
DeepSeek使用与prompt工程
# DeepSeek的创新
# DeepSeek-V3模型
DeepSeek-V3在推理速度上相较历史模型有了大幅提升。在目前大模型主流榜单中,DeepSeek-V3在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。
- 性能突破: 推理速度大幅提升,训练成本显著降低
- 价格优势: 率先降价99%,引发行业价格战
- 能力表现: 在主流榜单中与顶级闭源模型不相上下
- 成本控制: 模型训练仅花费600万美金,是同类产品的1/10
# Deepseek-R1
技术突破: 采用GRPO(Group Relative Policy Optimization)奖励机制引入规则类验证机制自动评分基于V3仅用1个多月完成训练
性能表现: 32B参数版本对标OpenAI o1-mini在AIME 2024、Codeforces等基准测试中与OpenAI o1不相上下,推理链长度和深度思考能力显著提升
开源协议:
采用MIT License,允许自由使用、修改、分发和商业化,相比Meta Llama协议更宽松(Llama要求衍生模型保留标识)API特性: DeepSeek-R1上线API,对用户开放思维链输出,通过设置model='deepseek-reasoner'即可调用
市场影响:
2025年1月20日发布后引发科技股震荡
1月27日美股科技板块单日暴跌17%
总市值蒸发超万亿美元行业反应:
多家企业宣布集成DeepSeek技术
推动开源大模型商业化进程协议对比:
Llama3:要求衍生模型保留"Llama"标识
DeepSeek-R1:无使用限制,支持完全商业化部署优势:
规避法务风险
支持企业级私有化部署应用场景:
百度、元宝、豆包等平台集成
支持本地化部署技术特点:
保持高性能同时降低使用门槛
真正实现"强大、开源、便宜"三位一体技术路线:
基于671B主模型蒸馏多个小模型
采用"教师-学生"知识迁移模式关键成果:
32B/70B模型多项指标超越o1-mini
DeepSeek-R1-Distill-Qwen-32B达到94.3% MATH-500通过率
DeepSeek-R1-Distil-Llama-70B获得65.2% GPQA通过率
# DeepSeek的创新:MLA
- MLA(Multi-Head Latent Attention)
在“All you need is attention”的背景下,传统的多头注意力(MHA,Multi-Head Attention)的键值(KV)缓存机制事实上对计算效率形成了较大阻碍。
缩小KV缓存(KV Cache)大小,并提高性能,在之前的模型架构中并未很好的解决。
DeepSeek引入了MLA,一种通过低秩键值联合压缩的注意力机制,在显著减小KV缓存的同时提高计算效率。
低秩近似是快速矩阵计算的常用方法,在MLA之前很少用于大模型计算。从大模型架构的演进情况来看,Prefill和KV Cache容量瓶颈的问题正一步步被新的模型架构攻克,巨大的KV Cache正逐渐成为历史。(实际上在2024年6月发布的DeepSeek-V2就已经很好的降低了KV Cache的大小)
实现原理:
采用低秩近似方法进行键值压缩
仅需5%的存储空间即可保留98%的有效信息
类比图片压缩:原图4M压缩为200K(二十分之一)仍保持可用质量性能优势:
推理成本降低95%
在DeepSeek-V2(2024年6月)中已实现KV Cache的大幅优化
# DeepSeek的创新:DeepSeek-MoE
V3使用了61个MoE(Mix of Expert混合专家) block,虽然总参数量很大,但每次训练或推理时只激活了很少链路,训练成本大大降低,推理速度显著提高。
MoE类比为医院的分诊台,在过去所有病人都要找全科医生,效率很低。但是MoE模型相当于有一个分诊台,将病人分配到不同的专科医生那里。DeepSeek在这方面也有创新,之前分诊是完全没有医学知识的保安,而现在用的是有医学知识的本科生来处理分流任务
基本架构: V3版本使用61个MoE(Mix of Expert) block 总参数量480B,实际激活参数量仅35B(约7.3%) 类比医院分诊系统:由router(路由)分配问题给特定专家
创新点: 分诊机制升级:从"无医学知识的保安"变为"有医学知识的本科生" 采用两层神经网络专门训练router模块
性能优势: 训练成本降低约93% 推理速度显著提升 典型案例:通义千问3-Coder-480B实际激活35B参数
# DeepSeek的创新:混合精度框架
核心思想:根据不同模块需求动态调整数据精度
实现方式:
关键位置使用FP32全精度
非关键模块采用FP8低精度
需要时自动升级精度(FP8→BF16→FP32)性能优势: 显著降低训练计算量
保持模型质量的同时优化资源使用补充创新: 多token预测:批量生成token而非逐字生成
整体设计哲学:用5%成本实现98分质量
为什么DeepSeek计算速度快,成本低?
