Embedding与向量数据库
# 什么是Embedding
# 为酒店建立内容推荐系统
西雅图酒店数据集:

- 字段:name,address,desc
- 基于用户选择的酒店,推荐相似度高的Top10个其他酒店
- 方法:计算当前酒店特征向量与整个酒店特征矩阵的余弦相似度,取相似度最大的Top-k个
余弦相似度
- 通过测量两个向量的夹角的余弦值来度量它们之间的相似性。
- 判断两个向量⼤致方向是否相同,方向相同时,余弦相似度为1;两个向量夹角为90°时,余弦相似度的值为0,方向完全相反时,余弦相似度的值为-1。
- 两个向量之间夹角的余弦值为[-1, 1]
给定属性向量A和B,A和B之间的夹角θ余弦值可以通过点积和向量长度计算得出
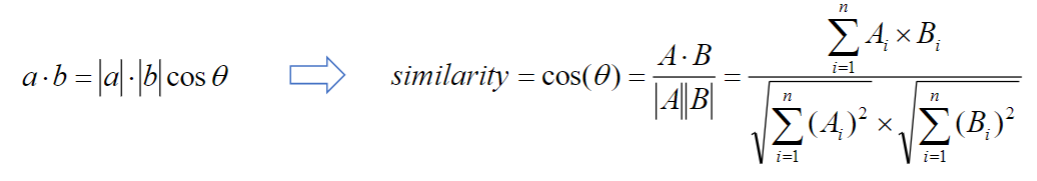
:::
计算A和B的余弦相似度:
- 句子A:这个程序代码太乱,那个代码规范
- 句子B:这个程序代码不规范,那个更规范
- 分词
- 句子A:这个/程序/代码/太乱,那个/代码/规范
- 句子B:这个/程序/代码/不/规范,那个/更/规范
列出所有的词 这个,程序,代码,太乱,那个,规范,不,更
计算词频
- 句子A:这个1,程序1,代码2,太乱1,那个1,规范1,不0,更0
- 句子B:这个1,程序1,代码1,太乱0,那个1,规范2,不1,更1
- 计算词频向量的余弦相似度
- 句子A:(1,1,2,1,1,1,0,0)
- 句子B:(1,1,1,0,1,2,1,1)
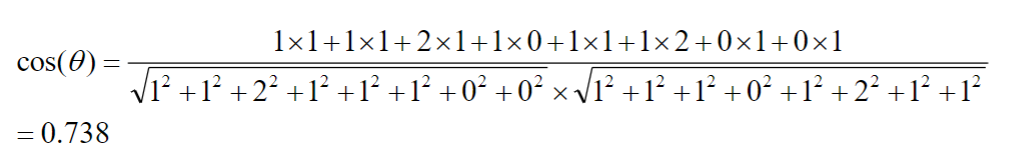
结果接近1,说明句子A与句子B是相似的
但是!如果是这样两句话,计算出来还是一样的结果,但实际的语义是完全不同的
- 句子A:这个程序代码太乱,那个代码规范
- 句子B:这个程序代码规范,那个更不规范
因此我们需要引入N-Gram
什么是N-Gram(N元语法):
- 基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关.
- N=1时为unigram,N=2为bigram,N=3为trigram
- N-Gram指的是给定一段文本,其中的N个item的序列
比如文本:ABCDE,对应的Bi-Gram为AB,BC,CD,DE
当一阶特征不够用时,可以用N-Gram做为新的特征。比如在处理文本特征时,一个关键词是一个特征,但有些情况不够用,需要提取更多的特征,采用N-Gram=>可以理解是相邻两个关键词的特征组合
优势:能捕捉"不规范"与"规范不"等关键语序差异
示例扩展:序列"a b c d e"
- 二元特征:ab, bc, cd, de
- 三元特征:abc, bcd, cde
n-gram分析:
- 一元语法(n=1):统计单个词频,"seattle"出现频率最高,其次是"hotel"、"center"等
- 二元语法(n=2):分析词组组合,如"wifi"、"guest room"、"fitness center"等高频组合
- 三元语法(n=3):提取三词短语,如"free wifi"、"seattle art museum"等特征短语
n值选择:通常取1-6,超过6后特征区分度降低
TF-IDF:
TF:Term Frequency,词频 一个单词的重要性和它在文档中出现的次数呈正比。

IDF:Inverse Document Frequency,逆向文档频率
一个单词在文档中的区分度。这个单词出现的文档数越少,区分度越大,IDF越大

因此基于内容的推荐:
- 对酒店描述(Desc)进行特征提取
- N-Gram,提取N个连续字的集合,作为特征
- TF-IDF,按照(min_df,max_df)提取关键词,并生成TFIDF矩阵
- 计算酒店之间的相似度矩阵
- 余弦相似度
- 对于指定的酒店,选择相似度最大的Top-K个酒店进行输出
特征维度:一元+二元+三元语法共生成26,000+维特征向量
特征矩阵:152家酒店×26,000维的稀疏矩阵
# 导入必要的库
import pandas as pd # 用于数据处理和分析
from sklearn.metrics.pairwise import linear_kernel # 用于计算余弦相似度
from sklearn.feature_extraction.text import CountVectorizer # 用于将文本转换为词频矩阵
from sklearn.feature_extraction.text import TfidfVectorizer # 用于将文本转换为 TF-IDF 特征矩阵
import re # 用于正则表达式操作,进行文本清洗
import matplotlib.pyplot as plt # 用于数据可视化
# 设置 pandas 显示选项,最多显示 30 列
pd.options.display.max_columns = 30
# 配置 matplotlib 以支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体,确保中文标签正常显示
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题(虽然本代码未直接涉及负号,但习惯上加上)
# 读取数据集
# 使用 'latin-1' 编码读取 CSV 文件,避免常见的编码错误
df = pd.read_csv('Seattle_Hotels.csv', encoding="latin-1")
# ==================== 数据探索 ====================
# 打印前 5 行数据,初步查看数据结构
print(df.head())
# 打印数据集中的酒店总数
print('数据集中的酒店个数:', len(df))
# ==================== 定义停用词列表 ====================
# 创建英文停用词列表
# 停用词是指在文本分析中通常被过滤掉的常见词汇(如 "the", "is", "and" 等),因为它们对区分文本内容贡献较小
ENGLISH_STOPWORDS = {
'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your',
'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it',
"it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this',
'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had',
'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while',
'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above',
'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once',
'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some',
'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don',
"don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn',
"couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn',
"isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't",
'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"
}
# ==================== 辅助函数:打印指定索引酒店的描述 ====================
def print_description(index):
"""
根据给定的行索引,打印该酒店的描述和名称。
参数:
index (int): 数据框中的行索引。
"""
# 选取指定索引行的 'desc' 和 'name' 列,并转换为 numpy 数组取第一个元素
example = df[df.index == index][['desc', 'name']].values[0]
if len(example) > 0:
print(example[0]) # 打印描述
print('Name:', example[1]) # 打印名称
print('第 10 个酒店的描述:')
print_description(10)
# ==================== 辅助函数:获取 Top-K 高频 N-gram 词 ====================
def get_top_n_words(corpus, n=1, k=None):
