
LangChain多任务应用开发
# LangChain基本概念
- 提供了一套工具、组件和接口
- 简化了创建LLM应用的过程
LangChain是由多个组件组成的:
- Models:模型,比如GPT-4o
- Prompts:提示,包括提示管理、提示优化和提示序列化
- Memory:记忆,用来保存和模型交互时的上下文
- Indexes:索引,用于结构化文档,方便和模型交互如果要构建自己的知识库,就需要各种类型文档的加载,转换,长文本切割,文本向量计算,向量索引存储查询等
- Chains:链,一系列对各种组件的调用
- Agents:代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi # 导入通义千问Tongyi模型
import dashscope
# 从环境变量获取 dashscope 的 API Key
api_key = "sk-cd87191136be484d92f1ac53551440f1"
dashscope.api_key = api_key
# 加载 Tongyi 模型
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=api_key) # 使用通义千问qwen-turbo模型
# 创建Prompt Template
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
# 新推荐用法:将 prompt 和 llm 组合成一个"可运行序列"
chain = prompt | llm
# 使用 invoke 方法传入输入
result1 = chain.invoke({"product": "colorful socks"})
print(result1)
result2 = chain.invoke({"product": "广告设计"})
print(result2)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
提示
PromptTemplate是LangChain的提示词模板类。
chain = prompt | llm,可以直接将prompt的输出作为llm的输入,形成一个可运行的链式结构,简化了原先LLMChain的写法。
# LangChain与LangGraph区别
架构差异:
- LangChain是线性结构(A→B→C→D)
- LangGraph是图结构(支持多路径如A→B/C/E)
能力对比:
- LangGraph ≥ LangChain
L- angGraph适合更复杂的任务流
版本关系:LangGraph是LangChain的升级版,同属一个技术体系
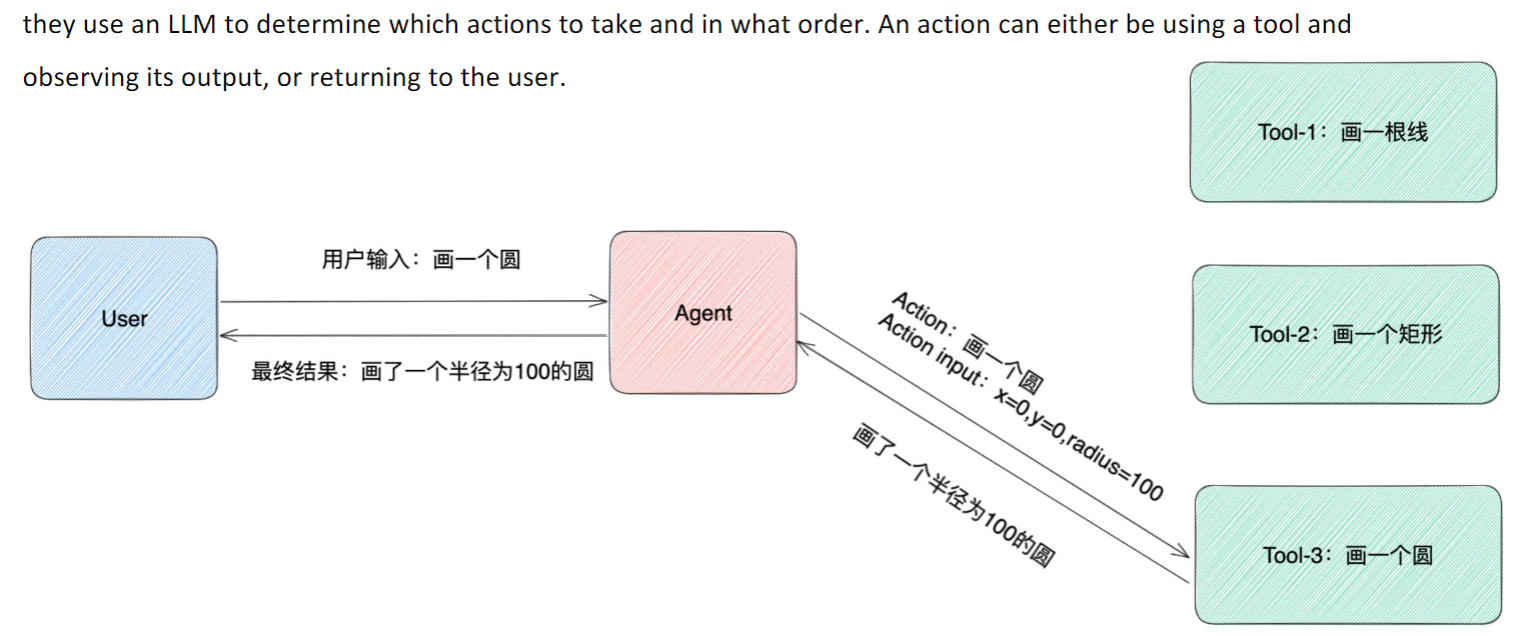
# Agent的作用
LangChain官方文档中对Agent的定义:
they use an LLM to determine which actions to take and in what order. An action can either be using a tool and
observing itsoutput, orreturning to the user.
使用LLM来决定采取哪些行动以及以什么顺序采取行动。操作可以使用工具并观察其输出,也可以返回给用户。
# Memory
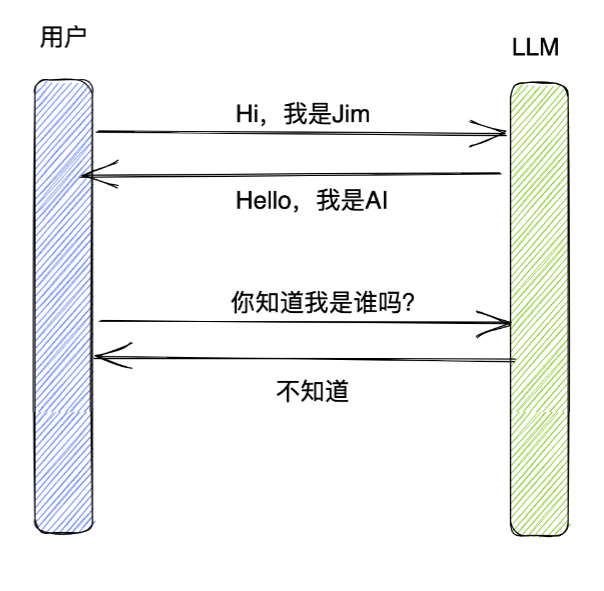
- Chains和Agent之前是无状态的,如果你想让他能记住之前的交互,就需要引入内存
- 可以让LLM拥有短期记忆
对话过程中,记住用户的input和 中间的output
如果没有记忆,我们和AI的对话就会变成这样:
在LangChain中提供了几种短期记忆的方式:
BufferMemory
将之前的对话完全存储下来,传给LLMBufferWindowMemory