架构设计方面
DeepSeekMoE架构:在推理时仅激活部分专家,避免了激活所有参数带来的计算资源浪费。
MLA架构:MLA通过降秩KV矩阵,减少了显存消耗。训练策略方面 多token预测(MTP)目标:在训练过程中采用多token预测目标,即在每个位置上预测多个未来token,增加了训练信号的密度,提高了数据效率。
混合精度训练框架:在训练中,对于占据大量计算量的通用矩阵乘法(GEMM)操作,采用FP8精度执行。同时,通过细粒度量化策略和高精度累积过程,解决了低精度训练中出现的量化误差问题
为什么DeepSeek-R1的推理能力强大?
强化学习驱动:DeepSeek-R1通过大规模强化学习技术显著提升了推理能力。在数学、代码和自然语言推理等任务上表现出色,性能与OpenAI的o1正式版相当。
长链推理(CoT)技术:DeepSeek-R1采用长链推理技术,其思维链长度可达数万字,能够逐步分解复杂问题,通过多步骤的逻辑推理来解决问题强化学习的作用:训练大模型,结合少量SFT,引入少量高质量监督数据(如数千个CoT示例)进行微调,提升模型初始推理能力,再通过RL进一步优化,最终达到与OpenAI o1相当的性能长链推理CoT:CoT让AI模型逐步分解复杂问题,比如在智能客服、市场分析报告、AI辅助编程领域
# 强化学习
强化学习的作用:训练大模型,结合少量SFT,引入少量高质量监督数据(如数千个CoT示例)进行微调,提升模型初始推理能力,再通过RL进一步优化,最终达到与OpenAI o1相当的性能
长链推理CoT:CoT让AI模型逐步分解复杂问题,比如在智能客服、市场分析报告、AI辅助编程领域
传统训练局限:监督式学习依赖人工标注(如rank list软件),存在数据瓶颈和创新天花板。
强化学习优势: 数据生成:通过自我对弈产生海量训练数据(如AlphaGo的3000万盘棋局)
奖励机制:基于最终结果反向优化过程(如围棋胜负判断落子质量)
创新突破:超越人类既有经验(如AlphaGo下出人类未见的棋路)
模型演进:从DeepSeek-R1-Zero纯强化学习到DeepSeek-R1多阶段训练(冷启动SFT→RL→COT+通用数据SFT→全场景RL)
# DeepSeek-R1-Zero训练模式复用与蒸馏
文科生理科化:在DeepSeek-v3(文科生)基础上通过监督学习训练理科能力,使用R1-Zero生成的数千条种子数据作为初始训练集。
数据飞轮机制:先提供少量种子数据(几千条),待模型具备基础能力后生成60万推理样本,形成"小火苗→大火"的迭代过程。
多模型复用:将80万训练语料(理科:文科=3:1)同时用于v3模型二次训练和7B等小模型蒸馏。
# DeepSeek-R1-Zero监督学习与数据飞轮
标记自动化:使用已具备推理能力的R1-Zero模型自动生成答案标记,替代人工标注。
数据配比:80万训练数据中保持3:1的理科(60万)与文科(20万)样本比例,防止模型遗忘基础能力。
两阶段训练:先进行监督学习(填鸭式背诵),再通过生成更多数据实现能力增强。
# DeepSeek-R1-Zero微调概念说明
本质区别:80万数据训练属于微调(Fine-tuning),通过改变v3模型参数使其获得新能力。
能力来源:理科思维来自R1-Zero自我探索生成的QA对,文科能力保留原始v3基础。
# 蒸馏概念说明
核心思想:将大模型(教师)知识迁移到小模型(学生),使其在体量更小的同时保留主要能力。
典型方法:包括软标签蒸馏(概率分布对齐)、隐藏层蒸馏(中间表示对齐)和数据增强(教师生成伪数据)。
# 不同尺寸的LLM
| 模型尺寸 | 参数量 | 特点 | 适用场景 | 硬件配置 |
|---|---|---|---|---|
| 1.5B | 15亿 | 轻量级,快速响应 | 轻量级任务(如短文本生成、基础问答) | 4核处理器、8GB内存,无需显卡 |
| 7B/8B | 70-80亿 | 平衡型,性能适中 | 中等复杂度任务(如文案撰写、代码生成) | 8核处理器、16GB内存,RTX 3060/4060 |
| 14B | 140亿 | 高性能,适合复杂任务 | 数学推理、代码生成、长文本处理 | i9-13900K、32GB内存,RTX 4090/A5000 |
| 32B | 320亿 | 专业级,高精度任务 | 医疗/法律咨询、大规模训练、金融预测 | Xeon 8核、128GB内存,2-4张A100 |
| 70B | 700亿 | 顶级模型,大规模计算 | 高精度专业领域任务、多模态任务预处理 | 8张A100/H100,128GB内存 |
