
RAGFlow的智能体
# 关键概念
Agent 与 RAG 是互补的技术,各自在商业应用中增强对方的能力。RAGFlow v0.8.0 引入了 Agent 机制,前端具备无代码工作流编辑器,后端则提供全面的基于图的任务编排框架。该机制建立在 RAGFlow 现有的 RAG 解决方案之上,旨在编排搜索技术,如查询意图分类、对话引导和查询重写,以:
- 提供更高质量的检索,
- 容纳更多复杂场景。
# 创建一个 Agent
在继续之前,请确保:
- 您已正确设置要使用的 LLM。如需更多信息,请参阅配置 API 密钥或部署本地 LLM 的指南。
- 您已配置了数据集,并且相应的文件已正确解析。如需更多信息,请参阅配置数据集的指南。
点击页面顶部中间的 "智能体" 标签以显示 "智能体" 页面。如下面的截图所示
我们还提供了针对不同业务场景的模板。您可以从我们的代理模板中生成代理,也可以从头开始创建一个代理:
点击“创建智能体”》“从模板创建”
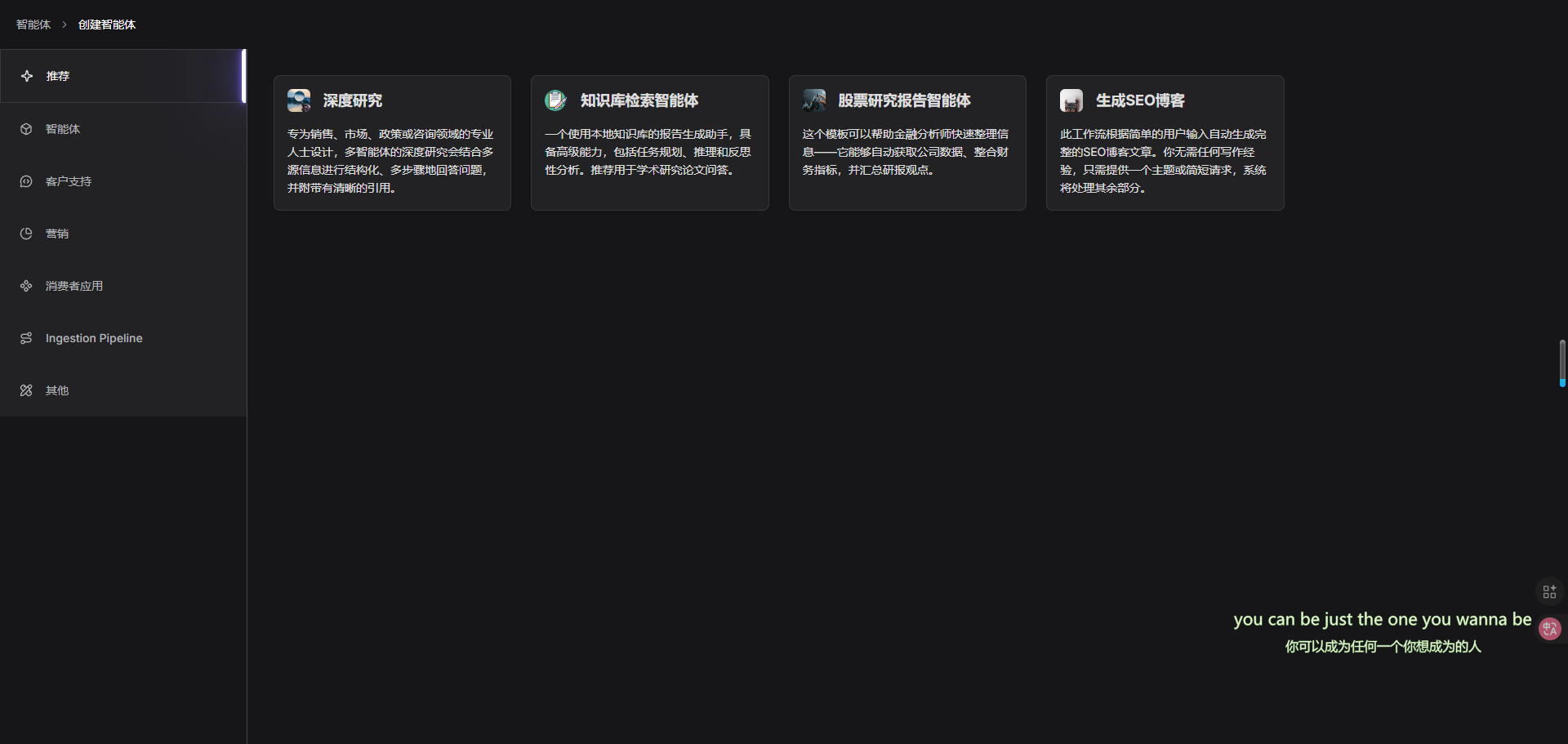
要从头开始创建智能体,请点击“从空白创建”。或者,如果您想从我们的模板中创建代理,请点击您想要的卡片,例如“深度研究”,在弹出的对话框中为您的智能体命名,然后点击“确定”以确认。您现在将被带到无代码工作流编辑页面。
点击“开始”组件上的+按钮以选择工作流中所需的组件。
点击保存以应用对代理的更改。
# 将智能体嵌入网页
- 在继续之前,您必须获取一个 API 密钥,否则会出现错误信息。
- 在代理页面上,点击你想要的代理以进入其编辑页面。
- 点击画布右上角的“管理 > 嵌入到网页”以显示 iframe 窗口
- 复制 iframe 并嵌入到您的网页中。
# 智能体组件
# 开始组件
工作流中的起始组件。
Begin 组件用于设置一个开场问候或接受用户的输入。当你创建一个代理(无论是基于模板还是从空白模板开始创建)时,它会自动被添加到画布上。工作流中应该只有一个 Begin 组件。
# 场景
在所有情况下,都需要一个 Begin 组件。每个代理都包含一个 Begin 组件,且不能被删除。
# 配置
点击组件以显示其配置窗口。在这里,您可以设置一个欢迎语和代理的输入参数(全局变量)。
模式
模式定义了工作流是如何被触发的。- 会话模式:代理是从会话中被触发的。
- 任务:代理在没有对话的情况下开始。
开场问候
仅对话模式。处于对话模式的代理会以开场问候开始。这是代理在对话模式下的第一条消息,可以是欢迎语或指导用户继续的指令。全局变量
您可以在 Begin 组件中定义全局变量,这些变量可以是必填的也可以是可选的。一旦设置,用户在与代理交互时需要为这些变量提供值。点击“+ 添加变量”来添加一个全局变量,每个变量具有以下属性:- 名称: 必填。一个描述性的名称,提供关于该变量的额外信息。
- 类型:必填。变量的类型:
- 单行文本:接受无换行的单行文本。
- 段落文本:接受多行文本,包括换行。
- 下拉选项:要求用户从下拉菜单中选择此变量的值。并且您需要至少设置一个下拉菜单选项。
- 文件上传:要求用户上传一个或多个文件。
- 数字:接受数字作为输入。
- 布尔值:要求用户在开和关之间切换。
- 键:唯一的变量名称。
- 可选: 一个开关,表示该变量是否为可选参数。
# 智能体组件
具备推理、工具使用和多智能体协作能力的组件。
一个 Agent 组件对 LLM 进行微调并设置其提示语。从 v0.20.5 版本开始,Agent 组件能够独立工作,并具备以下能力:
- 基于环境反馈进行自主推理与调整。