"""
统计语料库中 N-gram 的词频,并返回频率最高的 K 个词。
参数:
corpus (list): 文本列表。
n (int): N-gram 的 N 值,例如 n=1 是单词,n=2 是双词短语。
k (int): 返回前 K 个高频词,若为 None 则返回所有。
返回:
list: 包含 (词,频率) 元组的列表,按频率降序排列。
"""
# 初始化 CountVectorizer,设置 ngram_range 和自定义停用词
vec = CountVectorizer(ngram_range=(n, n), stop_words=list(ENGLISH_STOPWORDS)).fit(corpus)
# 将文本转换为词频矩阵 (Bag of Words)
bag_of_words = vec.transform(corpus)
# 计算每个词在所有文档中的总出现次数
sum_words = bag_of_words.sum(axis=0)
# 构建 (词,频率) 列表
# vec.vocabulary_ 是一个字典 {词:索引}
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
# 按照词频从大到小排序
words_freq = sorted(words_freq, key=lambda x: x[1], reverse=True)
# 返回前 k 个结果
return words_freq[:k]
# 获取描述字段中 3-gram 的 Top 20 高频词
common_words = get_top_n_words(df['desc'], n=3, k=20)
# 将结果转换为 DataFrame 以便处理和绘图
df1 = pd.DataFrame(common_words, columns=['desc', 'count'])
# 绘制横向条形图展示 Top 20 单词
# groupby('desc').sum() 确保即使有重复词(虽然这里不太可能)也能正确聚合
df1.groupby('desc').sum()['count'].sort_values().plot(
kind='barh',
title='去掉停用词后,酒店描述中的 Top20 单词 (3-gram)'
)
plt.show()
# ==================== 文本预处理 ====================
# 定义正则表达式规则
# 将特定符号替换为空格
REPLACE_BY_SPACE_RE = re.compile('[/(){}\[\]\|@,;]')
# 移除除了数字、小写字母、空格、#、+、_ 以外的所有字符
BAD_SYMBOLS_RE = re.compile('[^0-9a-z #+_]')
# 使用之前定义的自定义停用词列表
STOPWORDS = ENGLISH_STOPWORDS
def clean_text(text):
"""
对单个文本字符串进行清洗预处理。
步骤:
1. 转小写
2. 替换特殊符号为空格
3. 移除非法字符
4. 去除停用词
参数:
text (str): 原始文本。
返回:
str: 清洗后的文本。
"""
if not isinstance(text, str):
return ""
# 全部转为小写,统一格式
text = text.lower()
# 用空格替代一些特殊符号,如标点,防止单词粘连
text = REPLACE_BY_SPACE_RE.sub(' ', text)
# 移除不符合规则的字符(只保留字母、数字、空格等)
text = BAD_SYMBOLS_RE.sub('', text)
# 分割文本,过滤掉停用词,再重新拼接
text = ' '.join(word for word in text.split() if word not in STOPWORDS)
return text
# 对 'desc' 列应用清洗函数,生成新的 'desc_clean' 列
df['desc_clean'] = df['desc'].apply(clean_text)
# ==================== 建模:TF-IDF 与 相似度计算 ====================
# 将 'name' 列设置为索引,方便后续通过酒店名称查找
df.set_index('name', inplace=True)
# 初始化 TF-IDF 向量化器
# analyzer='word': 按词进行分析
# ngram_range=(1, 3): 考虑 1-gram 到 3-gram 的特征
# min_df=0.01: 忽略出现在少于 1% 文档中的词,减少噪声
# stop_words: 使用自定义的英文停用词列表
tf = TfidfVectorizer(analyzer='word', ngram_range=(1, 3), min_df=0.01, stop_words=list(ENGLISH_STOPWORDS))
# 针对清洗后的描述列 ('desc_clean') 拟合并转换得到 TF-IDF 矩阵
tfidf_matrix = tf.fit_transform(df['desc_clean'])
print('TFIDF 特征数量:')
print(len(tf.get_feature_names_out()))
# 计算酒店之间的余弦相似度
# linear_kernel 等价于余弦相似度,当输入向量已归一化时;在 TF-IDF 场景下常用来快速计算相似度
cosine_similarities = linear_kernel(tfidf_matrix, tfidf_matrix)
print('相似度矩阵形状:', cosine_similarities.shape)
# 创建一个 Series,索引是原始数据的行号,值是酒店名称(即当前的 df.index)
# 用于通过名称反查行索引
indices = pd.Series(df.index)
# ==================== 推荐函数 ====================
def recommendations(name, cosine_similarities=cosine_similarities):
"""
基于内容的推荐函数。
给定一个酒店名称,返回与其描述最相似的 Top 10 其他酒店。
参数:
name (str): 目标酒店名称。
cosine_similarities (ndarray): 预计算的相似度矩阵。
返回:
list: 推荐的酒店名称列表。
"""
recommended_hotels = []
# 找到目标酒店名称在索引中的位置 (idx)
# indices[indices == name] 返回名称匹配的 Series,取其 index 即为原数据框的行号
if name not in indices.values:
print(f"未找到酒店:{name}")
return []
idx = indices[indices == name].index[0]
print(f'目标酒店 [{name}] 的索引 idx={idx}')
# 获取该酒店与其他所有酒店的相似度得分,并转换为 Series 以便排序
# cosine_similarities[idx] 是该行向量,代表该酒店与所有酒店的相似度
score_series = pd.Series(cosine_similarities[idx]).sort_values(ascending=False)
# 取相似度最大的前 10 个(排除自己,所以从第 2 个开始取,即索引 1 到 10)
top_10_indexes = list(score_series.iloc[1:11].index)
# 根据索引从 df.index (即酒店名称) 中取出对应的酒店名
for i in top_10_indexes:
recommended_hotels.append(list(df.index)[i])
return recommended_hotels
# ==================== 测试推荐系统 ====================
# 测试案例 1
print("\n推荐与 'Hilton Seattle Airport & Conference Center' 相似的酒店:")
print(recommendations('Hilton Seattle Airport & Conference Center'))
# 测试案例 2
print("\n推荐与 'The Bacon Mansion Bed and Breakfast' 相似的酒店:")
print(recommendations('The Bacon Mansion Bed and Breakfast'))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
:N-Gram + TF-IDF的特征表达会让特征矩阵非常系数,计算量大,有没有更适合的方式?