| 671B | 6710亿 | 满血版,接近人类专家级推理能力 | 前沿科学研究、复杂商业决策分析 | 8张A100/H100(80GB),极高硬件需求 |
DeepSeek:
小模型(1.5B-14B) 响应快、硬件需求低,但基础能力薄弱(如7B模型在基础文本生成任务中表现不稳定,甚至“不及格”),无法胜任复杂任务。
中尺寸(32B及以上) 性能接近满血版(32B约实现671B的90%性能),可满足专业领域需求,但本地化部署成本较高(需64GB内存、80GB显存等)。
满血版(671B) 性能最强,适合超大规模AI研究、AGI探索,但部署成本极高(需多节点分布式训练,硬件需求极高)
不同尺寸的Qwen3模型适用于不同场景:
- 0.6B/1.7B适合本地测试、科研或边缘设备(如工控机)部署,
- 4B适用于手机端应用,
- 8B适用于电脑或汽车端的对话系统、语音助手等,
- 14B/32B适合企业复杂任务落地,
- 30B-A3B和235B-A22B则分别适合云端高效部署和旗舰级高性能场景(如数学证明、代码生成等)
235B-A22B在基准测试中可与DeepSeek-R1、Grok-3等顶尖模型竞争。
Qwen3模型支持“思考模式”(逐步推理)和“非思考模式”(快速响应),并支持119种语言和方言,具备更强的Agent能力和原生MCP支持。
# 蒸馏的定义与方法
# 什么是蒸馏
把大模型(教师)学到的知识压缩进小模型(学生),让后者在体量更小、推理更快的同时保留主要能力。
常用的方法
- 软标签蒸馏:用教师输出的概率分布训练学生;
- 隐藏层蒸馏:对齐中间表示;
- 数据增强:教师生成伪数据再训练
# 蒸馏的应用场景与性价比优势
部署优势:7B模型成本约为671B的1%,但可达到90%效果,适合端侧/边缘设备部署。
能力边界:学生模型虽不能超越老师(如8B无法超越671B),但能超越未蒸馏的同尺寸模型。
典型案例:Qwen2.5-7B等小模型通过蒸馏获得接近大模型的能力表现。
# 量化的定义与方法
指通过降低模型参数的存储精度(如从32位浮点数FP32降至8位整数INT8或4位INT4),以减少模型体积、加速推理并降低计算资源需求。
核心原理:
- 精度压缩:减少每个参数的比特数,例如FP32→INT8可减少75%存储需求。
- 误差补偿:如GPTQ采用逐层量化并调整剩余权重,以减少信息损失。
- 硬件加速:低精度计算(如INT8)在GPU/TPU上通常比FP32更快
| 任务类型 | FP16 vs. 4-bit差异示例 | 错误表现 |
|---|---|---|
| ①数值计算 | 问:“123456×789012等于多少?” | FP16全对;4-bit把中间步骤的进位算错,结果差3~4位 |
| ②闭卷知识问答 | 问:“2022年诺贝尔化学奖三位得主分别是谁?” | FP16精准列出Carolyn Bertozzi等三人;4-bit漏掉一人或名字拼写错误 |
| ③长文本定 | 位给一篇4k token法律合同,问第2页第3条违约责任金额 | FP16能定位“在第2页第3条,违约金为合同总价的5%”;4-bit给出3%这类相近却错误的数字 |
| ④少样本分类 | 5-shot新闻分类(体育/财经/科技) | FP16准确率94%;4-bit掉到78%,把“财经融资”错标成“科技” |
| ⑤创意写作 | 写一首五言绝句,要求押“春”韵 | FP16押韵且意境连贯;4-bit出现“春/唇/醇”混押或平仄失调 |
量化越低,模型越小、越快,但越可能在需要精细数值推理或知识细节的任务上出错。
# 总结
# DeepSeek不同尺寸版本及其特点
型号谱系:
小尺寸:1.5B(可笔记本部署)、7B/8B(个人使用,需显卡)
中尺寸:14B(数学推理/代码生成)、32B(企业入门级)
大尺寸:70B(需8张H800)、671B满血版(成本200-300万)性能特点:
1.5B:无需显卡,内存即可运行
7B:适合中等复杂度任务,需显卡支持
14B:可处理数学推理和代码生成
32B:企业级性价比选择,部署成本约10万元
70B:存在显著幻觉问题,部署需8张H800或L40(约52万)
# DeepSeek模型部署的成本与问题
成本参考:
32B版本:约10万元
70B版本:8张L40显卡约52万(单卡6.5万)
671B满血版:200-300万元主要问题:
70B版本存在思维链过长导致的幻觉现象
模型会将推理过程误认为用户输入上下文
企业反馈实际使用效果不及预期
# DeepSeek模型与其他模型的对比与选择
替代方案:
通义千问3系列:8B(个人用)、32B(企业用)、MOE版(激活参数22B)
8B版本可用24G显存的4090显卡部署
实际测试8B效果可媲美DeepSeek 671B选择建议:
企业级推荐千问32B或MOE版
知识库问答场景8B已足够
移动端/嵌入式设备需用小尺寸模型
# DeepSeek模型部署建议
硬件配置:
8B:单张4090显卡(24G显存)
32B:企业级服务器
70B:需8张H800/L40显卡集群部署策略:
小尺寸模型直接全量部署
大模型建议采用vLLM等推理框架
需考虑多并发时的冗余设计
# 多并发问题与量化策略
并发处理:
需要多卡并行和负载均衡
推荐使用vLLM等专用推理框架量化应用:
企业部署通常直接使用小尺寸全量模型
量化主要用于模型压缩(如175B模型从70G压缩至20G)
常用方法:GPTQ(4-bit量化)、QLoRA(动态量化)
# 模型选择原则:
V3-0324适用场景:日常编程、快速开发、前端代码生成、常规脚本任务
R1适用场景:数学密集型计算、复杂算法、代码逻辑深度优化、需要推理过程的任务
使用技巧: 简单任务避免使用R1防止过度思考引入幻觉
复杂任务优先选择R1以获得更好算法实现
出现幻觉时应开启新对话而非持续修正性能对比:
R1在代码能力上优于V3但响应速度较慢
V3适合绝大多数常规编程任务
R1特别擅长物理、数学相关复杂逻辑实现
# DeepSeek私有化部署
- DeepSeek-R1模型
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1 |
| DeepSeek-R1 | 671B | 37B | 128K | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Zero |
- DeepSeek-R1蒸馏模型
| Model | Base Model | Download |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Llama-70B |
目前开放出来的1.5B、7B、14B等模型是Qwen/llama借助R1推理强化调出来的“蒸馏”版本,不是真正的R1。真正 的DeepSeek-R1是671B全量版
deepseek-r1:1.5b——1-2G显存
deepseek-r1:7b——6-8G显存
deepseek-r1:8b——8G显存
deepseek-r1:14b——10-12G显存
deepseek-r1:32b——24G-48显存
deepseek-r1:70b——96G-128显存
deepseek-r1:671b——496GB
部署建议:
- 个人使用:推荐1.5B或7B版本,1.5B可在无GPU环境下运行(文件大小约4G)
- 企业级应用:可考虑32B或更大版本
可以去魔塔社区搜索模型并下载 https://modelscope.cn/search?search=deepseek (opens new window)
# Vllm使用
Vllm使用:是由伯克利大学LMSYS组织开源的LLM高速推理框架,用于提升LLM的吞吐量与内存使用效率。它通过PagedAttention技术高效管理注意力键和值的内存,并结合连续批处理技术优化推理性能。vLLM支持量化技术、分布式推理、与Hugging Face模型无缝集成等功能
vllm servedeepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len32768 --enforce-eager
- vllm serve,启动vLLM推理服务的命令
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B,Hugging Face模型库中的模型名称,vLLM会尝试从HF下载模型
- --tensor-parallel-size 2,启用张量并行,在2个GPU上分布式运行模型(适合32B大模型)
- --max-model-len32768,设置模型的最大上下文长度(32K tokens),确保能处理长文本。
- --enforce-eager,禁用CUDA Graph优化(可能在某些环境下更稳定,但性能稍低)
如果我在本地的ubuntu下面有/root/autodl-tmp/models/tclf90/deepseek-r1-distill-qwen-32b-gptq-int4,如何使用vllm进行推理?