- 使用工具或子智能体来完成任务。
# 场景
当你需要 LLM 协助完成总结、翻译或控制各种任务时,一个智能体组件是必不可少的。
# 前提条件
- 确保你已正确配置聊天模型
- 如果你的 智能体 涉及数据集检索,请确保你已正确配置目标数据集。
# 快速入门
- 点击一个 智能体 组件以显示其配置面板。对应的配置面板出现在画布右侧。使用此面板来定义和微调 智能体 组件的行为。
- 选择你的模型。如果没有任何模型显示,请检查是否已在“模型提供商”页面上添加了聊天模型。
- 更新系统提示(可选)。系统提示通常定义了模型的角色。您可以保留系统提示不变,也可以自定义它以覆盖默认设置。
- 更新用户提示 。 用户提示通常定义了模型的任务。您会发现 sys.query 变量已自动填充。输入 / 或点击(x)以查看或添加变量。
- 跳过工具和 Agent。“+ 添加工具”和“+ 添加 Agent”部分仅在您需要将 Agent 组件配置为规划器(带有工具或子 Agent)时使用。在这个快速入门指南中,我们假设您的 Agent 组件是独立使用的(不包含下方的工具或子 Agent)。
- 选择下一个组件。当需要时,点击 Agent 组件上的+按钮,从下拉列表中选择工作流中的下一个组件。
# 配置
模型
- 模型:要使用的聊天模型。
- 自由度:一个用于温度、Top P、存在惩罚和频率惩罚设置的快捷方式,表示模型的自由程度。从即兴发挥、精确控制到平衡模式,每个预设配置都对应一组独特的温度、Top P、存在惩罚和频率惩罚参数。此参数有三个选项:
- 即兴创作:产生更具创意的回复。
- 精确:(默认)产生更保守的响应。
- 平衡:在自由发挥和精确之间取得平衡。
- 温度:模型输出的随机程度。默认为 0.1。
- 较低的值会导致更确定和可预测的输出。
- 较高的值会导致更富有创意和多样化的输出。
- 温度设为零时,相同提示将产生相同的输出。
- Top P:核采样
- 通过设置一个阈值 P 并限制采样仅在累积概率超过 P 的 token 上进行,从而降低生成重复或不自然文本的可能性。
- 默认为 0.3。
- 存在惩罚:鼓励模型在响应中包含更多样化的令牌。
- 存在惩罚值越高,模型越有可能生成尚未包含在生成文本中的令牌。
- 默认为 0.4。
- 频率惩罚:阻止模型在生成文本中过于频繁地重复相同的词语或短语。
- 较高的频率惩罚值会使模型在使用重复标记时更加保守。
- 默认为 0.7。
- 最大token数:
此设置用于指定模型输出的最大长度,以标记数(单词或单词片段)为单位进行衡量。默认情况下此功能是禁用的,允许模型自行决定响应中的标记数。
提示
- 不需要所有组件都使用同一个模型。如果某个特定模型在某个任务上表现不佳,可以考虑使用不同的模型。
- 如果你不确定温度(Temperature)、Top P、存在惩罚(Presence penalty)和频率惩罚(Frequency penalty)的机制,只需选择创意的三个选项之一。
系统提示
通常,你使用系统提示来描述给 LLM 的任务,指定其应该如何回应,并概述其他各种杂项要求。我们不打算深入讲解这个主题,因为它可以像提示工程一样广泛。不过,请注意系统提示通常会与键(变量)一起使用,这些键作为各种数据输入提供给 LLM。一个 Agent 组件依赖于键(变量)来指定其数据输入。其直接上游组件不一定是其数据输入,工作流中的箭头仅表示处理顺序。Agent 组件中的键与系统提示结合使用,以指定 LLM 的数据输入。使用正斜杠 / 或 (x) 按钮来显示要使用的键。
用户提示