# Word Embedding
什么是Embedding:
- 一种降维方式,将不同特征转换为维度相同的向量
- 离线变量转换成one-hot=>维度非常高,可以将它转换为固定size的embedding向量
- 任何物体,都可以将它转换成为向量的形式,从Trait#1到#N
- 向量之间,可以使用相似度进行计算
- 当我们进行推荐的时候,可以选择相似度最大的
Embedding 的精髓不仅仅是转换格式,更重要的是它能将数据的语义和关系保留下来。它把数据映射到一个连续的向量空间中,让语义相似的数据点,在这个空间里的距离也更近。
举个例子:
在 Embedding 空间里,“猫”和“小猫”的向量会非常接近。
“猫”和“小狗”的距离会稍远一些,但比“猫”和“火箭发射”的距离要近得多。
这意味着,计算机可以通过计算这些“数字身份证”之间的距离,来判断两个事物在含义上有多相似。这是一种高维的抽象,能够捕捉到复杂的内在逻辑,比如“国王 - 男人 + 女人 ≈ 女王”这样的关系。

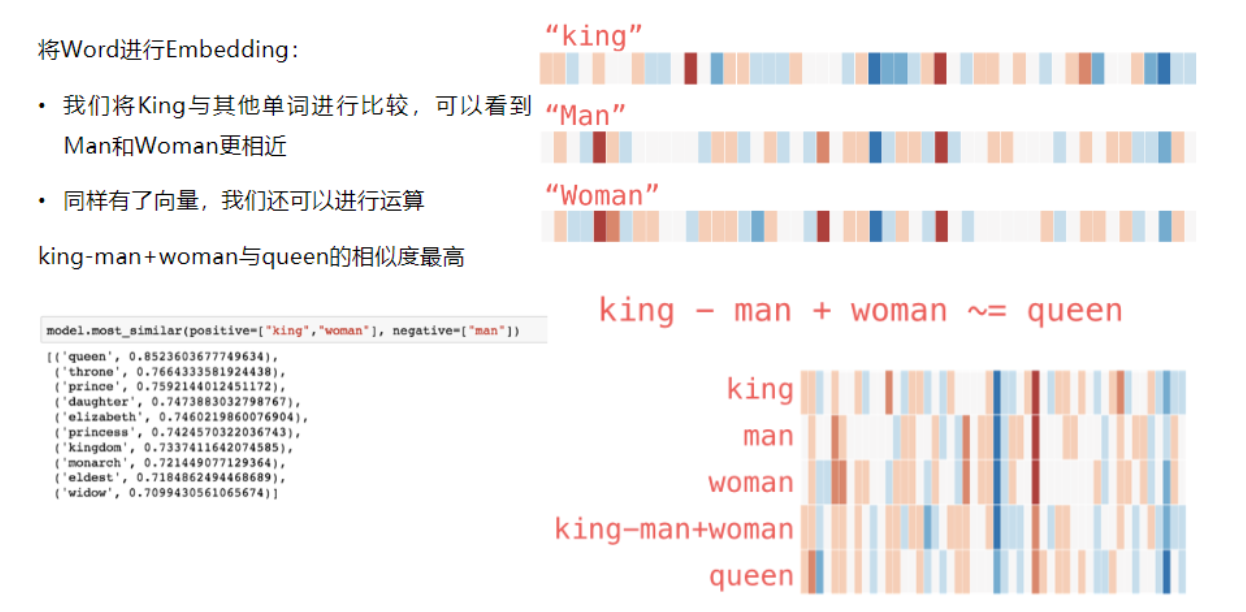
Word2Vec
Word2Vec 是 Google 在 2013 年提出的一种经典词向量算法,它可以说是现代大模型词嵌入技术的“开山鼻祖”。简单来说,它的核心任务就是把词语转换成一串数字(向量),让计算机能通过数学运算来理解词语的含义和关系。
其背后的原理主要基于两个核心概念:两种模型架构 和 两种优化技巧。
核心思想:分布假说 Word2Vec 的理论基础是“分布假说”(Distributional Hypothesis):出现在相似上下文中的词语,其语义也相似。
举个例子,“猫”和“狗”经常与“跑”、“跳”、“可爱”等词一同出现,因此在向量空间中,它们的位置就会非常接近。Word2Vec 通过在一个巨大的文本库上训练,学习预测一个词的上下文,从而自动捕捉到这种语义关系。两种模型架构 Word2Vec 提供了两种不同的神经网络架构来学习词向量,它们的目标恰好相反:
CBOW (Continuous Bag of Words,连续词袋模型) 目标:根据上下文词语,来预测中间的中心词。
例子:看到句子“我 爱 吃 苹果”,CBOW 会利用“我”、“爱”、“吃”这三个词,来预测中间的词是“苹果”。
特点:训练速度快,对高频词的表示效果较好,但可能会“平滑”掉一些低频词的特征。
Skip-Gram (跳字模型)
目标:根据中心词,来预测其周围的上下文词语。
例子:还是句子“我 爱 吃 苹果”,Skip-Gram 会以“苹果”作为输入,尝试预测出它的上下文“我”、“爱”、“吃”。
特点:训练速度较慢,但能更好地捕捉低频词的语义,生成的词向量质量通常更高。
你可以把它们想象成两个学习方式不同的学生:
CBOW 像是一个善于总结整体内容的学生,通过看周围的话来猜空缺的词。
Skip-Gram 像是一个善于发散思维的学生,给它一个词,它能联想到很多相关的词。
Word2Vec 的训练过程
Word2Vec 的训练过程本质上是一个浅层神经网络的学习过程。那个“隐藏的矩阵”就是我们最终想要的词向量库,它是在训练中通过不断调整网络权重而“学”来的。
我们可以把这个过程拆解为以下几个核心步骤来理解:
准备工作:数据与初始化
数据预处理:首先,我们需要一个巨大的文本语料库(比如维基百科)。然后对文本进行清洗、分词,并构建一个词汇表,给每个词分配一个唯一的索引。
生成训练样本:根据你选择的模型(CBOW 或 Skip-gram)和设定的窗口大小,从语料库中提取出成对的训练数据。
CBOW:用上下文词预测中心词。例如,窗口为2时,句子“我 爱 吃 苹果”,会生成样本 (['我','爱','吃','苹果'], '吃')。
Skip-gram:用中心词预测上下文词。同样的句子会生成样本 ('吃', ['我']), ('吃', ['爱']), ('吃', ['吃']), ('吃', ['苹果'])。