vllm serve /root/autodl-tmp/models/tclf90/deepseek-r1-distill-qwen-32b-gptq-int4 --tensor-parallel-size 1 --max-model-len32768 --enforce-eager --quantization gptq --dtypehalf
关键改动:
指定本地路径:替换HF模型名为你的本地路径。
--quantization gptq:显式声明使用GPTQ量化。
--dtype:设为half(FP16)或auto(自动选择),因为GPTQ本身是4-bit,但计算时需指定中间精度。
--tensor-parallel-size:设置GPU并行数量(如2表示使用2个GPU)
--max-model-len:设置最大上下文长度(如32768表示32K tokens)
--enforce-eager:禁用CUDA Graph优化(稳定性更高但性能稍低)
# CASE:DeepSeek-R1-7B使用(GPU部署)
#导入必要的库
from modelscope import AutoModelForCausalLM,AutoTokenizer
#设置模型路径
model_name= "/root/autodl-tmp/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
#加载模型
#torch_dtype="auto"自动选择合适的数据类型
#device_map="cuda"指定使用GPU加速
model =AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="cuda" #也可以设置为"auto"自动选择设备
)
#加载对应的分词器
tokenizer =AutoTokenizer.from_pretrained(model_name)
#设置用户输入的提示词
prompt = "帮我写一个二分查找法"
#构建对话消息列表
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
#将消息转换为模型可接受的格式
text =tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt= True
)
#将文本转换为模型输入格式并移动到正确的设备上
model_inputs= tokenizer([text],return_tensors="pt").to(model.device)
#生成回复
generated_ids=model.generate(
**model_inputs,
max_new_tokens=2000
)
#提取生成的文本部分(去除输入部分)
generated_ids= [
output_ids[len(input_ids):] for input_ids,output_ids in zip(model_inputs.input_ids,generated_ids)
]
#将生成的token ID解码为文本
#skip_special_tokens=True跳过特殊token
response =tokenizer.batch_decode(generated_ids,skip_special_tokens=True)[0]
#打印生成的回复
print(response)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# Ollama使用
Ollama官方主要支持macOS和Linux,但Windows用户也可以安装
- 方法1:使用WSL
- 打开PowerShell(管理员权限),运行:wsl--install
重启电脑后,WSL会自动完成安装(默认安装Ubuntu) - 安装Ollama 在WSL终端(Ubuntu)中运行:curl-fsSLhttps://ollama.com/install.sh |sh
- 启动Ollama服务 运行 ollama serve (保持此终端运行,另开一个新终端进行后续操作)
方法1我没有使用,我使用的是下面的方法2,更简单一些
- 方法2:直接下载Windows版(记得在设置里更改一下模型默认的下载地址,不然下到C盘去了)
https://ollama.com/ (opens new window)
安装后,Ollama会作为服务运行(可在任务管理器查看)
Ollama官方模型库https://ollama.com/library (opens new window)
下载deepseek-r1:1.5b模型
ollama pull deepseek-r1:1.5b
如果要删除该模型,可以使用
ollama rm deepseek-r1:1.5b
运行该模型,使用
ollama run deepseek-r1:1.5b
# Ollama使用(使用Ollama REST API)
import requests
def query_ollama(prompt, model="deepseek-r1:8b"):
url = "http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"stream":False # 设置为True可以获取流式响应
}
response = requests.post(url, json=data)
if response.status_code == 200:
return response.json()["response"]
else:
raise Exception(f"API 请求失败:{response.text}")
# 使用示例
response = query_ollama("你好,请介绍一下你自己")
print(response)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import requests
# 支持流式相应的query_ollama函数
def query_ollama(prompt, model="deepseek-r1:8b", stream=False):
url = "http://localhost:11434/api/generate"
data = {
"model": model,
"prompt": prompt,
"steam": stream # 设置为True可以获取流式响应
}
if stream:
# 流式响应处理
with requests.post(url, json=data, stream=True) as response:
if response.status_code == 200 :
# 逐行打印流式响应内容
for line in response.iter_lines(decode_unicode=True):
if line:
# Ollama流式返回每行是一个json字符串
try:
import json
obj = json.loads(line)
# 打印每段响应内容
print(obj.get("response",""), end="", flush=True)
except Exception as e:
print(f"解析流式响应出错:{e}")
else:
raise Exception(f"API请求失败{response.text}")
else:
response = requests.post(url, json=data)
if response.status_code == 200:
return response.json()['response']
else:
raise Exception(f"API请求失败{response.text}")
# 使用示例
print("流式响应:")
query_ollama("帮我写一个二分查找法", stream=True)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 总结
大模型API是连接AI能力的桥梁,让开发者无需关注底层架构即可调用前沿AI能力,极大拓展了技术应用的边界。
- Prompt工程是激活大模型潜力的钥匙
结构化设计(角色定义/分步指令/示例规范)
业务场景对齐(需求分析→Prompt迭代→效果验证)
性能优化技巧(温度系数/输出限制/上下文管理) - LLM正在重塑开发范式,通过大模型API接口覆盖NLP/CV/多模态任务
私有化部署限制:
- 模型尺寸受限
- 上网环境可能受限
- 系统集成复杂度高
# 提示词工程
# Prompt原理
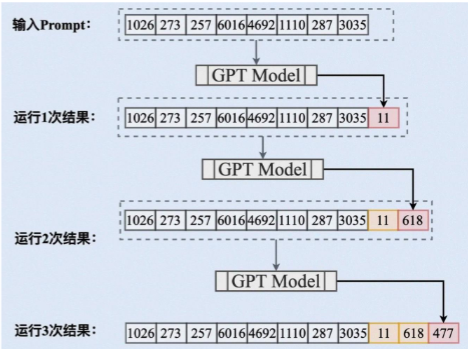
GPT在处理Prompt时,GPT模型将输入的文本(也就是Prompt)转换为一系列的词向
- 然后,模型通过自回归生成过程逐个生成回答中的词汇。在生成每个词时,模型会基于输入的Prompt以及前面生成的所有词来进行预测。
- 这个过程不断重复,直到模型生成完整的回答
你认为Prompt Engineering的重要性如何?
