可以通过点击字段右侧的回收站按钮来删除它。
- 要使用已创建的知识图谱,请执行以下任一操作: 在你的聊天应用的聊天设置面板中,打开使用知识图谱的开关。 如果你正在使用一个代理,点击检索代理组件以指定数据集(s),并打开使用知识图谱的开关。
# 运行检索测试
在您的数据集上进行检索测试,以检查预期的段落是否能够被检索到。
在文件上传并解析完成后,建议您在继续配置聊天助手之前运行一次检索测试。运行检索测试绝不是可有可无或多余的步骤!就像精细调校精密仪器一样,RAGFlow 也需要仔细调校才能实现最佳的问答性能。您的数据集设置、聊天助手配置以及指定的大模型和小模型都可能显著影响最终结果。运行检索测试可以验证预期的段落是否能够被恢复,让您快速识别需要改进的方面或定位需要解决的问题。例如,在调试您的问答系统时,如果您知道正确的段落能够被检索到,就可以将精力集中在其他方面。
# Chat聊天集成到应用程序或网页中
RAGFlow 提供 HTTP 和 Python 接口,以便您将 RAGFlow 的功能集成到您的应用程序中。
# Acquire RAGFlow API key
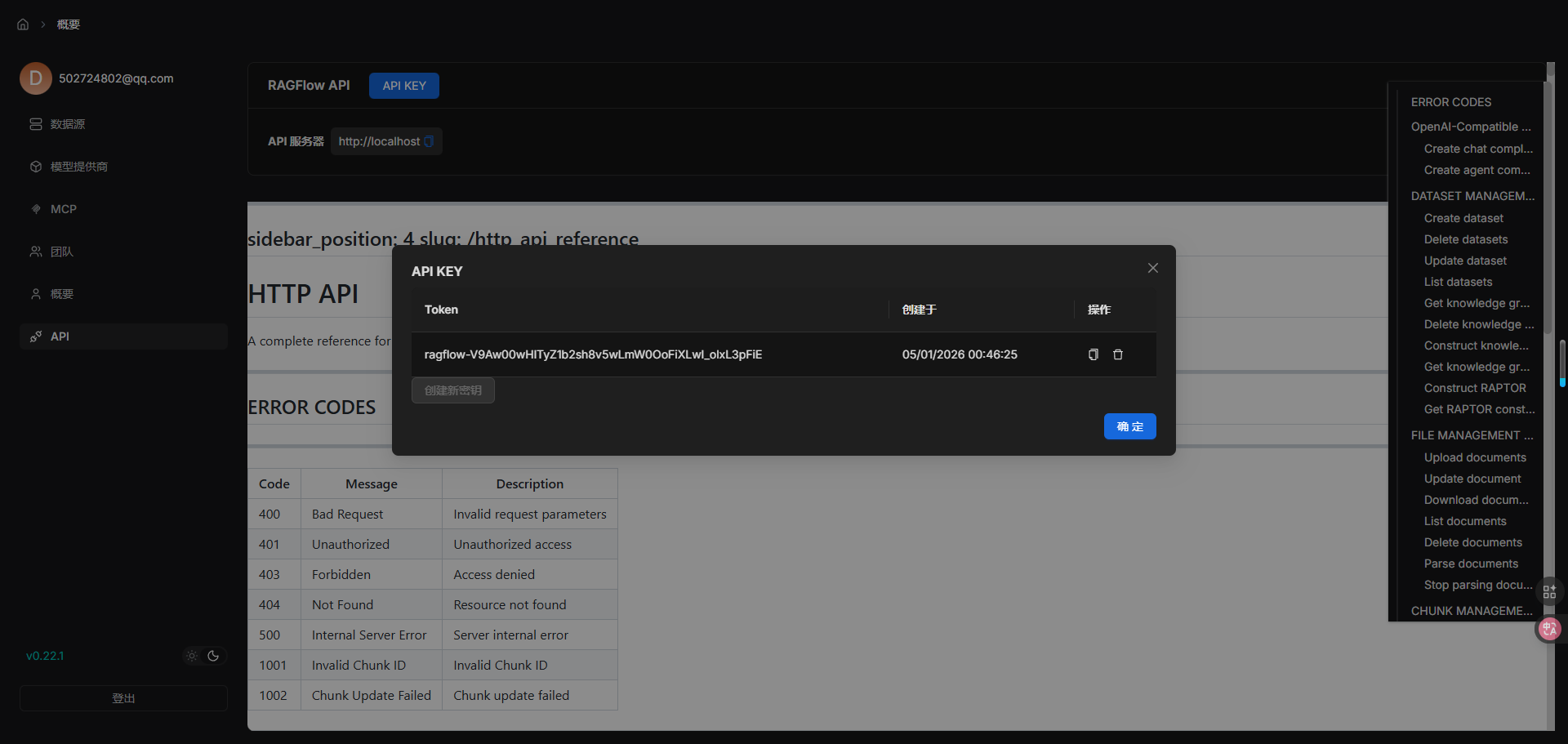
一个 API 密钥是 RAGFlow 服务器验证您的 HTTP/Python 或 MCP 请求所必需的。本文档提供了获取 RAGFlow API 密钥的说明。
- 在 RAGFlow 界面右上角点击您的头像以访问配置页面。
- 点击 API 切换到 API 页面。
- 获取 RAGFlow API 密钥
# 嵌入网页
你可以使用 iframe 将创建的聊天助手嵌入到第三方网页中:
- 在继续之前,您必须获取一个 API 密钥,否则会出现错误信息。
- 悬停在目标聊天助手上方 > 编辑以显示 iframe 窗口
- 复制 iframe 并嵌入到您的网页中。