初始化矩阵:最关键的一步是初始化那个“隐藏的矩阵”。我们创建一个巨大的矩阵 𝑊, 它的大小是 [词汇表大小, 词向量维度](例如 [10000, 300])。矩阵的每一行对应一个词的初始向量。这些数值最初是随机生成的,没有任何意义。训练循环:前向传播与反向传播 接下来,模型会遍历每一个训练样本,不断重复以下过程:
输入与查找:将输入的词(比如 Skip-gram 中的“吃”)转换成 one-hot 向量(一个很长的向量,只有一个位置是1,其余都是0)。然后,用这个 one-hot 向量去乘以我们初始化的权重矩阵 𝑊。
关键点:由于 one-hot 向量只有一个1,这个矩阵乘法实际上就是从矩阵 𝑊 中“查找”并提取出对应词(“吃”)的那一行向量。这个向量就是该词的词向量。
计算输出:将上一步得到的词向量输入到网络的下一层(输出层),通过另一个权重矩阵和 softmax 函数,计算出词汇表中每个词作为“目标词”(在 CBOW 中)或“上下文词”(在 Skip-gram 中)的概率。
计算误差:将模型计算出的概率与真实的标签(即我们准备好的训练样本中的正确目标词)进行比较,计算出误差。
反向传播与更新:这就是“隐藏矩阵”得以进化的关键。通过随机梯度下降(SGD)等优化算法,将误差反向传播回网络,并更新权重矩阵 𝑊 中的数值。
- 核心揭秘:矩阵是如何得来的?
那个“隐藏的矩阵” 𝑊 的来历现在就很清晰了:
起点:它始于一个充满随机数的矩阵。
过程:在数百万次的训练迭代中,它不断地被调整。当模型预测错误时,它就会微调相关词的向量,使得下次遇到相似的上下文时,能给出更准确的预测。
终点:经过充分训练后,矩阵 𝑊 中的每一行,就不再是随机数,而是一个能够精准表达该词语义和语法特征的词向量。这个矩阵本身,就是我们训练出的 Word2Vec 模型的核心。
你可以把这个过程想象成一个“寻宝游戏”:
初始矩阵 是一张模糊的藏宝图。
训练样本 是一个个线索(“吃”这个词经常和“我”、“爱”、“苹果”一起出现)。
反向传播 是根据你当前的位置和宝藏的实际位置,修正地图的指引。
最终矩阵 就是一张清晰的藏宝图,图上每个词的位置都精准地反映了它的含义。
- 工程优化:如何让训练可行?
你可能会问,每次计算都要遍历整个词汇表(可能有几十万词)来算 softmax,岂不是慢死了?确实如此,所以 Word2Vec 在工程实现上使用了两个关键技巧来加速:
Hierarchical Softmax:用一棵二叉树来代替扁平的词汇表,将计算复杂度从 O(V) 降低到 O(log V)。
Negative Sampling:不计算所有词的概率,而是只计算几个“负样本”(随机选几个没出现的词)和一个“正样本”(真实出现的词),将问题简化为二分类任务,复杂度降至 O(1)。
总而言之,那个“隐藏的矩阵”是通过在海量文本上,利用神经网络的反向传播算法,不断根据“词语的上下文”这一线索进行自我修正而最终得到的。
# Word2Vec工具
Gensim工具
- pip install gensim
- 开源的Python工具包
- 可以从非结构化文本中,无监督地学习到隐层的主题向量表达
- 每一个向量变换的操作都对应着一个主题模型
- 支持TF-IDF,LDA,LSA,word2vec等多种主题模型算法
使用方法:
- 建立词向量模型:word2vec.Word2Vec(sentences)
- window,句子中当前单词和被预测单词的最大距离
- min_count,需要训练词语的最小出现次数,默认为5
- size,向量维度,默认为100
- worker,训练使用的线程数,默认为1即不使用多线程
- 模型保存model.save(fname)
- 模型加载model.load(fname)
# 计算小说中的人物相似度
数据集:西游记,计算小说中的人物相似度,比如孙悟空与猪八戒,孙悟空与孙行者
方案步骤:
- Step1,使用分词工具进行分词,比如NLTK,JIEBA
- Step2,将训练语料转化成一个sentence的迭代器
- Step3,使用word2vec进行训练
=- Step4,计算两个单词的相似度
# Embedding模型的选择
# Embedding的作用
- Embedding模型的核心特性是什么?