一个有效的Prompt可以:
- 提升AI模型给出的答案的质量
- 缩短与AI模型的交互时间,提高效率
- 减少误解,提高沟通的顺畅度
# 提示词策略差异
通用模型
需要显示引导推理步骤,比如通过CoT提示,否则可能会忽略关键逻辑
依赖提示词补偿能力短板,比如要求分步骤思考,提供few-shot参考示例等推理模型
提示语更简洁,指需要明确任务目标和需求,因为模型已经内化了推理逻辑
无需逐步指导,模型会自动生成结构化推理过程。如果强行分步骤拆解,反而会降低其推理能力
# 提示词关键原则
模型选择
根据任务类型选择,而非模型热度
比如创意类任务选择通用模型,数学、物理、编程等理科推理类任务选择推理模型提示词设计
通用模型:结构化、补偿性引导=>缺什么,补什么
推理模型:简洁指令、聚焦目标、信任其内化能力=>要什么,直接说避免误区
不要对通用模型过度信任,如直接问复杂推理问题,需要分步骤进行
不要对推理模型进行启发式(简单)提问,推理模型会给你过于复杂的深度结果。
对于复杂问题,推理模型依然会有错误的可能,或存在忽略某些细节的可能,这时需要多次交互
# Prompt编写原则
- 明确目标:清晰定义任务,以便模型理解。
- 具体指导:给予模型明确的指导和约束。
- 简洁明了:使用简练、清晰的语言表达Prompt。
- 适当引导:通过示例或问题边界引导模型。
- 迭代优化:根据输出结果,持续调整和优化
一些有效做法:
- 强调,可以适当的重复命令和操作
- 给模型一个出路,如果模型可能无法完成,告诉它说"不知道"
- 尽量具体,对于专业性要求强的,少留解读空间(在你的专业领域中,把它看成孩子)
# 具体指导:给予模型明确的指导和约束
示例1 文本摘要生成任务目标
生成新闻文章的摘要。
不明确的指导:
请为这篇新闻文章生成摘要。
具体的指导:
请将以下新闻文章总结为3-4句话,包含主要事件、人物和时间地点。
示例2:客户服务对话任务目标
回答客户关于订单状态的问题。 不明确的指导:
请回答客户关于订单状态的问题。
具体的指导:
请使用礼貌的语言回答客户关于订单状态的问题,
提供具体的订单信息和预计到达时间。
如果订单有任何问题,请提供解决方案或进一步的联系信息。
2
3
# 具体指导:给予模型明确的指导和约束。
示例3:生成a beautiful girl的图片
不明确的指导:
a beautiful girl
具体的指导:
anime girl with long dark hair , simple and elegant style, light
silver and light gray, wavy resin sheets , in the style of digital
painting,gongbi, realistic yet romantic, shiny/glossy, cute
and dreamy, smooth lines, pure white background,
2
3
4
# 简洁明了:使用简练、清晰的语言表达Prompt。
示例1:文章续写任务目标
根据给定开头续写一段故事。 冗长的指导:
请基于下面提供的故事开头续写一段文字。续写时请
保持与原文风格一致,注意故事的连贯性和合理性。
希望续写的部分能够引人入胜,并且能够自然地衔接
上文。如果有任何疑问,请尽量参照原文的风格进行。
2
3
4
简洁明了的指导:
根据以下开头续写故事:
示例2:翻译任务任务目标
将一段英文文本翻译成中文。 冗长的指导: 简洁明了的指导: 请将以下英文文本翻译成中文: 请将以下英文文本翻译成中文。我希望翻译的内容准 确,并且保持原文的意思。翻译时请注意语法和用词, 尽量使用简洁明了的语言表达。如果有任何不确定的 地方,请尽量保持原意,不要进行过多的自由发挥。 下面是需要翻译的文本。
# 适当引导:通过示例或问题边界引导模型。
示例1:邮件撰写
TO DO:写一封请假邮件。 无引导的指导:
请写一封请假邮件。
如果有优秀范例模版,对于模型来说是很好的指导
有引导的指导:
请写一封请假邮件,内容包括请假原因、请假时间以及对工作的
安排。
示例:
主题:请假申请
尊敬的[经理姓名],
我因个人原因需要请假两天,从6月20日至6月21日。请假期间,
我会确保手头工作交接给同事[同事姓名],并保持电话畅通。如
有紧急情况,可随时联系我。感谢您的理解和批准。
此致
敬礼
[您的姓名]
2
3
4
5
6
7
8
9
10
11
# 迭代优化:根据输出结果,持续调整和优化
帮我写一个a+b的Python函数
下面是一个简单的Python函数,用于计算两个数a和b的和:
def add(a, b):
return a + b
#示例使用
result = add(3, 5)
print(result) #输出: 8
2
3
4
5
6
需要考虑a和b不是数值的情况
为了处理a和b可能不是数值的情况,可以在函数中添加类型检
查,并在参数不是数值时抛出一个适当的异常。以下是一个改进
的版本:
def add(a, b):
if notisinstance(a, (int, float)) or notisinstance(b, (int, float)):