用户自定义的提示。默认为 sys.query ,即用户查询。通常情况下,当使用 Agent 组件作为独立模块(不作为规划器使用)时,您通常需要在此处指定对应的检索组件的输出变量( formalized_content )作为 LLM 的输入部分。工具:
你可以使用一个 Agent 组件作为协作伙伴,借助其他工具进行推理和反思;例如,检索可以作为 Agent 的一个工具。Agent:
你使用一个 Agent 组件作为协作伙伴,它借助子 Agent 或其他工具进行推理和反思,形成一个多 Agent 系统。消息窗口大小
一个整数,用于指定输入到 LLM 的先前对话轮次数量。例如,如果设置为 12,则最后 12 轮对话的标记将被输入到 LLM 中。此功能会消耗额外的标记。此功能仅用于多轮对话。最大重试次数
定义代理在停止或报告失败之前,重试失败任务或操作的最大尝试次数。错误后的延迟
代理在重试失败任务之前等待的秒数,有助于防止立即重复尝试,并允许系统条件改善。默认为 1 秒。最大反思轮次
定义所选聊天模型的最大反思轮次数。默认为 1 轮。增加此值将显著延长您的代理的响应时间。输出
Agent 组件输出的全局变量名,可被工作流中的其他组件引用。
# 检索组件
一个从指定数据集中检索信息的组件。
# 场景
在大多数 RAG 场景中,检索组件是必不可少的,其中信息会在发送给 LLM 进行内容生成前从指定的数据集中提取出来。检索组件可以作为独立的工作流模块运行,也可以作为 Agent 组件的工具。在后一种角色中,Agent 组件可以自主控制何时调用它来进行查询和检索。
# 前提条件
请确保已正确配置您的目标数据集。
# 快速入门
- 点击一个检索组件以显示其配置面板。相应的配置面板会出现在画布的右侧。使用此面板来定义和微调检索组件的搜索行为。
- 输入查询变量,检索组件依赖于查询变量来指定其查询。
默认情况下,您可以使用 sys.query ,这是用户查询和开始组件的默认输出。所有在检索组件之前的全局变量也可以用作查询语句。使用 (x) 按钮或输入 / 以显示所有可用的查询变量。 - 选择要查询的数据集 您可以指定一个或多个数据集来检索数据。如果选择多个,请确保它们使用相同的嵌入模型。
- 展开高级设置以配置检索方法
默认情况下,检索使用加权关键词相似度和加权向量余弦相似度的组合。如果选择了重排序模型,则会改用加权关键词相似度和加权重排序得分的组合。作为初始步骤,您可以跳过此步骤,继续使用默认的检索方法使用重排序模型将显著增加系统的响应时间。 - 启用跨语言搜索
如果用户的查询与数据集的语言不同,您可以在跨语言搜索下拉菜单中选择目标语言。模型随后会将查询进行翻译,以确保跨语言语义的准确匹配。 - 测试检索结果
点击画布顶部的运行按钮以测试检索结果。 - 选择下一个组件
当需要时,点击检索组件上的 + 按钮,从下拉列表中选择工作流中的下一个组件。
# 配置
查询变量
选择用于检索的查询源。默认为 sys.query ,即 Begin 组件的默认输出。检索组件依赖于查询变量来指定其查询内容。所有在检索组件之前的全局变量也可以作为查询使用。点击 (x) 按钮或输入 / 可以查看所有可用的查询变量。知识库
选择要检索数据的数据库(可多选)。- 如果未选择任何数据库,意味着与代理的对话将不基于任何数据库,请确保留空“空响应字段”以避免错误。
- 如果您选择了多个数据库,请确保所选数据库使用相同的嵌入模型,否则会出现错误信息。
相似度阈值