Embedding模型将文本等离散数据转换为低维、稠密的向量,捕捉其语义信息。
向量空间中的距离(如余弦相似度)可反映文本间的语义相似度。
# MTEB榜单
- 什么是MTEB榜单?[https://huggingface.co/spaces/mteb/leaderboard] (https://huggingface.co/spaces/mteb/leaderboard)
MTEB (Massive Text Embedding Benchmark)是一个全面的评测基准,它涵盖了分类、聚类、检索、排序等8大类任务和58个数据集。
通过MTEB榜单,可以清晰地看到不同模型(如BGE系列, GTE, Jina等)在不同任务类型上的性能表现。
比如例如,某些模型在检索任务上表现优异,而另一些则可能在聚类或分类任务上更具优势。这有助于我们根据具体应用场景,做出初步的模型筛选。
# MTEB榜单(任务类型)
MTEB (Massive Text Embedding Benchmark):
一个全面的评测基准,它涵盖了分类、聚类、检索、排序等8大类任务和58个数据集。
- 检索(Retrieval):从一个庞大的文档库中,根据用户输入的查询(Query),找出最相关的文档列表。
- 语义文本相似度(Semantic Textual Similarity, STS):判断一对句子的语义相似程度,并给出一个连续的分数(例如1到5分)。
- 重排序(Reranking):对一个已经初步检索出的文档列表进行二次优化排序,使得最相关的文档排在最前面。
- 分类(Classification):将单个文本(如电影评论、新闻文章)划分到预定义的类别中(如“正面/负面”、“体育/科技”)。
- 聚类(Clustering):在没有任何预设标签的情况下,将一组文本自动地分成若干个有意义的群组,使得同一组内的文本语义相似,不同组间的文本语义差异大。
- 对分类(Pair Classification):判断一对文本(句子或段落)是否具有某种特定关系,通常是二分类问题,如“是否是重复问题”、“是否是转述关系”。
- 双语挖掘(Bitext Mining):从两种不同语言的大量句子中,找出互为翻译的句子对。对于机器翻译至关重要。
- 摘要(Summarization):这个任务比较特殊,它不是让模型生成摘要,而是评估一个机器生成的摘要与人工撰写的参考摘要之间的语义相似度。
# 向量维度对模型性能的影响
向量维度对模型性能的影响是怎样的?
向量维度直接影响模型的表达能力、计算开销和内存占用。
高维度(如1024, 4096):编码更丰富、语义更细致,适用于需要深度语义理解的复杂场景,如大规模、多样化的信息检索,或者细粒度的文本分类。但计算成本更高,所需存储空间更大。
低维度(如256, 512):计算速度快,内存占用小,更适合计算资源有限,或实时性要求高的场景,比如移动端。如果把向量从768维拉长到1024维,检索指标提高不到1%,但内存要多占约35%,是否还要升维?
不需要,性价比低。
反过来,若压缩到768维后,指标下降超过5%=>说明信息损失大,值得使用更高维度。
# Jina Embedding
Jina Embedding:https://modelscope.cn/models/jinaai/jina-embeddings-v4 (opens new window)
- 由Jina AI(官网jina.ai)开发,公司总部位于德国柏林,专注于开源多模态搜索与向量化技术
- jina-embeddings-v4是一个多模态和多语言检索的通用嵌入模型,特别适合用于复杂的文档检索,包括包含图表、表格和插图的视觉丰富文档。
提示
Jina Embedding具有灵活的嵌入大小,默认情况下,密集嵌 入为2048维,但可以截断到最低128维,性能损失较小。
# 神奇的“俄罗斯套娃”
Jina-embeddings训练时使用了一种特殊技术(Matryoshka Representation Learning, MRL)=>俄罗斯套娃
生成完整向量:模型总是先在内部生成一个最完整、维度最高(比如2048维)的向量。
按需截断:这个长向量有一个非常神奇的特性,它的前128维、前256维、前512维……本身就是一组高质量的、独立的、可以正常使用的短向量。
用户指定:当调用模型时,可以通过embedding_size告诉模型“我这次只需要前512维就够了”=>模型就会截断向量,只返回前512维
场景1:社交媒体情感分析
社交媒体的文本短,实时性要求高,计算资源有限=>可以使用128维
在索引所有社交媒体评论时,都调用模型请求128维的向量。
当用户进行查询时,您也同样将查询文本转换为128维的向量,然后进行比较。
场景2:投资分析报告
投资分析、公司财报包含大量专业术语和细节(如风险提示、前瞻性声明),精准理解至关重要=> 2048维。
在索引所有投资分析报告时,都请求2048维的向量。查询语句也同样生成2048维的向量进行匹配。
# 单语言与多语言Embedding模型的选择
- 单语言模型:如BGE-large-zh
专门针对单一语言(如中文)进行训练,
比如:为电商平台开发一个智能客服问答系统。
目标:系统需要能精准理解用户使用中文提出的问题: - 我的订单何时能送达?
- 这个商品有保修吗?
- 如何办理退换货?