raiseTypeError("Both a and b must be numbers (int or float)")
return a + b
2
3
4
5
6
7
# Prompt编写框架(重要性排序)
- Prompt的组成:
- 任务(Task):始终以动词开始任务句子(如"生成","给予","写作"等),明确表达你的最终目标,可以有多个。
- 上下文(Context):提供上下文背景、所处环境等。
- 示例(Exemplars):提供具体的例子,用于可以提高输出质量。有时候我们没有示例,这时可以让GPT帮忙生成示例。
- 角色(Persona):你希望AI扮演的角色。可以是具体的人,也可以是虚构的角色。
- 格式(Format):你希望输出的格式,如表格、列表、段落等。
- 语气(Tone):指定输出的语气,如正式、非正式、幽默等。
- 重要性排序:
任务>上下文>示例>角色>格式>语气
如果模型回答不满意,依次Check自己的Prompt内容进行调整
写prompt是一个不断尝试和调整的过程
# Prompt编写技巧
在了解Prompt编写原则的基础上,还有一些Prompt编写技巧:
- 限制模型输出的格式
- 使用分隔符区分输入的不同部分
- 提供样例
- CoT思维工具
- 面向不同的角色进行讲解
# 技巧1:限制模型输出的格式
比如让大模型输出JSON格式,可以结构化数据,方便后续解析
用户:请从财务报表中提取以下信息,包括:公司名称,股票代码,营收,净利润,毛利,总资产,总负债。并以JSON格式返回。
{
"公司名称": "伊利股份",
"股票代码": "600887 ",
"营收": "325亿元",
"净利润": "59.23亿元",
"毛利": "105.6亿元",
"总资产": "1516.2亿元",
"总负债": "910亿元"
}
2
3
4
5
6
7
8
9
# 技巧2:使用分隔符区分输入的不同部分
请把三个引号括起来的文本,分别总结成为一句话 '''文本内容1''' '''文本内容2'''
在编写Prompt时,通过使用分隔符,可以清晰地区分不同部分的文本,提升文本的组织性和可读性。
# 技巧3:提供样例
针对有一定歧义或复杂的情况,给出具体示例方便大模型进行学习
请帮我对用户的评价进行分类,直接输出:正面/负面,并给出理由
示例1:
用户评价:这次开户真是太满意了,都一周了,客服还没有回复我
输出:负面,客户并不是真的满意,客服一周未回复,造成了不满。
示例2:
用户评价:广发银行的开户过程非常顺利,客服态度亲切。
输出:正面,开户过程顺利,客服态度好。
请回答如下问题:
用户评价:开户流程简洁明了,不需要繁琐的纸质材料,所有步骤
都可以在线完成
2
3
4
5
6
7
8
9
10
# 技巧4:CoT思维工具
CoT(Chain of Thought,思维链)通过将复杂任务分解为多个简单的步骤,帮助模型系统地思考并解决问题。
你是一个数学助手,请根据以下步骤计算用户输入的金额。请
将每个金额首先加上1000元,接着减去500元,然后乘以1.2输
出计算结果,以','作为分隔符进行返回。
你可以参考以下计算过程来帮助解决:
"""
对于输入:2000, 3000, 4000
计算过程如下:
首先分别对输入的2000, 3000, 4000加上1000,得到:3000,4000, 5000
然后将3000, 4000, 5000分别减去500,得到:2500, 3500, 4500
然后将2500, 3500, 4500分别乘以1.2,得到:3000, 4200, 5400
答案是:3000, 4200, 5400
"""
输入:1500, 2500, 3500
2
3
4
5
6
7
8
9
10
11
12
13
你是一个客户服务助手,请按照以下步骤处理客户的投诉。首
先,记录客户的投诉类型,然后确定处理优先级(高、中、
低),接着分配给适当的部门,最后生成一个处理跟踪编号并
直接输出。
计算过程示例:
"""
客户投诉:客服的态度冷淡,没有耐心解答我的问题。
处理过程如下:
首先记录客户的投诉类型,得到:客服态度差
然后确定处理优先级,得到:优先级高
然后分配给适当的部门,得到:客服部
最后生成一个跟踪编号,得到KF10001
"""
客户投诉:我的账户意外冻结了。我并未收到任何提前通知或
解释。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
CoT(Chain of Thought,思维链)的作用:
- 系统化问题解决:将复杂问题分解为多个简单步骤,使解决过程更加有序和清晰。
- 提高透明度,减少错误:帮助理解和追踪每个决策点,减少整体错误发生的概率。
- 提升模型推理能力:帮助模型学习如何系统地分解和解决此类问题,提高在类似任务中的表现。
# 技巧5:面向不同的角色进行讲解
把我当做五岁小朋友一样,向我解释超导体
# 学会与AIGC沟通
未来每个人都是prompt engineer 任务结果=大模型+ Prompt
如何得到我们想要的结果?
