
正则表达式
# 正则表达式是什么
正则表达式其实就是一门工具,目的是为了字符串模式匹配,从而实现搜索和替换功能,它是一种用来描述规则的表达式,而它的底层原理也十分简单,就是使用状态机的思想进行模式匹配。
# 模糊匹配
# 横向模糊匹配
横向模糊指的是,一个正则可匹配的字符串的长度是不固定的,可以是多种情况的。其实现的方式是使用量词,譬如{m,n},表示连续出现最少m次,最多n次。
比如 /ab{2,5}c/ 表示匹配这样一个字符串:第一个字符是 a, 接下来是2到5个字符 b, 最后字符是 c
var reg = /ab{2,5}c/g
var string = "abc abbc abbbc abbbbc abbbbbc abbbbbbbc"
console.log(string.match(reg))
// ["abbc", "abbbc", "abbbbc", "abbbbbbc"]
2
3
4
# 纵向模糊匹配
纵向模糊指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。其实现的方式是使用字符组。譬如[abc],表示该字符可以是a,b,c中的任何一个。比如/a[123]b/可以匹配如下三种字符串:"a1b","a2b","a3b"。
var reg = /a[123]b/g
var string = "a0b a1b a2b a3b a4b"
console.log(string.match(reg))
// ["a1b","a2b","a3b"]
2
3
4
# RegExp
# 构造正则表达式
- 字面量形式
可以使用如下简洁语法构造正则表达式:
let expression = /pattern/flags
这个正则表达式的pattern(模式)可以是任何简单或复杂的正则表达式。 每个正则表达式可以带零个或多个flags(标记),用于控制正则的表达式的行为。
- 使用RegExp构造函数
let expression = new RegExp(pattern, flags)
它接收两个参数: 模式字符串和标记字符串(可选的)。
使用RegExp可以基于已有的正则表达式实例,并且可以选择性地修改他们的标记:
const re1 = /cat/g
console.log(re1) // /cat/g
const re2 = new RegExp(re1)
console.log(re2)// /cat/g
const re3 = new RegExp(re1, "i")
console.log(re3) // /cat/i
2
3
4
5
6
7
8
这两种方式是可以等价的,比如:
// 匹配第一个“bat”或“cat”,忽略大小写
let pattern1 = /[bc]at/i
// 跟pattern1一样,只不过是用构造函数创建的
let pattern2 = new RegExp("[bc]at","i")
2
3
4
5
这里的pattern1和pattern2是等效的正则表达式。
注意
RegExp构造函数的两个参数都是字符串。因为RegExp的模式参数是字符串,所以在某些情况下需要二次转义。
所有元字符都必须二次转义,包括转义字符序列,如\n(\转义后的字符串是\\,在正则表达式字符串中则要写成\\\\)
| 字面量模式 | 对应字的符串 |
|---|---|
/\[bc\]at/ | "\\[bc\\]at" |
/\.at/ | "\\.at" |
/name\/age/ | "name\\/age" |
/\d.\d{1,2}/ | "\\d.\\d{1,2}" |
/\w\\hello\\123/ | "\\w\\\\hello\\\\123" |
# 模式标记(修饰符)
| 修饰符 | 模式 | 说明 |
|---|---|---|
| g | 全局模式 | 查找字符串的全部内容,而不是找到第一个匹配的内容就结束 |
| i | 不区分大小写 | 在查找匹配时忽略pattern和字符串的大小写 |
| m | 多行模式 | 查找到一行文本末尾时会继续查找 |
| y | 粘附模式 | 只查找从lastIndex开始及之后的字符串 |
| u | Unicode模式 | 启用Unicode匹配 |
| s | dotAll模式 | 表示元字符.匹配任何字符(包括\n和\r) |
# 实例属性
每个RegExp都有下列属性:
| 属性名 | 类 型 | 含义 |
|---|---|---|
| global | 布尔值 | 是否设置了g标记 |
| ignoreCase | 布尔值 | 是否设置了i标记 |
| unicode | 布尔值 | 是否设置了u标记 |
| sticky | 布尔值 | 是否设置了y标记 |
| lastIndex | 整数 | 在原字符串中下一次搜索的开始位置,始终从0开始 |
| multiline | 布尔值 | 是否设置了m标记 |
| dotAll | 布尔值 | 是否设置了s标记 |
| source | 字符串 | 正则表达式的模式字符串,没有开头和结尾的斜杠 |
| flags | 字符串 | 正则表达式的标记字符串 |
# 实例方法
# exec()
主要用于配合捕获组使用。
- 参数
这个方法只接收一个参数,即要应用模式的字符串。 - 返回