RAGFlow 在检索过程中采用加权关键词相似度和加权向量余弦相似度的组合。此参数设置用户查询与数据集中存储的段落之间的相似度阈值。任何相似度得分低于此阈值的段落都将被排除在结果之外。向量相似度权重
此参数设置向量相似度在综合相似度评分中的权重。两个权重的总和必须等于 1.0。其默认值为 0.3,这意味着在组合搜索中,关键词相似度的权重为 1 - 0.3 = 0.7。Top N
此参数从检索到的片段中选择“Top N”个片段并将其输入到 LLM 中。Rerank model 重排序模型
空响应
如果从您的数据集中未检索到查询结果,请设置此为响应,或留空此字段以允许聊天模型在找不到任何内容时进行即兴发挥。跨语言搜索
选择一种或多种语言进行跨语言搜索。如果未选择任何语言,系统将使用原始查询进行搜索。使用知识图谱
是否在检索多跳问答时使用指定数据集中的知识图谱(或知识图谱)。启用此功能将涉及在实体、关系和社区报告块之间进行迭代搜索,大大增加检索时间。Output
检索组件输出的全局变量名,可在工作流中的其他组件中被引用。
# 消息组件
一个发送静态或动态消息的组件。
作为工作流的最后一个组件,Message 组件返回工作流的最终数据输出,并附带预定义的消息内容。如果提供了多个消息,系统会随机选择一个消息发送。
要发送的消息。点击 (x) 或输入 / 可快速插入变量。
点击 + 添加消息以添加消息选项。当提供多条消息时,消息组件会随机选择一条发送。
# 等待响应组件
一个暂停工作流并等待用户输入的组件。
一个 Await 响应组件会暂停工作流,启动对话并通过预定义表单收集关键信息。
# 场景
在需要显示代理响应或需要用户与计算机交互的情况下,使用 Await 响应组件是必不可少的。
# 配置
引导性问题
是否显示消息字段中定义的消息。消息
要发送的静态消息。
点击 + 添加消息以添加消息选项。当提供多条消息时,消息组件会随机选择一条发送。输入
你可以在 Await 响应组件中定义全局变量,这些变量可以是必填的或可选的。一旦设置,用户在与代理交互时需要为这些变量提供值。点击+添加一个全局变量。
# 切换组件
一个组件,用于评估指定条件是否满足,并根据结果引导执行流程。
一个 Switch 组件根据特定组件的输出来评估条件,并相应地引导执行流程,以实现复杂的分支逻辑。
# 场景
Switch 组件对于基于条件的执行流程方向至关重要。虽然它与 Categorize 组件有相似之处,后者也用于多策略场景,但关键区别在于它们的方法:Switch 组件的评估是基于规则的,而 Categorize 组件则涉及 AI 并使用 LLM 进行决策。
# 配置
Case n 一个 Switch 组件必须至少包含一个 case,每个 case 下需设置多个指定条件。当一个 case 下设置多个条件时,必须将它们之间的逻辑关系设置为 AND 或 OR。
一旦添加了新的 case,导航到画布上的 Switch 组件,找到 case 旁边的+按钮,并点击它以指定下游组件。
条件 评估特定组件的输出是否满足某些条件
当您为特定情况添加了多个条件时,会出现一个逻辑运算符字段,要求您设置这些条件之间的逻辑关系,为“与”或“或”。
- 运算符:形成条件表达式所需的运算符。
- 值:一个单一值,可以是整数、浮点数或字符串。不支持分隔符、多个值或表达式。
# 迭代组件
一个将文本输入拆分为文本片段并为每个片段迭代预定义工作流的组件。
一个交互组件可以将文本输入拆分为文本片段,并将内置的工作流应用于每个片段。
# 场景
当需要执行工作流循环且循环次数不固定,而是取决于特定代理组件输出所创建的片段数量时,迭代组件是必不可少的。