- 了解我们的需求
- 了解大模型的工作原理
# Prompt实战
# CASE:使用提示词完成任务
我们想让AI扮演电信的客服人员,如何识别用户的手机流量套餐的需求?
import dashscope
# 这里使用我们刚刚申请的百炼的api key
api_key = "your-api-key"
dashscope.api_key = api_key
# 基于 prompt 生成文本
# 使用 deepseek-v3 模型
def get_completion(prompt, model="deepseek-v3"):
messages = [{"role":"user", "content": prompt}] # 将prompt作为用户输入
response = dashscope.Generation.call(
model=model,
messages=messages,
result_format='message', # 将输出设置为message形式
temperature=0 # 模型输出的随机性,0表示随机性最小
)
return response.output.choices[0].message.content # 返回模型生成的文本
# 任务描述
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称,月费价格,月流量。
根据用户输入,识别用户在上述三种属性上的需求是什么。
"""
# 用户输入
input_text = """
办个100G的套餐
"""
# prompt模板, instruction 和 input_text 会被替换喂上面的内容
prompt = f"""
# 目标
{instruction}
# 用户输入
{input_text}
"""
print("====Prompt====")
print(prompt)
print("==============")
# 调用大模型
response = get_completion(prompt)
print(response)
# JSON格式
# 输出格式
output_format = """
以 JSON 格式输出
"""
# 稍微调整下prompt,加入输出格式
prompt = f"""
# 目标
{instruction}
# 输出格式
{output_format}
# 用户输入
{input_text}
"""
# 调用大模型,指定用JSON mode 输出
response = get_completion(prompt)
print(response)
# CoT示例
instruction = """
给定一段用户与手机流量套餐客服的对话,。
你的任务是判断客服的回答是否符合下面的规范:
- 必须有礼貌
- 必须用官方口吻,不能使用网络用语
- 介绍套餐时,必须准确提及产品名称、月费价格和月流量总量。上述信息缺失一项或多项,或信息与事实不符,都算信息不准确
- 不可以是话题终结者
已知产品包括:
经济套餐:月费50元,月流量10G
畅游套餐:月费180元,月流量100G
无限套餐:月费300元,月流量1000G
校园套餐:月费150元,月流量200G,限在校学生办理
"""
# 输出描述
output_format = """
如果符合规范,输出:Y
如果不符合规范,输出:N
"""
context = """
用户:你们有什么流量大的套餐
客服:亲,我们现在正在推广无限套餐,每月300元就可以享受1000G流量,您感兴趣吗?
"""
cot = "请一步一步分析对话"
prompt = f"""
# 目标
{instruction}
{cot}
# 输出格式
{output_format}
# 对话上下文
{context}
"""
response = get_completion(prompt)
print(response)
# 使用Prompt调优Prompt
user_prompt = """
做一个手机流量套餐的客服代表,叫小瓜。可以帮助用户选择最合适的流量套餐产品。可以选择的套餐包括:
经济套餐,月费50元,10G流量;
畅游套餐,月费180元,100G流量;
无限套餐,月费300元,1000G流量;
校园套餐,月费150元,200G流量,仅限在校生。
"""
instruction = """
你是一名专业的提示词创作者。你的目标是帮助我根据需求打造更好的提示词。
你将生成以下部分:
提示词:{根据我的需求提供更好的提示词}
优化建议:{用简练段落分析如何改进提示词,需给出严格批判性建议}
问题示例:{提出最多3个问题,以用于和用户更好的交流}
"""
prompt = f"""
# 目标
{instruction}
# 用户提示词
{user_prompt}
"""
response = get_completion(prompt)
print(response)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147