如果找到匹配项,返回第一个匹配信息的数组,这个数组的第一个元素是匹配整个模式的字符串,其他元素是与表达式中的捕获组匹配的字符串,如果模式中没有捕获组,则数组只包含一个元素。 如果没有找到匹配项,返回null
返回的数组虽然是Array的实例,但包含两个额外的属性:index和input。
- index是字符串中匹配的起始位置。
- input是要查找的字符串
如果模式设置了全局标记,则每次调用exec()方法会返回一个匹配的信息。如果没有设置全局标记,则无论对同一个字符串调用多少次exec(),也只会返回第一个匹配的信息
let text = "cat, bat, sat, fat"
let pattern = /.at/
let matches = pattern.exec(text)
console.log(matches)//['cat', index: 0, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 0
matches = pattern.exec(text)
console.log(matches)//['cat', index: 0, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 0
2
3
4
5
6
7
8
9
10
上面例子中的模式没有设置全局标记,因此调用exec()只返回第一个匹配项("cat"),lastIndex在非全局模式下始终不变。
如果在这个模式上设置了g标记,则每次调用exec()都会在字符串中向前搜索下一个匹配项:
let text = "cat, bat, sat, fat"
let pattern = /.at/g
let matches = pattern.exec(text)
console.log(matches)//['cat', index: 0, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 3
matches = pattern.exec(text)
console.log(matches)//['bat', index: 5, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 8
matches = pattern.exec(text)
console.log(matches)//['sat', index: 10, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 13
matches = pattern.exec(text)
console.log(matches)//['fat', index: 15, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这次模式设置了全局标记,因此每次调用exec()都会返回字符串中的下一个匹配项,直到搜索到字符串末尾。注意模式的lastIndex属性每次都会变化。
在全局匹配模式下,每次调用exec()都会更新lastIndex值,以反应上次匹配的最后一个字符的索引。
如果模式设置了粘附标记y,则每次调用exec()就只会在lastIndex的位置上寻找匹配项。
let text = "cat, bat, sat, fat"
let pattern = /.at/y
let matches = pattern.exec(text)
console.log(matches)//['cat', index: 0, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 3
// 以索引3对应的字符串开头找不到匹配项,因此exec()返回null
// exec() 没找到匹配项,于是将lastIndex设置为0
matches = pattern.exec(text)
console.log(matches)// null
console.log(pattern.lastIndex) // 0
// 向前设置lastIndex可以让沾附的模式通过exec()找到下一个匹配项
pattern.lastIndex = 5
matches = pattern.exec(text)
console.log(matches)// ['bat', index: 5, input: 'cat, bat, sat, fat', groups: undefined]
console.log(pattern.lastIndex) // 8
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# test()
接收一个字符串,如果输入的文本与模式匹配,则参数返回true,否则返回false。这个方法适用于只想测试模式是否匹配,而不需要实际匹配内容的情况。
# 构造函数属性
RegExp构造函数本身也有几个属性。(在其他语言中,这种属性被称为 静态属性)
这些属性适用于作用域中的所有正则表达式,而且会根据最后执行的正则表达式操作而变化。
这些属性还有一个特点,就是可以通过两种不同的方式访问它们,即,每个属性都有一个全名和一个简写:
| 全名 | 简写 | 说明 |
|---|---|---|
| input | $_ | 最后搜索的字符串(非标准特性) |