最近的K组对话存储下来,传给LLMConversionMemory对对话进行摘要,将摘要存储在内存中,相当于将压缩过的历史对话传递给LLMVectorStore-backed Memory
将之前所有对话通过向量存储到VectorDB(向量数据库)中,每次对话,会根据用户的输入信息,匹配向量数据库中最相似的K组对话
现在LangChain更推荐这种方式来实现历史对话
# # 第1行:导入通义千问的聊天模型类
from langchain_community.chat_models.tongyi import ChatTongyi
# # 第2行:导入创建提示词模板的工具
# ChatPromptTemplate:用于创建聊天对话的提示词模板
# MessagesPlaceholder:一个特殊的占位符,用于在提示词中插入对话历史消息
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 第3行:导入RunnableWithMessageHistory工具
# 作用:自动管理对话历史的包装器
# 它会自动保存每次对话到历史,并在下次对话时自动加载历史
from langchain_core.runnables.history import RunnableWithMessageHistory
# 第4行:导入消息历史存储的类
# InMemoryChatMessageHistory:在内存中存储对话历史(重启程序后丢失)
# BaseChatMessageHistory:消息历史的基础接口,用于类型提示
from langchain_core.chat_history import InMemoryChatMessageHistory, BaseChatMessageHistory
import dashscope
api_key = "sk-cd87191136be484d92f1ac53551440f1"
dashscope.api_key = api_key
llm = ChatTongyi(model_name="qwen-turbo", dashscope_api_key=api_key) # 使用通义千问qwen-turbo模型
# 2. 创建提示词模板(和 OpenAI 完全一样)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有用的助手"),
MessagesPlaceholder(variable_name="history"), # 历史占位符
("human", "{input}")
])
# 3. 构建链
chain = prompt | llm
# 4. 创建历史存储
store = {}
# 作用:根据session_id获取对应的对话历史
# session_id:会话标识符,用于区分不同用户
# 参数说明:
# - "user123":表示用户A的会话
# - "user456":提示用户B的会话
# 返回值:BaseChatMessageHistory对象,包含该用户的所有对话历史
def get_session_history(session_id):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 5. 包装自动管理历史
# 创建带历史管理的对话链
# 总结:RunnableWithMessageHistory会自动完成以下工作:
# 1. 从get_session_history(session_id)加载历史
# 2. 将历史插入到提示词模板的{history}位置
# 3. 将用户的{input}插入到模板
# 4. 调用基础链(prompt | llm)生成回复
# 5. 将用户输入和AI回复保存到历史
with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input", # 指定输入消息的key
history_messages_key="history" # 指定历史消息的key
)