并从FAQ知识库中匹配最相关的答案。
提示
单语言模型在特定语言任务上,理解更深入、性能更优越。
比如理解“七天无理由退货”
- 多语言模型:如m3e-base或multilingual-e5-large
能够处理多种语言的文本,并将它们映射到统一的语义空间中。
场景:为一个国际连锁酒店集团,建立全球客户评论分析系统。
将来自世界各地的评论,按主题(如:客房清洁度、员工服务、地理位置)进行自动分类,无论评论是用英文、日文、西班牙文还是中文写的。
总部的经理可以用英文查询“Loud music at night”,系统需要能同时找出写着“夜に音楽がうるさい”的日文评论和“晚上音乐很吵”的中文评论。
提示
多语言Embedding的优势是能将不同语言的文本映射到统一的语义空间。
“clean room”、“部屋が綺麗”和“干净的房间”的向量在空间中会非常接近。
=>跨语言的聚类分析和检索才能实现。
# 如何选择适合的Embedding模型
模型选型是一个系统的过程,不能仅依赖于公开榜单。包括以下关键步骤:
- 明确业务场景与评估指标: 首先定义核心任务是检索、分类还是聚类?并确定衡量业务成功的关键指标,如搜索召回率(Recall@K)、准确率(Accuracy)或NDCG。
- 构建“黄金”测试集:准备一套能真实反映您业务场景和数据分布的高质量小规模测试集。比如,构建一系列“问题-标准答案”对=>评估模型好坏的“金标准”。
- 小范围对比测试(Benchmark):从MTEB榜单中挑选几款排名靠前且符合需求(如语言、维度)的候选模型。使用“黄金”测试集,对这些模型进行评测。
提示
Embedding模型的选择属于综合评估,即结合测试结果、模型的推理速度、部署成本=>做出最终决策
# 向量数据库
如何让LLM“记住”并利用海量、多样的私有知识?
向量数据库:AI时代的核心记忆体
与传统的关系型数据库不同,向量数据库用于存储和查询由非结构化数据(如文本、图片、音视频)转化而来的高维向量嵌入(Embeddings)。这些向量在多维空间中的距离代表了原始数据的语义相似度。
因此,向量数据库的核心能力是高效的相似性检索。向量数据库的核心价值?
为大模型提供长期记忆:弥补LLM上下文窗口(Context Window)长度限制和知识更新延迟的问题。
实现私有知识库的问答与搜索:将企业内部文档、产品信息等转化为向量,实现基于语义的智能检索。
赋能推荐系统、以图搜图等多种应用:通过计算用户、物品的向量相似度,提供更精准的推荐。
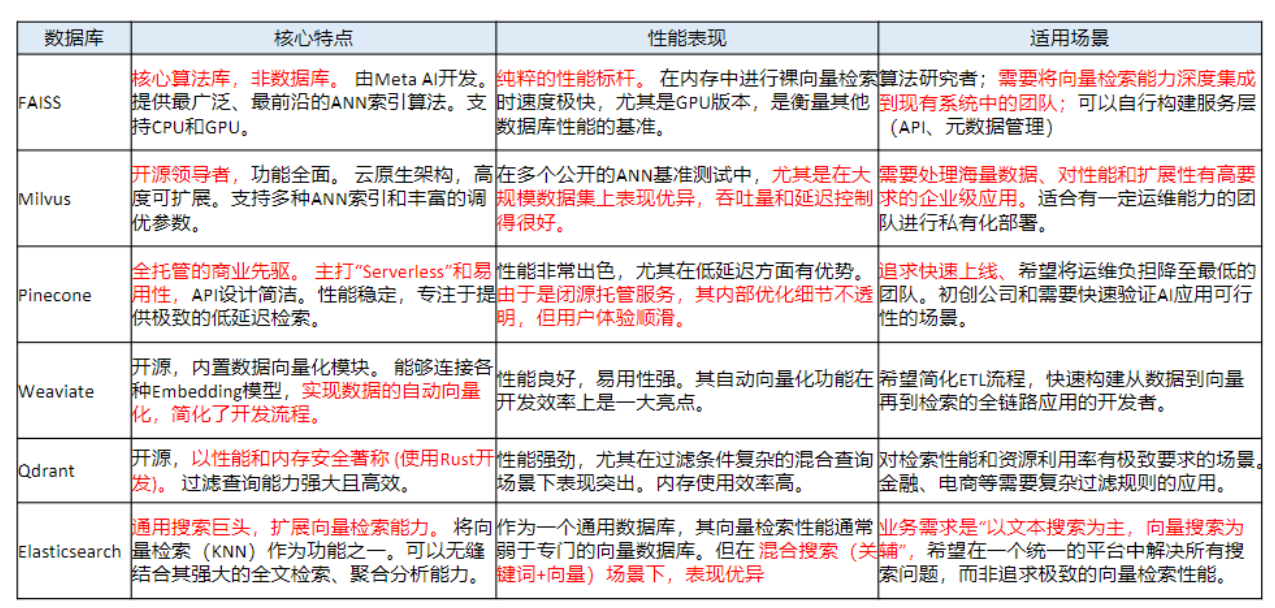
# 常见的向量数据库
- FAISS
- 特点:由Facebook开发,专注于高性能的相似性搜索,适合大规模静态数据集。
- 优势:检索速度快,支持多种索引类型。局限性:主要用于静态数据,更新和删除操作较复杂。
- Elasticsearch
- 特点:强大的分布式搜索和分析引擎,将向量搜索(k-NN)作为其众多功能之一。
- 优势:具备业界领先的混合搜索能力,可以无缝结合传统的关键词搜索和向量语义搜索。
- Milvus
- 特点:开源,支持分布式架构和动态数据更新。
- 优势:具备强大的扩展性和灵活的数据管理功能。
- Pinecone
- 特点:托管的云原生向量数据库,支持高性能的向量搜索。
- 优势:完全托管,易于部署,适合大规模生产环境
# 向量数据库与传统数据库的对比
数据类型
传统数据库:存储结构化数据(如表格、行、列)。
向量数据库:存储高维向量数据,适合非结构化数据。查询方式
传统数据库:依赖精确匹配(如=、<、>)。
向量数据库:基于相似度或距离度量(如欧几里得距离、余弦相似度)。应用场景
传统数据库:适合事务记录和结构化信息管理。
向量数据库:适合语义搜索、内容推荐等需要相似性计算的场景。
# 数据导入
- 如何将数据导入向量数据库?