| lastMatch | $& | 最后匹配的文本 |
| lastParen | $+ | 最后匹配的捕获组(非标准特性) |
| leftContext | $` | input字符串中出现在lastMatch前面的文本 |
| rightContext | $' | input字符串中出现在lastMatch后面的文本 |
| $n | $n | n=1-9,可以最多存储9个捕获组的匹配项,这些属性通过RegExp.$1-RegExp.$9来访问。 |
# 字符串的正则方法
# match()
这个方法本质上跟 RegExp 对象的 exec() 方法相同。这个方法接收一个参数,可以是一个正则表达式字符串,也可以是一个RegExp对象。返回也和exec()方法返回的数组是一样的。
# search()
- 参数:
- 正则表达式字符串 或 RegExp对象
- 返回模式第一个匹配的位置索引,如果没有找到则返回-1。
search()始终从字符串开头向后匹配模式。
# replace()
- 参数:
- 第一个参数可以是一个RegExp对象或一个字符串
- 第二个参数可以是一个字符串或一个函数。
如果第一个参数是字符串,那么只会替换第一个子字符串。
要想替换所有字字符串,第一个参数必须为正则表达式并且带全局标记。
replace()的第二个参数可以是一个函数。
在只有一个匹配项时,这个函数会收到三个参数:
- 与整个模式匹配的字符串。
- 匹配项在字符串中开始的位置。
- 以及整个字符串
在有多个捕获组的情况下,每个匹配捕获组的字符串也会作为参数传给这个函数,但最后两个参数还是与整个模式匹配的开始位置和原始字符串。
这个函数应该返回一个字符串,表示应该把匹配项替换成什么。
# split()
这个方法会根据传入的分隔符将字符串拆分成数组。
参数:
- 作为分隔符的参数可以是字符串,也可以是RegExp对象。(字符串分隔符不会被这个方法当成正则表达式)
- 还可以传入第二个参数,即数组大小,确保返回的数组不会超过指定大小
# 字符
# 单个字符
最简单的正则表达式可以由简单的数字和字母组成,没有特殊的语义,纯粹就是一一对应的关系。如想在“apple”这个单词里找到"a"这个字符,就直接用 /a/ 这个正则就可以了。
有时候我们想去找到 / 字符,但是它在正则中有着特殊的意义该怎么办呢?所以就需要用到转义符 \。
\ 反斜杠表示转义符
转义用于改变字符的含义,用来对某个字符有多种语义时的处理。
如果本来这个字符不是特殊字符,使用转义符号就会让它拥有特殊的含义。我们常常需要匹配一些特殊字符,比如空格,制表符,回车,换行等,而这些就需要我们使用转义符来匹配。
| 匹配区间 | 正则表达式 | 记忆方式 |
|---|---|---|
| 换行符 | \n | new line |
| 换页符 | \f | form feed |
| 回车符 | \r | return |
| 空白符 | \s | space |
| 制表符 | \t | tab |
| 垂直制表符 | \v | vertical tab |
| 回退符 | [\b] | backspace,之所以使用[]符号是避免和\b重复 |
所有元字符必须转义
元字符包括:
( [ { \ ^ $ | ) ] } ? * + .
# 字符组
用[]括起来的字符,表示括号内的任一一个字符,记住是其中一个字符。例如[abc],表示匹配一个字符,它可以是a,b,c之一。
# 范围表示法
字符组里的字符特别多的话,可以使用范围表示法。比如[123456abcdefGHIJKLM],可以写成[1-6a-fG-M]。用连字符-来省略和简写。
Q:因为连字符有特殊用途,那么要匹配"a"、"-"、"z"这三者中任意一个字符,该怎么做呢
A:不能写成[a-z],因为连字符的存在,它表示小写字符中的任何一个字符。可以写成如下的方式:
[-az]或[az-]或[a-z]。即要么放在开头,要么放在结尾,要么转义,总之不会让引擎认为是范围表示法就行了。
# 排除字符组
纵向模糊匹配中,还有一种情形就是,某位字符可以是任何东西,但就不能是“a”、“b”、“c”。
此时就可以用排除字符组(反义字符组)。例如[^abc],表示是一个除“a”、“b、“c”之外的任一一个字符。字符组的第一位放^(脱字符),表示求反的概念。
var reg = /1[^abc]2/g
var string = "1a2 1b2 1c2 1d2 147564872 1da2 1v2"
console.log(string.match(reg))
// ['1d2', '1v2']
2
3
4
当然也可以用连字符排除掉范围
var reg = /1[^a-f]2/g
var string = "1a2 1b2 1c2 1d2 147564872 1da2 1v2 1f2"
string.match(reg)
// ['1v2']
2
3
4
# 常见的简写
| 匹配区间 | 简写 | 正则 | 记忆方式 |
|---|---|---|---|
| 单个数字 | \d | [0-9] | digit |
| 除了[0-9] | \D | [^0-9] | Not digit |
| 包括下划线在内的单个字符 | \w | [a-zA-Z0-9_] | word |
| 非单字字符 | \W | [^0-9a-zA-Z_] | Not word |