例如,如果你计划将几个段落输入到一个 LLM 中进行内容生成,每个段落都有自己的重点,而一次性将它们输入到 LLM 中可能会造成混淆或矛盾,那么你可以使用一个迭代组件,它封装了一个生成组件,以对每个段落重复执行内容生成过程。
另一个例子:如果你想使用 LLM 将一篇长篇论文翻译成目标语言,而不超出其令牌限制,可以考虑使用一个迭代组件,它封装了一个生成组件,将论文分成更小的部分,并对每一部分重复翻译过程。
# 内部组件
IterationItem 每个迭代组件包含一个内部的迭代项组件。迭代项组件是迭代组件内工作流的起点和输入节点。它管理由输入生成的所有文本段的工作流循环。迭代项组件仅对当前迭代组件封装的组件可见。
构建内部工作流
您可以将其他组件拉入迭代组件中以构建内部工作流,这些“添加的内部组件”将不再对当前迭代组件外部的组件可见。在添加的内部组件中,若要引用已创建的文本片段,只需在该内部组件的输入部分添加一个引用变量,其值等于 IterationItem。无需引用对应的外部组件,因为 IterationItem 组件会为所有创建的文本片段管理工作流的循环。
添加的内部组件在必要时可以引用外部组件。
# 配置
输入
Iteration 组件使用输入变量来指定其数据输入,即需要被分割的文本。您允许为 Iteration 组件指定多个输入源。点击输入部分的“+ 添加变量”以包含所需的输入变量。输入变量有两种类型:引用和文本。- 引用:使用组件的输出或用户输入作为数据源。您需要从下拉菜单中进行选择:组件输出下的组件 ID,或开始输入下的全局变量,该变量在开始组件中定义。
- 使用固定文本作为查询。您需要输入静态文本。
分隔符
用于将文本输入拆分为段的分隔符
# 分类组件
一个对用户输入进行分类并相应应用策略的组件。
一个分类组件通常是交互组件的下游组件。
# 场景
当你需要让 LLM 帮助你识别用户意图并应用适当的处理策略时,分类组件是必不可少的。
# 配置
查询变量
强制,选择用于分类的来源。分类组件依赖于查询变量来指定其数据输入(查询)。所有在分类组件之前的全局变量都可在下拉列表中使用。输入
分类组件依赖于输入变量来指定其数据输入(查询)。点击“+ 添加变量”按钮在输入部分添加所需的输入变量。输入变量有两种类型:引用变量和文本变量。模型
点击模型的下拉菜单以显示模型配置窗口。消息窗口大小
一个整数,用于指定输入到 LLM 的先前对话轮次数量。例如,如果设置为 12,则最后 12 轮对话的标记将被输入到 LLM 中。此功能会消耗额外的标记。分类名称
一个分类组件必须至少包含两个分类。此字段设置分类的名称。点击“+ 添加项”以包含所需的分类。您会注意到该分类名称是自动填充的。不用担心。每个分类在创建时都会被随机分配一个名称。您可以随意将其更改为一个对 LLM 来说更易理解的名称。
- 描述
此分类的描述。您可以输入一些标准、情境或信息,这些内容可能有助于 LLM 判断哪些输入属于此类别。
- 描述
# 代码组件
一个允许用户将 Python 或 JavaScript 代码集成到其 Agent 中以实现动态数据处理的组件。
# 场景
当需要将复杂的代码逻辑(Python 或 JavaScript)集成到 Agent 中以实现动态数据处理时,代码组件是必不可少的。
# 前提条件
我们使用 gVisor 将代码执行与主机系统隔离。请按照官方安装指南安装 gVisor,并在继续之前确保您的操作系统兼容。https://gvisor.dev/docs/user_guide/install/ (opens new window)