- 数据清洗与准备
确保原始数据(如文本文档、图片)的质量,进行必要的预处理。 - 数据向量化(Embedding)
使用预训练的Embedding Model将原始数据转换成向量。
文本:可使用bge-m, Qwen3-Embedding, Jina-Embedding等模型。
图片:可使用CLIP,ResNet等模型。
选择合适的模型至关重要,它直接决定了向量的质量和后续检索的效果。
# os:用于读取环境变量(如 API Key),避免将敏感信息硬编码在代码中。
# OpenAI:这是 OpenAI 官方提供的 Python SDK。由于阿里云百炼提供了与 OpenAI API 格式兼容的接口,因此可以直接使用这个库来调用。
import os
from openai import OpenAI
client = OpenAI(
api_key="you api key", # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
completion = client.embeddings.create(
# model:指定使用的模型。这里调用的是阿里云的 text-embedding-v4 模型(该模型通常由通义实验室研发,如 text-embedding-v2 等,此处为 v4 版本)。
model="text-embedding-v4",
# input:需要向量化的文本内容。这里是字符串 '我想知道迪士尼的退票政策'。
input='我想知道迪士尼的退票政策',
dimensions=1024, # 指定向量维度(仅 text-embedding-v3及 text-embedding-v4支持该参数)
# encoding_format:指定向量数值的编码格式。"float" 表示使用浮点数(通常用于计算相似度),也可以设置为 "base64" 以节省存储空间。
encoding_format="float"
)
print(completion.model_dump_json())
"""
{"data":[{"embedding":[0.0026341788470745087,-0.03762197867035866,-0.024403059855103493,-0.010764381848275661,0.01541021279990673,0.0007359159062616527,0.018554862588644028,-0.02278093248605728,-0.05350175499916077,0.023905038833618164,-0.02632400020956993,-0.009014192037284374,0.001929833902977407,0.0883917286992073,0.003021924290806055,0.015310607850551605,0.05139583349227905,-0.04928991198539734,-0.053074877709150314,-0.012101925909519196,...],"index":0,"object":"embedding"}],"model":"text-embedding-v4","object":"list","usage":{"prompt_tokens":8,"total_tokens":8},"id":"276ed558-3bd3-9ff7-9485-01c33d175879"}
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
- 数据与元数据一同导入
将生成的向量及与其关联的元数据(Metadata)一同存入向量数据库。
- 向量(Vector):生成的Embedding数字数组。
- 唯一ID(ID):用于唯一标识每个数据点,方便后续的更新或删除。
- 元数据(Metadata):描述向量的附加信息,是实现高级检索的关键。例如:文本来源的文件名、章节、URL,商品的类别、品牌、价格,图片的创建日期、作者
import numpy as np
import faiss
from openai import OpenAI
# --- Step 1: 初始化 API 客户端 ---
try:
# 创建一个 OpenAI 客户端实例
# 注意:这里虽然是 OpenAI 的库,但我们通过 base_url 指向了阿里云(DashScope)
# 这样就能用调用 OpenAI 的方式来使用阿里云的 Embedding 服务
client = OpenAI(
# 从环境变量中读取你的 API Key
# 请确保你的电脑环境变量里设置了 DASHSCOPE_API_KEY,否则会报错
api_key="your-api-key",
# 指定阿里云的兼容接口地址
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
except Exception as e:
# 如果初始化失败(比如没配 Key),打印错误信息并退出程序
print("初始化OpenAI客户端失败,请检查环境变量'DASHSCOPE_API_KEY'是否已设置。")
print(f"错误信息: {e}")
exit() # 退出程序
# --- Step 2: 准备示例文本和元数据 ---
# 这是一个列表,里面存放了我们要存入数据库的“知识”
# 在实际项目中,这里的数据可能来自读取 PDF、数据库或网页爬虫
documents = [
{ # 第一条数据
"id": "doc1", # 我们给这条数据起的编号
# "text" 字段是核心内容,Embedding 模型会根据这段文字生成向量
"text": "迪士尼乐园的门票一经售出,原则上不予退换。但在特殊情况下,如恶劣天气导致园区关闭,可在官方指引下进行改期或退款。",
# "metadata" 存放额外信息(元数据),比如来源、作者、时间等
# 这些信息不参与向量化,但最后展示结果时会用到
"metadata": {"source": "official_faq_v1.pdf", "category": "退票政策", "author": "Admin"}
},
{ # 第二条数据
"id": "doc2",
"text": "购买“奇妙年卡”的用户,可以享受一年内多次入园的特权,并且在餐饮和购物时有折扣。",
"metadata": {"source": "annual_pass_rules.docx", "category": "会员权益", "author": "MarketingDept"}
},
{ # 第三条数据
"id": "doc3",
"text": "对于在线购买的迪士尼门票,如果需要退票,必须在票面日期前48小时通过原购买渠道提交申请,并可能收取手续费。",
"metadata": {"source": "online_policy.html", "category": "退票政策", "author": "E-commerceTeam"}
},
{ # 第四条数据
"id": "doc4",
"text": "园区内的“加勒比海盗”项目因年度维护,将于下周暂停开放。",
"metadata": {"source": "maintenance_notice.txt", "category": "园区公告", "author": "OpsDept"}
}
]
# --- Step 3: 创建元数据存储和向量列表 ---
# 我们需要两个容器:
# 1. metadata_store: 存放原文和元数据(给最后展示用)
# 2. vectors_list: 存放生成的向量(给 FAISS 计算用)
metadata_store = []
vectors_list = []
vector_ids = [] # 存放我们自定义的 ID
print("正在为文档生成向量...")