| 空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符 | \s | [ \t\v\n\r\f] | space |
| 非空白符 | \S | [^ \t\v\n\r\f] | Not space |
| 除了换行符之外的任何字符 | . |
提示
正则表达式中,点(.)是一个特殊字符,代表任一的单个字符,但是两个例外。
一个是四字节的UTF-16字符,这个可以用u修饰符解决
另一个是行终止符,就是该字符表示一行的终结,以下四个字符属于行终止符
- U+000A 换行符(\n)
- U+000D 回车符(\r)
- U+2028 行分隔符
- U+2029 段分隔符
//因为.不匹配\n,所以正则表达式返回false。
/foo.bar/.test('foo\nbar') // false
2
如果要匹配任意字符怎么办?可以使用[\d\D]、[\w\W]、[\s\S]和[^]中任何的一个。
# 文字
Unicode是一种字符编码标准,用来表示各种语言的字符,使用\u加上四位十六进制数字,表示字符,例如表示汉字的正则是[\u4e00-\u9fa5]
除此之外还有一些常用的字符:
| 匹配范围 | 正则 | unicode |
|---|---|---|
| NULL字符 | \0 | \u0000 |
| 由十六进制数nn指定的拉丁字符,例如\x0A与\u000A相同 | \xnn | |
| 由十六进制数字xxxx指定的Unicode字符;例如,\ u0009与\ t相同 | \uxxxx |
# 量词
| 符号 | 含义 |
|---|---|
| {m,n} | 重复m到n次 |
| {m,} | 至少出现m次 |
| {m} | 表示出现m次 |
| ? | 等价于{0,1},表示出现或者不出现 |
| + | 等价于{1,},表示至少出现一次 |
| * | 等价于{0,},表示出现任意次,可能不出现 |
# 贪婪模式
看如下的例子:
var reg = /\d{2,5}/g
var string = "123 1234 12345 123456"
console.log(string.match(reg))
// ['123', '1234', '12345', '12345']
2
3
4
这个正则表示数字连续出现2-5次,会匹配2位,3位,4位,5位连续数字。
但其实是贪婪的,它会尽可能多的匹配,正则表达式在进行重复匹配时,默认是贪婪模式。
# 惰性模式
但有时候我们并不需要贪婪模式,而惰性匹配,就是尽可能少的匹配, 我们可以通过在量词后加上?来开启惰性匹配
var reg = /\d{2,5}?/g
var string = "123 1234 12345 123456"
console.log(string.match(reg))
// ['12', '12', '34', '12', '34', '12', '34', '56']
2
3
4
这个正则表示,虽然2到5次都行,当2个就够的时候,就不再往下尝试了。
# 独占模式(注意!注意!注意!Javascript不支持独占模式)
如果在表达式后加上一个加号+,则会开启独占模式。如同贪婪模式一样,独占模式一样会匹配最长。
不过在独占模式下,正则表达式尽可能长地去匹配字符串,一旦匹配不成功就会结束匹配而不会回溯。
以下是三种模式的表达式:
| 贪婪 | 懒惰 | 独占 |
|---|---|---|
| X? | X?? | X?+ |
| X* | X*? | X*+ |
| X+ | X+? | X++ |
| X{n} | X{n}? | X{n}+ |
| X{n,} | X{n,}? | X{n,}+ |
| X{n,m} | X{n,m}? | X{n,m}+ |
# 位置匹配
# ^和$
| 匹配内容 | 表达式 |
|---|---|
| 匹配字符串的开始,在多行匹配中匹配行开头 | ^ |
| 匹配字符串的结束,在多行匹配中匹配行结尾 | $ |
比如我们把字符串的开头和结尾用"#"替换:
var result = "hello".replace(/^|$/g,'#')
console.log(result) //'#hello#'
2
多行匹配模式时,二者是行的概念,这个需要我们注意:
var result = "I\nlove\njavascript".replace(/^|$/gm,'#')
console.log(result)
/*
#I#
#love#
#javascript#
*/
2
3
4
5
6
7
# \b和\B
\b 是单词边界,具体就是 \w 和 \W之间的位置,也包括\w和^之间的位置,\w 和 $之间的位置。
比如一个文件名是"[JS] Lesson_01.mp4"中的\b如下:
var result = "[JS] Lesson_01.mp4".replace(/\b/g,'#')
console.log(result) // [#JS#] #Lesson_01#.#mp4#
2
首先,我们知道,\w是字符组[0-9a-zA-Z_]的简写形式,即\w是字母数字或者下划线的中任何一个字符。而\W是排除字符组[^0-9a-zA-Z_]的简写形式,即\W是\w以外的任何一个字符。
此时我们可以看看"[#JS#] #Lesson_01#.#mp4#"中的每一个"#",是怎么来的。