# 6. 测试对话
config = {"configurable": {"session_id": "user123"}}
# 对话1
response1 = with_history.invoke(
{"input": "我叫张三"},
config=config
)
print(f"AI: {response1.content}")
# 对话2
response2 = with_history.invoke(
{"input": "我叫什么名字?"},
config=config
)
print(f"AI: {response2.content}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# Case:动手搭建本地知识智能客服
详细可以参看例子tesla_agent完全解析
# 总结
- Agent的核心是把LLM当作推理引擎,让它能使用外部工具,以及自己的长期记忆,从而完成灵活的决策步骤,进行复杂任务
- LangChain里的Chain的概念,是由人来定义的一套流程步骤来让LLM执行,可以看成是把LLM当成了一个强大的多任务工具
典型的Agent逻辑(比如ReAct):
- 由LLM选择工具。
- 执行工具后,将输出结果返回给LLM
- 不断重复上述过程,直到达到停止条件,通常是LLM自己认为找到答案了
# LangChain 任务链构建指南
# 一、什么是任务链?
任务链是将多个步骤按顺序连接起来,前一个步骤的输出作为后一个步骤的输入。
类比:
任务链 = 工厂流水线
步骤 1:原材料 → 加工 → 半成品
步骤 2:半成品 → 组装 → 成品
步骤 3:成品 → 包装 → 最终产品
每个步骤的输出是下一个步骤的输入
2
3
4
5
6
7
实际例子:
用户输入:"一篇关于 AI 的文章"
任务链:
1. 提取关键信息 → ["AI", "人工智能", "机器学习"]
2. 生成提纲 → 标题 + 3 个章节
3. 撰写内容 → 完整文章
4. 润色修改 → 最终版本
2
3
4
5
6
7
# LCEL 链(最推荐)
使用 LangChain Expression Language 构建的链
示例:
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models import ChatTongyi
# 1. 定义 Prompt
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的翻译家"),
("user", "将以下内容翻译成中文:{text}")
])
# 2. 定义模型
model = ChatTongyi(model="qwen-turbo", dashscope_api_key=api_key)
# 3. 定义输出解析器
output_parser = StrOutputParser()
# 4. 构建链(使用 | 操作符)
chain = prompt | model | output_parser
# 5. 调用链
result = chain.invoke({"text": "Hello, World!"})
print(result) # 你好,世界!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# LCEL 链详解(重点)
- 基本语法
# 使用 | 操作符连接组件
chain = component1 | component2 | component3
# 等价于:
output1 = component1.invoke(input)
output2 = component2.invoke(output1)
output3 = component3.invoke(output2)
2
3
4
5
6
7
- 可用的组件类型
# Prompt 模板
prompt = ChatPromptTemplate.from_template("翻译:{text}")
# LLM 模型
model = ChatTongyi(...)
# 输出解析器
output_parser = StrOutputParser()
# 可运行函数
def custom_func(text):
return text.upper()
# 组合成链
chain = prompt | model | output_parser | custom_func
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 完整示例:文章生成链
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models import ChatTongyi
# 执行自定义的小函数(比如清理文本)
from langchain_core.runnables import RunnableLambda
# 初始化模型
model = ChatTongyi(
model="qwen-turbo",
dashscope_api_key="your-api-key"
)
# 步骤 1:分析主题
analyze_prompt = ChatPromptTemplate.from_template("""
分析以下主题,输出主题的关键要点:
主题:{topic}
输出格式:要点1、要点2、要点3
""")
# 步骤 2:生成提纲
outline_prompt = ChatPromptTemplate.from_template("""
基于以下关键要点生成文章提纲:
关键要点:{key_points}
提纲格式:
标题:
1. 章节1
- 子要点
2. 章节2
- 子要点
3. 章节3
- 子要点
""")
# 步骤 3:撰写文章
write_prompt = ChatPromptTemplate.from_template("""
根据提纲撰写完整的文章:
提纲:{outline}
要求:
- 内容详实
- 逻辑清晰
- 语言流畅
""")
# 步骤 4:自定义处理函数(去除多余空行)
def clean_text(text):
import re
return re.sub(r'\n\s*\n', '\n\n', text.strip())
# 构建链
chain = (
# {"key_points": ...} 是一种“给中间结果起名字”的方法,让后续步骤能准确知道“该用哪一部分数据”。
{"key_points": analyze_prompt | model | StrOutputParser()} # 步骤 1
| outline_prompt # 步骤 2(接收 key_points)
| model
| StrOutputParser()
| write_prompt # 步骤 3(接收 outline)
| model
| StrOutputParser()
# RunnableLambda(clean_text) 的意思是:“现在请运行我写的 clean_text 函数,处理刚才的文章。
| RunnableLambda(clean_text) # 步骤 4(清理文本)
)
# 执行链
result = chain.invoke({"topic": "人工智能在教育中的应用"})
print(result)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
- 带分支的链
# LangChain 提供的一个“条件分支工具”
from langchain_core.runnables import RunnableBranch
# 定义条件分支
branch = RunnableBranch(
# 条件 1:如果输入包含 "代码"
(lambda x: "代码" in x.get("topic", ""),
ChatPromptTemplate.from_template("编写代码示例:{topic}") | model),
# 条件 2:如果输入包含 "解释"
(lambda x: "解释" in x.get("topic", ""),
ChatPromptTemplate.from_template("解释概念:{topic}") | model),
# 默认情况
ChatPromptTemplate.from_template("讨论主题:{topic}") | model
)
# 使用分支
chain = {"topic": (lambda x: x["question"])} | branch | StrOutputParser()
result1 = chain.invoke({"question": "Python 代码示例"})
result2 = chain.invoke({"question": "解释什么是 AI"})
result3 = chain.invoke({"question": "未来的趋势"})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- 并行链
from langchain_core.runnables import RunnableParallel
# 并行执行多个任务
parallel_chain = RunnableParallel({
"summary": ChatPromptTemplate.from_template("总结:{text}") | model,
"keywords": ChatPromptTemplate.from_template("提取关键词:{text}") | model,
"translation": ChatPromptTemplate.from_template("翻译成英文:{text}") | model,
})
result = parallel_chain.invoke({
"text": "人工智能正在改变世界"
})
# 结果包含三个键
print(result["summary"]) # 总结
print(result["keywords"]) # 关键词
print(result["translation"]) # 翻译
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 任务链的高级特性
- 链的调试
from langchain_core.runnables import RunnableConfig
# 启用调试模式
config = RunnableConfig(
callbacks=[{
"on_llm_start": print("开始调用 LLM"),
"on_llm_end": print("LLM 调用完成"),
"on_chain_start": print("开始执行链"),
"on_chain_end": print("链执行完成")
}]
)
result = chain.invoke({"topic": "AI 教育"}, config=config)
2
3
4
5
6
7
8
9
10
11
12
13
- 链的流式输出
# 流式输出
for chunk in chain.stream({"topic": "AI 教育"}):
print(chunk, end="", flush=True)
2
3
- 链的批处理
# 批量处理多个输入
results = chain.batch([
{"topic": "AI 教育"},
{"topic": "AI 医疗"},
{"topic": "AI 金融"}
])
for result in results:
print(result)
2
3
4
5
6
7
8
9
# AI Agent对比
| 工具 | 核心定位 | 架构特点 | 适用场景 |
|---|---|---|---|
| LangChain | 开源LLM应用开发框架 | 基于链(Chain)的线性或分支工作流,支持Agent模式 | 快速构建RAG、对话系统、工具调用等线性任务 |
| LangGraph | LangChain的扩展,专注于复杂工作流 | 基于图(Graph)的循环和条件逻辑,支持多Agent协作 | 需要循环、动态分支或状态管理的复杂任务(如自适应RAG、多Agent系统) |
| Qwen-Agent | 通义千问的AI Agent框架基于阿里云大模型,支持多模态交互与工具调用 | 开源,集成多种工具,MCP调用 | |
| Coze | 字节跳动的无代码AI Bot平台 | 可视化拖拽界面,内置知识库、多模态插件 | 快速部署社交平台机器人、轻量级工作流 |
| Dify | 开源LLM应用开发平台 | API优先,支持Prompt工程与灵活编排 | 开发者定制化LLM应用,需深度集成或私有 |
- 工作流编排
- LangChain:线性链,适合固定流程任务(如文档问答)。
- LangGraph:支持循环、条件边和状态传递,适合动态调整的复杂逻辑(如多轮决策)。
- Coze:可视化工作流,支持嵌套和批处理,但灵活性较低。
- Dify:基于自然语言定义工作流,适合API集成和Prompt调优。
- 工具调用与扩展性
- LangChain/LangGraph:工具作为链或图的节点,支持自定义工具和重试逻辑。
- Coze:依赖预置插件生态,扩展需通过开放平台。
- Dify:支持OpenAPI集成,适合技术栈复杂的场景。
- RAG(检索增强生成)
- LangChain:开箱即用的文档加载、向量检索功能。
- LangGraph:需手动设计RAG节点,但支持反馈循环优化检索质量。
- Dify/Coze:Dify提供基础RAG支持,Coze依赖知识库管理。
- 多模态与部署
- Coze:支持图像、视频生成,可直接发布至社交平台。
- Qwen-Agent:开源架构,支持三级索引,以及工具调用,MCP协议调用,使用方便。
- Dify:专注私有化部署,适合企业内网。
AI Agent选择建议:
- 无代码开发:Coze
- 快速原型开发:LangChain(线性任务)或Qwen-Agent。
- 复杂Agent系统:LangGraph(多Agent协作)或Dify(API深度集成)。
- 企业私有化:Dify(开源部署),Qwen-Agent或LangChain+LangGraph(灵活组合)