# enumerate 用来遍历列表,同时获取索引 i 和内容 doc
for i, doc in enumerate(documents):
try:
# 调用阿里云的 Embedding API
# 把 doc["text"] 这段文字转换成数学向量
completion = client.embeddings.create(
model="text-embedding-v4", # 使用的模型名称
input=doc["text"], # 输入是要转换的文字
dimensions=1024, # 指定向量的维度(长度)为 1024
encoding_format="float" # 指定数字格式为浮点数
)
# 从 API 返回的结果中提取出向量数据
# completion.data[0].embedding 是一个包含 1024 个数字的列表
vector = completion.data[0].embedding
vectors_list.append(vector) # 把这个向量存进列表
# 把原文信息存进 metadata_store
# 这样以后通过索引就能找到对应的原文
metadata_store.append(doc)
vector_ids.append(i) # 把列表的索引 i 作为这条数据的 ID
print(f" - 已处理文档 {i + 1}/{len(documents)}")
except Exception as e:
# 如果某条数据处理失败(比如网络超时),打印错误但继续处理下一条
print(f"处理文档 '{doc['id']}' 时出错: {e}")
continue
# 将 Python 列表转换为 NumPy 数组
# FAISS 库只能处理 NumPy 格式的数据,且数据类型必须是 float32
vectors_np = np.array(vectors_list).astype('float32')
vector_ids_np = np.array(vector_ids) # ID 数组
# --- Step 4: 构建并填充 FAISS 索引 ---
dimension = 1024 # 定义向量的维度,必须和上面生成 Embedding 时的维度一致
k = 3 # 定义搜索时返回最相似的 3 个结果
# 创建一个基础索引:IndexFlatL2
# L2 代表欧几里得距离(直线距离)。距离越近,代表两个向量越相似
index_flat_l2 = faiss.IndexFlatL2(dimension)
# 使用 IndexIDMap 包装基础索引
# 这样做是为了让我们能使用自定义的 ID(比如上面的 i),而不是只能用 FAISS 内部的顺序号
index = faiss.IndexIDMap(index_flat_l2)
# 将向量数据和对应的 ID 批量添加到索引中
# 从这一刻起,FAISS 就“记住”了这些向量
index.add_with_ids(vectors_np, vector_ids_np)
print(f"\nFAISS 索引已成功创建,共包含 {index.ntotal} 个向量。")
# --- Step 5: 执行搜索并检索元数据 ---
query_text = "我想了解一下迪士尼门票的退款流程"
print(f"\n正在为查询文本生成向量: '{query_text}'")
try:
# 为用户的查询语句生成向量
# 这样才能拿它去和数据库里的向量做比较
query_completion = client.embeddings.create(
model="text-embedding-v4",
input=query_text,
dimensions=1024,
encoding_format="float"
)
# 转换成 FAISS 需要的格式 (1, 1024)
# 注意:这里必须是二维数组,所以外面套了个 []
query_vector = np.array([query_completion.data[0].embedding]).astype('float32')
# 在索引中执行搜索
# index.search(查询向量, 返回数量k)
# 返回两个数组:
# distances: 每个匹配项的距离(越小越相似)
# retrieved_ids: 每个匹配项对应的 ID
distances, retrieved_ids = index.search(query_vector, k)
print(retrieved_ids,distances)
# --- Step 6: 展示结果 ---
print("\n--- 搜索结果 ---")
# retrieved_ids 是因为返回的是一个批次的结果,我们只查了一条,所以取第 0 行
for i in range(k):
doc_id = retrieved_ids[0][i] # 取出第 i 个最相似的文档 ID
# 检查 ID 是否有效
# 如果数据库里数据不够,FAISS 可能会返回 -1
if doc_id == -1:
print(f"\n排名 {i + 1}: 未找到更多结果。")
continue
# 使用找到的 ID,去我们之前的“原文收纳盒”(metadata_store) 里把内容翻出来
# 这是 RAG(检索增强生成)中最关键的一步:把数学计算的结果翻译回人类语言
retrieved_doc = metadata_store[doc_id]
print(f"\n--- 排名 {i + 1} (距离: {distances[0][i]:.4f}) ---")
print(f"ID: {doc_id}")
print(f"原始文本: {retrieved_doc['text']}")
print(f"元数据: {retrieved_doc['metadata']}")
except Exception as e:
print(f"执行搜索时发生错误: {e}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
- 如何将Embedding和元数据一起存储在FAISS?
FAISS本身只存储和检索向量,不存储元数据。=>我们需要在FAISS之外维护一个元数据的“查找表”,并通过向量在FAISS中的唯一ID将两者关联起来。
最直接有效的方法是使用FAISS的IndexIDMap=>允许我们为每个向量指定一个自定义的、唯一的64位整数ID。然后,可以用这个ID作为元数据存储的键。
# 总结实现步骤
准备数据:创建示例文本和对应的元数据。
生成向量:基于百炼text-embedding-v4生成每个文本的向量。
创建元数据存储:使用一个简单的Python列表来存储元数据。列表的索引将作为每个数据点的唯一ID。
构建FAISS索引:
- 使用faiss.IndexFlatL2创建一个基础的索引=>这里使用L2距离(欧氏距离)进行精确搜索。
- 用faiss.IndexIDMap将基础索引包装起来=>这样就可以添加带有自定义ID的向量了。
添加数据到索引:将生成的向量和对应的ID(即元数据列表的索引)添加到IndexIDMap中。
执行搜索:
- 对一个新的查询文本生成向量。
- 在FAISS索引中搜索最相似的向量。
- FAISS会返回最相似向量的ID。
- 检索元数据:
使用返回的ID,从元数据存储中查找到原始文本和元数据。
- 如何将metadata元数据管理的更健壮?
在更复杂的生产环境中,可以将metadata_store这个简单的列表替换为更健壮的存储方案: - 键值数据库(如Redis):通过ID快速查询,性能极高。
- 关系型数据库(如PostgreSQL):可以存储更复杂的结构化元数据。
- 文档数据库(如MongoDB):非常适合存储JSON格式的元数据。
提示
FAISS专注于其最擅长的高速向量检索,而元数据的存储和管理可以交给专业的数据库系统负责,实现了架构上的解耦和高效协同。
# 向量数据库选择