第一个"#",两边是"["与"J",是\W和\w之间的位置。 第二个"#",两边是"S"与"]",也就是\w和\W之间的位置。 第三个"#",两边是空格与"L",也就是\W和\w之间的位置。 第四个"#",两边是"1"与".",也就是\w和\W之间的位置。 第五个"#",两边是"."与"m",也就是\W和\w之间的位置。 第六个"#",其对应的位置是结尾,但其前面的字符"4"是\w,即\w和$之间的位置。 知道了\b的概念后,那么\B也就相对好理解了。\B就是\b的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉\b,剩下的都是\B的。具体说来就是\w与\w、\W与\W、^与\W,\W与$之间的位置。
比如把上面的例子,把所有\B替换成“#”:
var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#')
console.log(result) // #[J#S]# L#e#s#s#o#n#_#0#1.m#p#4
2
单词是构成句子和文章的基本单位,一个常见的使用场景是把文章或句子中的特定单词找出来,如:
var string = "The cat scattered his food all over the room"
我想找到cat这个单词,但是如果只是使用/cat/这个正则,就会同时匹配到 cat 和 scattered 这两处文本。把正则表达式改一下/\bcat\b/这样就能匹配到cat这个单词了。
# (?=p) 和 (?!p)
(?=p),其中p是一个字模式,即p前面的位置。 比如(?=l),表示字符'l'前面的位置:
var result = "hello".replace(/(?=l)/g,'#')
console.log(result) // he#l#lo
2
而(?!p)就是(?=p)的反面意思,比如:
var result = "hello".replace(/(?!l)/g,'#')
console.log(result) //#h#ell#o#
2
# (?<=p) 和 (?<!p)
(?<=p),其中p是一个字模式,即p后面的位置。 比如(?=l),表示字符'l'后面的位置:
var result = "hello".replace(/(?<=l)/g,'#')
console.log(result) // hel#l#o
2
而(?<!p)就是(?<=p)的反面意思,比如:
var result = "hello".replace(/(?<!l)/g,'#')
console.log(result) // #h#e#llo#
2
# 分组和分支
更加高级的用法就得用到子表达式了,通过嵌套递归和自身引用可以让正则发挥更强大的功能。
从简单到复杂的正则表达式演变通常要采用分组、回溯引用和逻辑处理的思想。利用这三种规则可以推演出无限复杂的正则表达式。
补充阅读
# 正则表达式引擎
之前我写webpack插件的时候写正则表达式让这个插件执行时间长达40多秒,一度让我怀疑人生,查过之后才发现是正则回溯陷阱。
说起回溯陷阱,要先从正则表达式的引擎说起。正则引擎主要可以分为基本不同的两大类:
- DFA 确定型有穷自动机 DFA对应的事文本主导的匹配,从左到右,每个字符不会匹配量词,它的时间复杂度是多项式的,所以通常情况下,它的速度更快,但支持的特效很少,不支持捕获组还有各种引用等。
- NFA 不确定型有穷自动机 NFA则是从正则表达式入手,不断读入字符,尝试是否匹配当前正则,不匹配则吐出字符重新尝试,通常它的速度比较慢,最优时间复杂度为多项式的,最差情况为指数级的。但NFA支持更多的特性。
var reg = /to(nite|nighta|night)/g
var text = "after tonight"
2
上面的正则表达式在NFA匹配的时候,是根据正则表达式来匹配文本的,过程如下:
- 正则表达式第一个字符是 t,因为匹配文本中的第一个字符a, 失败继续往下
- t 匹配 文本中第二个字符 f ,失败继续往下
- t 匹配到了文本中的第三个字符 t,于是正则的第二个字符是 o ,匹配文本第四个字符e, 失败,正则回退到t,继续往下
- t 匹配到文本第7个字符 t, 然后 正则中的 o 也和文本第8个字符匹配, 继续往下
- 正则表达式后面有三个可选条件,依次匹配,一个是 nite,失败,第二个是 nighta,也失败,第三个成功
而DFA匹配的时候,采用的是用文本来匹配正则表达式的方式,过程如下:
- 从文本第一个字符a开始匹配正则的t,失败继续往下
- 匹配到文本第一个t,但e和正则中的o匹配失败,继续往下
- 文本的第二个t匹配到正则的t,紧接着o也和正则的o匹配
- 紧接着n匹配的时候发现正则里有三个可选匹配,文本中的g使第一个可选条件不匹配,继续匹配第二个,不匹配,继续匹配第三个,成功
可以看到DFA匹配过程中文本中的字符每个只比较了一次,没有吐出的操作,是快于NFA的。
# 正则回溯
说完了引擎,我们再来看看到底什么是回溯,对于下面这个表达式
var reg = /ab{1,3}c/
对于文本“abbbc”,按照NFA引擎的匹配规则,其实是没有发生回溯的,在表达式a匹配完成后,b恰好和文本中的3个b完整匹配,之后是c匹配,一气呵成。
但对于文本“abc”,无非就是少了两个字母b,却发生了回溯,匹配过程如下图所示(橙色为匹配,黄色为不匹配)。
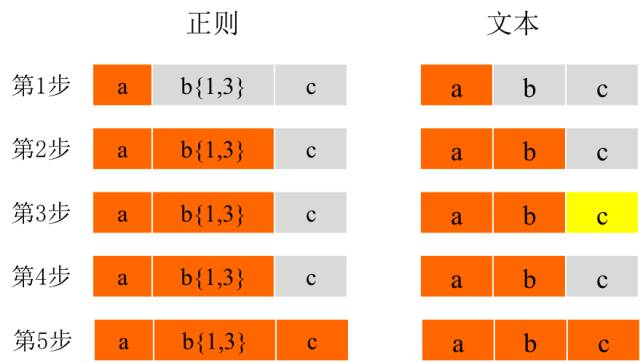 为什么会发生回溯,这就是因为正则的贪婪特性,也就是说b{1,3}会竭尽所能的匹配最多的字符串。在第三步发生不匹配后,整个匹配流程并没有走完,而是像栈一样,将字符c吐出来,然后去用正则表达式中的c去和文本中的c进行匹配。这样就发生了一次回溯。
为什么会发生回溯,这就是因为正则的贪婪特性,也就是说b{1,3}会竭尽所能的匹配最多的字符串。在第三步发生不匹配后,整个匹配流程并没有走完,而是像栈一样,将字符c吐出来,然后去用正则表达式中的c去和文本中的c进行匹配。这样就发生了一次回溯。
而在懒惰模式下,正则引擎尽可能少的重复匹配字符,匹配成功之后它会继续匹配剩余的字符串
var reg = /ab{1,3}?c/
则匹配过程变成了下面这样:

而独占模式下,同贪婪模式一样,独占模式一样会匹配最长。不过在独占模式下,正则表达式尽可能长地去匹配字符串,一旦匹配不成功就会结束匹配而不会回溯。我们以下面的表达式为例,
var reg = /ab{1,3}+bc/
如果我们用文本"abbc"去匹配上面的表达式,匹配的过程如下图所示
 可以发现,在第2和第3步,b{1,3}+会将文本中的2个字母b都匹配上,结果文本中只剩下一个字母c。那么在第4步时,正则中的b和文本中的c进行匹配,当无法匹配时,并不进行回溯,这时候整个文本就无法和正则表达式发生匹配。如果将正则表达式中的加号(+)去掉,那么这个文本整体就是匹配的了。
可以发现,在第2和第3步,b{1,3}+会将文本中的2个字母b都匹配上,结果文本中只剩下一个字母c。那么在第4步时,正则中的b和文本中的c进行匹配,当无法匹配时,并不进行回溯,这时候整个文本就无法和正则表达式发生匹配。如果将正则表达式中的加号(+)去掉,那么这个文本整体就是匹配的了。
# 分组
我们知道/a+/匹配连续出现的 a ,而需要匹配连续出现的 “ab”时,需要使用/(ab)+/。
其中括号提供的是分组功能,能使量词 + 作用于括号内的整体:
var reg = /(ab)+/g
var string = "ababab abbb ababa"
console.log(string.match(reg))
// ['ababab', 'ab', 'abab']
2
3
4
# 分支结构
而在多选分支结构(p1|p2)中,此处括号的作用也是不言而喻的,提供了子表达式的所有可能。
比如要匹配如下的字符串:
// I love JavaScript
// I love Regular Expression
var reg = /^I love (JavaScript|Regular Expression)$/
console.log(reg.test("I love JavaScript")) // true
console.log(reg.test("I love Regular Expression")) //true
2
3
4
5
6
# 引用分组
这是括号一个重要的作用,有了它,我们就可以进行数据提取,以及更强大的替换操作。
以日期为例。假设格式是yyyy-mm-dd的,我们可以先写一个简单的正则:
var reg = /\d{4}-\d{2}|-\d{2}/
然后再修改成括号版的:
var reg = /(\d{4})-(\d{2})-(\d{2})/
接下来就看一下为什么要加括号:
# 提取数据
比如提取出年、月、日,可以这么做:
var reg = /(\d{4})-(\d{2})-(\d{2})/
var string = "2024-03-06"
console.log(string.match(reg))
// ['2024-03-06', '2024', '03', '06', index: 0, input: '2024-03-06', groups: undefined]
2
3
4
match返回的一个数组:
- 第一个元素是整体匹配的结果
- 然后是各个分组(括号里)匹配的内容
- 然后是匹配下标index
- 然后是输入文本 input
- 最后是groups,命名分组,这个后面会讲到
另外也可以使用正则对象的 exec 方法:
var reg = /(\d{4})-(\d{2})-(\d{2})/
var string = "2024-03-06"
console.log(reg.exec(string))
// ['2024-03-06', '2024', '03', '06', index: 0, input: '2024-03-06', groups: undefined]
2
3
4
也可以使用构造函数的全局属性 $1 至 $9来获取:
var reg = /(\d{4})-(\d{2})-(\d{2})/
var string = "2024-03-06"
reg.test(string)
// reg.exex(string) 也可以
// string.match(reg) 也可以
console.log(RegExp.$1)
console.log(RegExp.$2)
console.log(RegExp.$3)
2
3
4
5
6
7
8
# 替换
比如,想把yyyy-mm-dd格式,替换成mm/dd/yyyy怎么做?
var reg = /(\d{4})-(\d{2})-(\d{2})/
var string = "2024-03-06"
var result = string.replace(reg, "$2/$3/$1")
console.log(result) // 03/06/2024
2
3
4
其中,replace中的第二个参数里用 $1,$2,$3指代相应的分组。等价如下形式:
var reg = /(\d{4})-(\d{2})-(\d{2})/
var string = "2024-03-06"
var result = string.replace(reg, function() {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1
})
console.log(result) // 03/06/2024
2
3
4
5
6
替换字符串可以插入下面的特殊变量名:
| 变量 | 说明 |
|---|---|
| $$ | 插入一个$ |
| $& | 插入匹配的完整结果 |
| $` | 插入当前匹配的字符串左边的内容 |
| $' | 插入当前匹配的子串右边的内容 |
| $n | 插入第n个括号匹配的分组的内容,索引从1开始 |
测试如下:
var reg = /刀刀/
var string = "#刀刀¥"
var result = string.replace(reg, "$$$`$`$`$&$'$'$'")
// 看这个替换的字符串,终于癫成了我想要的样子
console.log(result) //#$###刀刀¥¥¥¥
2
3
4
5
# 反向引用
除了使用相应API来引用分组,也可以在正则本身里引用分组。但只能引用之前出现的分组,即反向引用。
还是以日期为例,比如要写一个正则支持匹配如下三种格式:
- 2024-03-06
- 2024/03/06
- 2024.03.06 最先想到的可能是:
var reg = /\d{4}(-|\/|\.)\d{2}(-|\/|\.)\d{2}/
var string1 = "2024-03-06"
var string2 = "2024/03/06"
var string3 = "2024.03.06"
var string4 = "2024-03/06"
console.log(reg.test(string1)) // true
console.log(reg.test(string2)) // true
console.log(reg.test(string3)) // true
console.log(reg.test(string4)) // true
2
3
4
5
6
7
8
9
10
其中 / 和 . 需要转义。虽然匹配了要求的情况,但也匹配“2024-03/06”这样的数据。
但是我们要的事分隔符前后一致,此时就需要使用反向引用:
var reg = /\d{4}(-|\/|\.)\d{2}\1\d{2}/
var string1 = "2024-03-06"
var string2 = "2024/03/06"
var string3 = "2024.03.06"
var string4 = "2024-03/06"
console.log(reg.test(string1)) // true
console.log(reg.test(string2)) // true
console.log(reg.test(string3)) // true
console.log(reg.test(string4)) // false
2
3
4
5
6
7
8
9
注意里面的 \1,表示引用之前的那个分组(-|\/|\.)。不管它匹配到什么,\1都匹配那个同样的具体某个字符。
\2 和 \3也就能理解了,分别指代第二个和第三个分组。
括号嵌套怎么办
以左括号( 为准:
var reg = /^((\d)(\d(\d)))\1\2\3\4$/
var string = "1231231233"
console.log(reg.test(string)) // true
console.log(RegExp.$1) //123
console.log(RegExp.$2) // 1
console.log(RegExp.$3) // 23
console.log(RegExp.$4) // 3
2
3
4
5
6
7
\10表示什么呢
\10是表示第10个分组,还是\1和0呢?答案是第10个分组。
虽然正则里出现 \10 比较罕见:
var reg = /(1)(2)(3)(4)(5)(6)(7)(8)(9)(#) \10+/
var string = "123456789# #######"
console.log(reg.test(string)) // true
2
3
引用不存在的分组会怎样?
因为反向引用,是引用前面的分组,但我们在正则里引用了不存在的分组时,此时正则不会报错,只是匹配反向引用的字符本身。例如 \2 ,就匹配 \2,注意 \2是对2进行转义。(关于转义,又是新的话题了,以后再讲,只需要知道\1-\7是有别的含义的转义字符)
var reg = /\1\2\3\4\5\6\7\8\9/
console.log(reg.exec("\1\2\3\4\5\6\7\8\9"))
console.log("\1\2\3\4\5\6\7\8\9".split(""))
//['\x01\x02\x03\x04\x05\x06\x0789', index: 0, input: '\x01\x02\x03\x04\x05\x06\x0789', groups: undefined]
//['\x01', '\x02', '\x03', '\x04', '\x05', '\x06', '\x07', '8', '9']
2
3
4
5
# 非捕获分组
之前文中出现的分组,都会捕获他们匹配到的数据,以便后续引用,因此也称他们是捕获型分组。
如果只想要括号最原始的功能,但不会引用它,即,即不存在API里面,也不在正则里反向引用。此时可以使用非捕获分组(?:p),这样可以避免浪费内存:
var reg = /(\d{4})-(?:\d{2})-(\d{2})/
var string = "2024-03-06"
console.log(reg.exec(string)) // ['2024-03-06', '2024', '06', index: 0, input: '2024-03-06', groups: undefined]
console.log(RegExp.$1) // 2024
console.log(RegExp.$2) // 06
console.log(RegExp.$3) // 空的,没有
2
3
4
5
6
如果是嵌套分组非捕获呢,不会记录当前分组,子组不影响,该记录还是记录
var reg = /(?:1(2)(?:3))(4)(?:5(6))/
var string = "123456"
console.log(reg.exec(string)) // ['123456', '2', '4', '6', index: 0, input: '123456', groups: undefined]
console.log(RegExp.$1) // 2
console.log(RegExp.$2) // 4
console.log(RegExp.$3) // 6
console.log(RegExp.$4)
console.log(RegExp.$5)
console.log(RegExp.$6)
2
3
4
5
6
7
8
9
# 分组别名
如果希望返回的组数据更清晰,可以给分组编号,将结果保存在返回的group字段中
使用?<cont>起分组别名
使用$<cont>读取别名
var reg = /<(?<tag>h[1-6])[\s\S]*<\/\1>/
var string = "<h1> 你怎么这么优秀!</h1>"
console.log(reg.exec(string))
/*
[
"<h1> 你怎么这么优秀!</h1>",
"h1",
groups:{
tag:"h1"
},
index:0,
input:"<h1> 你怎么这么优秀!</h1>"
]
*/
2
3
4
5
6
7
8
9
10
11
12
13
14
# 断言匹配
有时,我们需要限制适用范围,可以通过断言匹配达到这个目的。
断言虽然卸载括号中,但它不是组,所以不会在匹配结果中保存,可以将断言理解为正则中的条件。
注意
断言用来声明一个应该为真的事实。正则表达式中只有断言为真时才会继续进行匹配。
# 零宽先行断言(先行断言)
(?=exp)正向肯定查找,比如x只有在y前面才匹配,写成/x(?=y)/
// 把张三女士的名字用括号括起来
var string = "张三先生和张三女士"
var reg = /张三(?=女士)/g
var result = string.replace(reg,"($&)")
console.log(result)
// 张三先生和(张三)女士
2
3
4
5
6
# 零宽后行断言(后行断言)
(?<exp)反向肯定查找。和先行断言相反,x 只有在y后面才匹配,写作/(?<=y)x/
// 找出李四今天花了多少钱
var string = "张三:100,李四:250"
var reg = /(?<=李四:)\d+/
var result = string.match(reg)
console.log(result)
// ['250', index: 10, input: '张三:100,李四:250', groups: undefined]
2
3
4
5
6
// 获取标题中的内容
var string = "<h1>给刀刀点个赞吧</h1>"
var reg = /(?<=<h1>).*(?=<\/h1>)/g
console.log(string.match(reg))
// ['给刀刀点个赞吧']
2
3
4
5
# 零宽负向先行断言(先行否定断言)
(?!exp)正向否定查找,比如: x只有不在y前面在匹配,写成/x(?!y)/
// 把非女士的张三名字用括号括起来
var string = "张三先生和张三女士和张三人妖"
var reg = /张三(?!女士)/g
var result = string.replace(reg,"($&)")
console.log(result)
// (张三)先生和张三女士和(张三)人妖
2
3
4
5
6
# 零宽负向后行断言(后行否定断言)
(?<!exp)反向否定查找,x只有不在y后面才匹配,必须写成/(?<!y)x/
// 找出除了李四别人今天花了多少钱
var string = "张三:100,李四:250,王五:150,老六:400"
var reg = /(([^\d,])+?:(?<!李四:)\d+)/g
var result = string.match(reg)
console.log(result)
// ['张三:100', '王五:150', '老六:400']
2
3
4
5
6
参考文献: