
AI大模型原理与API使用
# 什么是AI
AI的本质就是让机器具备人的能力
起源:人工智能(Artificial Intelligence)一词最早在1956年会议上提出
AI的核心目标是让机器能够执行通常需要人类智能的任务,例如语言理解、图像识别、复杂问题解决等
早期阶段:以规则为基础的专家系统,依赖预设的逻辑和规则。
- 定义:基于人工设计规则的硬编码系统
- 典型案例:
- 1970年代无人驾驶系统:通过编码交通规则(如红灯停车、避让直行车辆)
- 局限性:无法处理未预见的突发情况,规则难以穷举
- 本质:依赖人工经验规则的集合
机器学习时代:通过数据训练模型,使机器能够从数据中学习规律。
- 突破:机器从数据中自主寻找规律
- 典型应用:
- 房价预测:通过面积、区位、配套等特征学习定价规律
- 参数特点:参数量级在几十到上千个
深度学习时代:利用神经网络模拟人脑的复杂结构,处理更复杂的任务。
- 网络结构:模拟人脑神经元连接
- 参数量级:数万到数百万
- 典型应用:
- 推荐系统
- 图像识别处理
大模型时代:以大规模数据和算力为基础,构建通用性强、性能卓越的AI模型
- 参数量级:万亿级(如K2模型达1TB参数量)
- 三大支柱:
- GPU算力(如H20芯片)
- 海量数据(如GPT-3.5训练数据达45TB)
- 大模型架构
- 发展规律:从人工规则→数据标注学习→海量自主学习
# AI的分类
分析式AI
- 也称为判别式AI,其核心任务是对已有数据进行分类、预测或决策。
- 优势在于其高精度和高效性,但其局限性在于仅能处理已有数据的模式,无法创造新内容。
生成式AI
- 专注于创造新内容,例如文本、图像、音频等。
- 突破在于其创造性和灵活性,但也面临数据隐私、版权保护等挑战
# 大语言模型LLM
- LLM是基于海量文本数据训练的深度学习模型,属于生成式AI的一种。它能理解和生成类人类的自然语言,常见模型如GPT系列、DeepSeek, Qwen等。
- 具备强大的文本理解、摘要、翻译、问答及内容创作能力。通过上下文关联,能进行连贯且富有逻辑的对话与写作。并且通过少量示例可以进行下游任务的学习。
场景示例:
- 智能客服: 电商网站导入基于LLM的聊天机器人,能即时理解客户复杂的售后问题,提供个性化的解决方案,大幅提升服务效率与客户满意度。
- 内容创作: 营销团队使用LLM,输入产品关键字和目标受众,快速生成多版本的广告文案、社交媒体帖文与博客文章,有效降低人力成本。
# 生图/生视频模型
专门将文字描述转换为全新的图像或视频。它们学习了图像、视频与其对应文字标签之间的关联,代表模型有DALL-E、Midjourney及Sora。
- 能够根据用户输入的文字提示(Prompt),创造出符合描述且风格多样的视觉内容。模型能融合不同概念、属性和风格,生成前所未有的原创作品。
场景示例:
- 产品设计: 设计师输入“一款具有未来感的流线型运动跑鞋,采用回收海洋塑料材质”,模型可快速生成多款概念图,加速产品可视化与迭代过程。
- 影视预览: 导演利用文字生成视频模型,将剧本中的关键场景转换为动态预览片段,以便在实际拍摄前,评估镜头、光影和场景布局的可行性。
# 视觉识别模型
- 视觉识别模型让计算机能“看懂”并解析图像与视频内容,属于计算机视觉领域。主要任务包括图像分类、物体检测、图像分割等,模型如YOLO、ResNet。
- 能准确辨识影像中的物体、人脸、文字或特定场景。其核心在于从像素中提取特征,并与已知模式进行比对,以完成识别、定位或追踪等任务。
场景示例:
- 智能制造: 在生产线上部署视觉识别系统,能即时检测产品外观的微小瑕疵,如刮痕或缺件,自动剔除不合格品,确保出厂品质,准确率远超人眼。
- 医疗影像分析: 医院导入AI辅助判读系统,分析X光或CT扫描影像。模型能快速标记出疑似肿瘤或病变的区域,协助放射科医生提高诊断效率与准确性。
# 自动驾驶模型
一套复杂的AI系统,整合了视觉识别、传感器融合、决策规划等多种模型。其目标是让车辆在无需人类干预下安全行驶,是AI技术的高度整合应用。
- 通过摄像头、激光雷达(LiDAR)等传感器,即时感知周遭环境,识别行人、车辆与交通标志。模型会预测其他物体的动态,并规划出最佳的行驶路径与操作。
场景示例:
- 无人配送: 物流公司采用自动驾驶货车,在特定园区或高速公路进行货物运输。系统能自主导航、避开障碍物并遵守交通规则,实现24小时不间断的物流运作。
- 高级辅助驾驶: 现今许多市售车辆搭载的辅助驾驶系统,能在高速公路上自动跟车、维持车道居中。这背后就是自动驾驶模型在识别车道线与前车距离,并控制方向盘与加减速。
# 大语言模型
大语言模型是一种通用自然语言生成模型,使用大量预料数据训练,以事现生成文本,回答问题,对话生成等
# ChatGPT是如何训练出来的
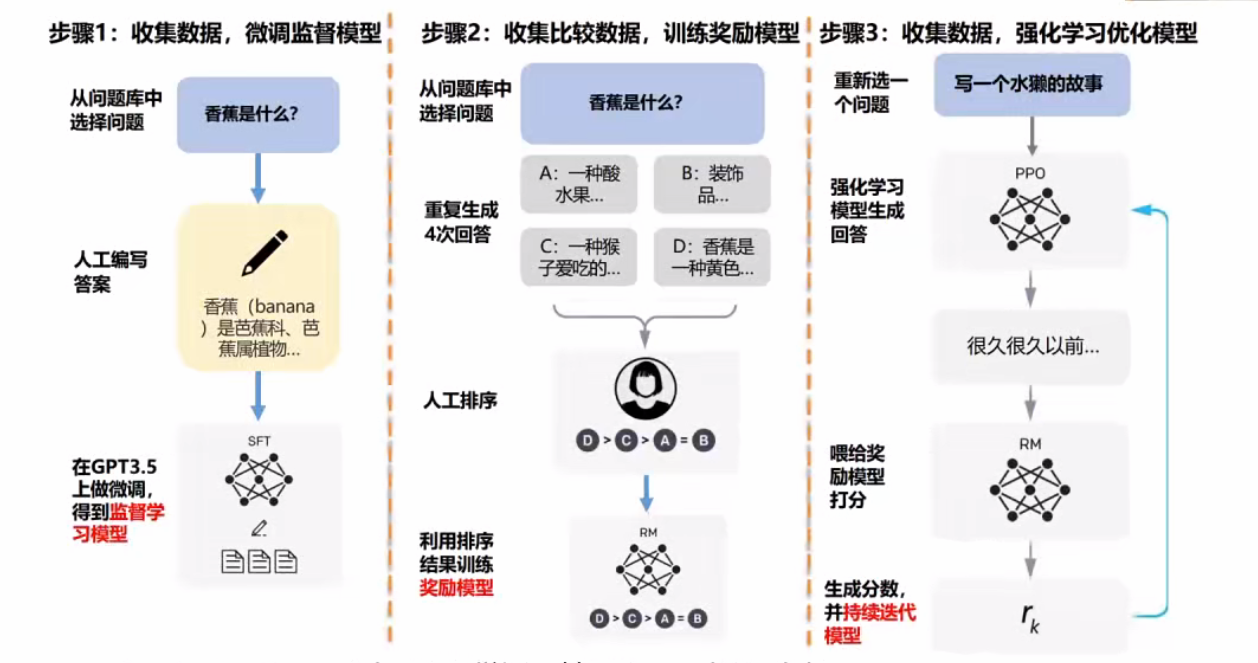
监督学习阶段:
- 数据量:使用45TB语料(相当于1000万本书)
- 方法:人工标注标准答案(如"香蕉是芭蕉科植物")
- 效果:快速实现从0到60分的基础能力建立
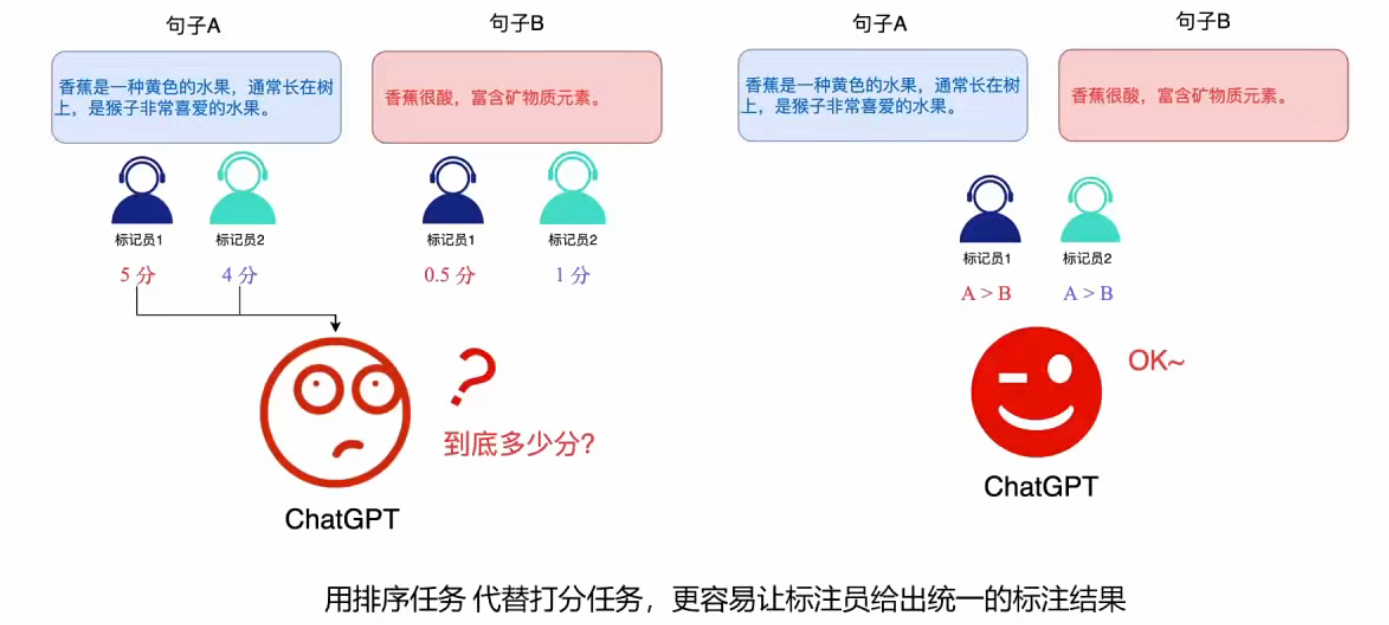
奖励模型阶段:
- 核心方法:强化学习(RLHF),让AI生成多个答案由人工排序
- 标注成本:肯尼亚标注员时薪2美元,采用Rank List代替打分
- 优势:解决开放性问题,鼓励创新答案
优化阶段:
- PPO算法:基于奖励模型持续优化生成质量
- 案例:水獭故事生成任务展示泛化能力
# ChatGPT的优势

- 参数量增长:从GPT的1.17亿到GPT-3的1750亿参数
关键技术:
- 上下文窗口:实现多轮对话记忆
- 知识对齐:通过RLHF理解人类意图
- 安全机制:Rank List自动过滤有害内容
- 局限突破:从特定任务到通用任务的跨越
# 不同语言模型的Token都是如何定义的
Token是大型语言模型处理文本的最小单位。由于模型本身无法直接理解文字,因此需要将文本切分成一个个Token,再将Token转换为数字(向量)进行运算。不同的模型使用不同的“分词器”(Tokenizer)来定Token。
例如,对于英文Hello World:
GPT-4o会切分为[“Hello“, ”World“] =>对应的token id = [13225, 5922]
对于中文“人工智能你好啊”:
DeepSeek-R1会切分为[“人工智能”, “你好”,“啊”] =>对应的token id = [33574, 30594, 3266]
分词方式的不同会直接影响模型的效率和对语言细节的理解能力。
可以通过https://tiktokenizer.vercel.app/这个工具看到不同模型是如何切分你输入的文本的。
# 模型的常见特殊Token
为了让模型更好地理解文本的结构和指令,开发者会预设一些具有特殊功能的Token。
这些Token不代表具体词义,而是作为一种“标点”或“命令”存在。
分隔符(Separator Token):
用于区分不同的文本段落或角色。比如,在对话中区分用户和AI的发言,可能会用<|user|>和<|assistant|>这样的Token。结束符(End-of-Sentence/End-of-Text Token):
告知模型文本已经结束,可以停止生成了。常见的如[EOS]或<|endoftext|>。这对于确保模型生成完整且不冗长的回答至关重要。起始符(Start Token):
标记序列的开始,例如[CLS] (Classification)或[BOS] (Beginning of Sentence),帮助模型准备开始处理文本。
# Temperature、Top P的原理与作用
控制LLM生成文本的多样性,但原理不同。
Temperature (温度):
- 原理:在模型计算出下一个Token所有可能的概率分布后,Temperature会调整这个分布的“平滑度”。
- 高Temperature (如1.0+):会让低概率的Token更容易被选中,使生成结果更具创造性,可能出现不连贯的词语。
- 低Temperature (如0.2):会让高概率的Token权重更大,使生成结果更稳定、更符合训练数据,但会更保守。
Top P (核采样):
- 原理:它设定一个概率阈值(P),然后从高到低累加所有Token的概率,直到总和超过P为止。模型只会在这个累加出来的“核心”词汇表中选择下一个Token。
- 高Top P (如0.9):候选词汇表较大,结果更多样。
- 低Top P (如0.1):候选词汇表非常小,结果更具确定性。
假设模型要完成句子:“今天天气真...”
模型预测的下一个词可能是:好(60%)、不错(30%)、糟(9%)、可乐(0.01%)。
高Temperature:会提升所有词的概率,使得“可乐”这个不相关的词也有机会被选中。
Top P (设为0.9):会选择概率总和达到90%的词。这里 好(60%) +不错(30%) = 90%,所以模型只会从“好”和“不错”中选择,直接排除了“可乐”这种离谱的选项。
相比Temperature,Top P能更动态地调整候选词的数量,避免选到概率极低的离谱词汇=>产生更高质量的文本。
# AI大模型聊天产品的“超能力”
超能力1:联网搜索
弥补LLM训练数据截止日期的限制=>获取外部信息
当用户提问涉及最新资讯时,系统会识别出这一需求,自动调用搜索Tool,并将问题转化为多个简洁的搜索关键词。
接着,程序调用搜索引擎API(如Google搜索)获取信息。
最后,这些实时信息会作为上下文提供给模型,由模型进行总结和提炼,生成精准且与时俱进的回答。例如,当你询问“黄金的涨跌和哪些因素有关?” LLM会调用一个搜索工具,输入你刚才的问题,然后获取相关的信息=>整理到回答中。
超能力2:读取文件
基于“检索增强生成”(Retrieval-Augmented Generation, RAG)的技术。
当你上传一个文件(如PDF、Word文档)时,系统首先会将其内容分割成小块(Chunks)(阿里内部推荐size≈500)。
然后,通过Embedding技术将这些文本块转化为数学向量,并存储在专门的“向量数据库”中。当你针对文件内容提问时,系统会将你的问题也转化为向量,并在数据库中快速找到最相关的文本块,
最后将这些文本块连同你的问题一起交给模型,生成答案。
比如,上传一份公司财报后,提问“第二季度的利润是多少?”
RAG系统能精确定位到财报中相关的片段,让LLM直接使用。超能力3:记忆功能(从“金鱼”到“伙伴”) LLM本身是无状态的,每次对话都是一次全新的互动,不记得之前的交流。
为了实现“记忆”,系统会在每次对话时,将最近的几轮问答作为背景信息一起发送给模型=>称为“短期记忆”或“上下文窗口”。对于需要长期记住的关键信息,例如你的名字或偏好,系统会通过特定算法提取这些信息,
=>将其存储在用户专属的数据库中。
=>在后续的对话中,系统会先从数据库中读取,为模型提供更个性化的背景知识。比如,你告诉AI“我喜欢简洁的回答风格”,系统会记录这一偏好。
下次你提问时,它就会倾向于给出更简练的答复。
# API使用
# 全球AI发展现状
全球AI模型发展现状(中美对比):
- 美国:OpenAI、Anthropic、Google、Meta等公司主导前沿模型,如GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash。
- 中国:DeepSeek(如R1、V3)、阿里巴巴(如Qwen3)、Moonshot等公司快速追赶,部分模型(如Kimi K2,DeepSeek R1)已接近美国前沿水平。
关键趋势:中国模型在2024年显著缩小与美国的差距,尤其在推理模型和开源模型领域表现突出。 - 其他地区:法国(Mistral)、加拿大(Cohere)等也有前沿模型,但中美仍是主导力量。
# 出口限制与硬件影响
美国对华限制:
- 时间线:2022年10月首次限制(H100、A100),2023年10月升级(H800、A800受限),2025年1月新增“AI扩散规则”。
- 当前状态:仅H20、L20等低性能芯片可出口中国,未来可能进一步收紧。
- 影响:中国依赖国产芯片(如华为昇腾)或降级版NVIDIA芯片(如H20,算力仅为H100的15%)。
硬件性能对比:
- NVIDIA H100:989 TFLOPs,3.35 TB/s带宽。
- NVIDIA H20:148 TFLOPs,4 TB/s带宽(专为中国市场设计)。
- AMD MI300X:1307 TFLOPs,5.3 TB/s带宽(未受限制)。
AI扩散规则(AI Diffusion Rule)是美国对华芯片出口管制政策的进一步升级,目的在通过三级许可框架 严格限制先进AI加速器流向中国及其他特定国家。
# 中国AI公司概览
大科技公司:
- 阿里巴巴:通义千问(Qwen)系列,Qwen3
- 百度:文心一言(Ernie 4.0 Turbo)
- 腾讯:混元大模型(HunyuanLarge)
- 字节跳动:豆包(Doubao1.6 Pro)
- 华为:盘古5.0(Pangu 5.0 Large)
初创公司:
- DeepSeek:R1、V3,开源模型表现优异。
- Moonshot:Kimi K2,专注长上下文窗口。
- MiniMax:Text-01,多模态能力突出。
- 其他:智谱AI(ChatGLM)、百川智能(Baichuan)等。
# 案例:情感分析-Qwen
- 对用户观点评论进行情感分析,即正向、负向
使用dashscope中的Qwen-Turbo
针对提取的用户评论,可以进行批量化分析
- 进入阿里云百炼的官网https://bailian.console.aliyun.com/ (opens new window)
- 生成API Key
- 安装dashscope
import json
import os
# dashscope这个工具箱可以让你更好的访问到阿里里面的模型,是阿里开源的调用模型的
import dashscope
from dashscope.api_entities.dashscope_response import Role
# 这里使用我们刚刚申请的百炼的api key
api_key = "******"
dashscope.api_key = api_key
# 封装模型响应函数
def get_response(messages):
# dashscope.Generation.call 可以调用model
response = dashscope.Generation.call(
model='qwen-turbo', # turbo比较快
messages=messages,
result_format='message' # 将输出设置为message形式
)
return response
review = '这款音效特别好 给你意想不到的音质。'
messages = [
{"role": "system", "content": "你是一名舆情分析师,帮我判断产品口碑的正负向,回复请用一个词语:正向 或者 负向"},
{"role": "user", "content": review}
]
response = get_response(messages)
print(response.output.choices[0].message.content)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
什么是DashScopeAPI?
DashScope是阿里云提供的模型即服务(Model-as-a-Service)平台API。集合了多种AI大模型(比如这里使用的qwen-turbo)如何使用这个API?
首先,需要通过pip installdashscope安装函数库。
然后,设置API密钥。再按照规定的格式准备输入消息(messages),
最后调用dashscope.Generation.call()函数,即可向指定的模型发送请求并获得回复。调用参数(call函数)有哪些?
- model:指定使用的模型,例如'deepseek-v3'。
- messages:传递给模型的对话内容,是一个包含多个字典的列表,每个字典代表一则消息。
- messages是一个列表,其中每个元素都是一个字典,包含role和content两个键。
- role:角色,可以是'system' (系统指示)、'user' (用户提问)或'assistant’ (AI回复)。
- content:该角色说的具体内容。
- result_format:设定返回结果的格式。此处'message'表示标准化的消息对象格式。
响应参数(response对象)包含什么?
API的响应是一个对象。我们主要关注response.output.choices[0].message.content。这层层深入的路径,代表从模型众多可能的响应(choices)中,取出第一个([0]),并读取其消息(message)中的实际文本内容
# DashScope使用方法
1、基本设置:
import dashscope
from dashscope.api_entities.dashscope_responseimport Role
#设置API key
dashscope.api_key= "your-api-key"
2
3
4
2、模型调用:
#基本调用格式
response =dashscope.Generation.call(
model='模型名称',#例如:'qwen-turbo', 'deepseek-r1'等
messages=messages,#消息列表
result_format='message' #输出格式
)
2
3
4
5
6
3、messages格式:
messages = [
{"role": "system", "content": "系统提示信息"},
{"role": "user", "content": "用户输入"},
#如果有历史对话
{"role": "assistant", "content": "助手回复"},
{"role": "user", "content": "用户新的输入"}
]
2
3
4
5
6
7
4、常用参数:
response =dashscope.Generation.call(
model='模型名称',
messages=messages,
result_format='message', #输出格式
temperature=0.7,#温度参数,控制随机性
top_p=0.8,#控制输出的多样性
max_tokens=1500,#最大输出长度
stream=False#是否使用流式输出
)
2
3
4
5
6
7
8
9
5、获取响应结果
#获取生成的文本
result =response.output.choices[0].message.content
#如果是流式输出
for chunk in response:
print(chunk.output.choices[0].message.content, end='')
2
3
4
5
# 系统提示词与用户提示词
系统提示词(System Prompt)
- 用于设定AI的角色、行为准则和输出格式,是贯穿对话的全局指令,为其提供了扮演的“人设”。
- 应在对话开始时设定,内容要清晰明确。
- 它会像普通问题一样消耗Token,不应在其中包含用户的具体问题。频繁更改可能导致AI行为不稳定。
如何要打造一个代码助手,如何设定系统提示词?
你是一个资深程序员,请直接提供代码,并用Markdown格式包裹。不要解释,不要说任何无关的话。
# LLM的输入与输出Token限制
输入Token限制
- 模型单次API调用能处理的最大信息量,包含系统提示词、历史对话和当前用户输入的所有内容。
- 所有输入内容的总长度不能超过此限制,否则API会报错。
- 我们需自行管理历史对话长度,比如通过截断或总结旧消息来确保请求不超过上限。
假设某模型上限为4096 Token(Context Window)。如果此时系统提示词和历史对话已占用3500 Token
=>那么用户提示词长度不能超过4096-3500 = 596 Token。
输出Token限制
- 指模型在一次回复中能生成的最大内容长度。
- 我们通常可以在API请求中手动设置此参数(如max_output_tokens)。
- 设置过低会导致回答不完整,内容被突然截断;
- 设置过高则可能增加API调用时间和费用。需要根据具体任务需求权衡。
如果你请求模型写一首诗,但将输出限制设为5 Token,那么可能只会得到诗的第一句,后面内容会被截断。
# 案例:Function Call使用-Qwen
编写一个天气Function,当LLM要查询天气的时候提供该服务,比如当前不同城市的气温为:
北京:35度
上海:36度
深圳:37度
天气均为晴天,微风
- 使用model= "qwen-max"
- 编写functionget_current_weather
对于用户询问指定地点的天气,可以获取该地当前天气
import json
import os
import dashscope
from dashscope.api_entities.dashscope_response import Role
# 从环境变量中,获取 DASHSCOPE_API_KEY
api_key = "******"
dashscope.api_key = api_key
# 编写你的天气函数
# 为了演示流程,这里指定了天气的温度,实际上可以调用 高德接口获取实时天气。
# 这里可以先用每个城市的固定天气进行返回,查看大模型的调用情况
def get_current_weather(location, unit="摄氏度"):
# 获取指定地点的天气
temperature = -1
if '大连' in location or 'Dalian' in location:
temperature = 10
if '上海' in location or 'Shanghai' in location:
temperature = 36
if '深圳' in location or 'Shenzhen' in location:
temperature = 37
weather_info = {
"location": location,
"temperature": temperature,
"unit": unit,
"forecast": ["晴天", "微风"],
}
return json.dumps(weather_info)
# 封装模型响应函数
def get_response(messages):
try:
response = dashscope.Generation.call(
model='qwen-max',
messages=messages,
functions=functions,
result_format='message'
)
return response
except Exception as e:
print(f"API调用出错: {str(e)}")
return None
# 使用function call进行QA
def run_conversation():
query = "大连的天气怎样"
messages = [{"role": "user", "content": query}]
# 得到第一次响应
response = get_response(messages)
if not response or not response.output:
print("获取响应失败")
return None
print('response=', response)
message = response.output.choices[0].message
messages.append(message)
print('message=', message)
# Step 2, 判断用户是否要call function
if hasattr(message, 'function_call') and message.function_call:
function_call = message.function_call
tool_name = function_call['name']
# Step 3, 执行function call
arguments = json.loads(function_call['arguments'])
print('arguments=', arguments)
tool_response = get_current_weather(
location=arguments.get('location'),
unit=arguments.get('unit'),
)
tool_info = {"role": "function", "name": tool_name, "content": tool_response}
print('tool_info=', tool_info)
messages.append(tool_info)
print('messages=', messages)
# Step 4, 得到第二次响应
response = get_response(messages)
if not response or not response.output:
print("获取第二次响应失败")
return None
print('response=', response)
message = response.output.choices[0].message
return message
return message
# 这个地方的description,我先用的英文,你可以动手改成中文试试
functions = [
{
'name': 'get_current_weather',
'description': '获取指定地点当前天气。',
'parameters': {
'type': 'object',
'properties': {
'location': {
'type': 'string',
'description': '城市和省,例如:湖南,长沙'
},
'unit': {'type': 'string', 'enum': ['摄氏度', '华氏度']}
},
'required': ['location']
}
}
]
if __name__ == "__main__":
result = run_conversation()
if result:
print("最终结果:", result)
else:
print("对话执行失败")
#response= {"status_code": 200, "request_id": "3bdbecd1-6079-41ef-8bef-c31c21a25c7b", "code": "", "message": "", "output": {"text": null, "finish_reason": null, "choices": [{"finish_reason": "function_call", "message": {"role": "assistant", "content": "", "function_call": {"arguments": "{\"location\": \"大连\"}", "name": "get_current_weather"}}, "index": 0}]}, "usage": {"input_tokens": 271, "output_tokens": 21, "prompt_tokens_details": {"cached_tokens": 0}, "total_tokens": 292}}
#message= {"role": "assistant", "content": "", "function_call": {"arguments": "{\"location\": \"大连\"}", "name": "get_current_weather"}}
#arguments= {'location': '大连'}
#tool_info= {'role': 'function', 'name': 'get_current_weather', 'content': '{"location": "\\u5927\\u8fde", "temperature": 10, "unit": null, "forecast": ["\\u6674\\u5929", "\\u5fae\\u98ce"]}'}
#messages= [{'role': 'user', 'content': '大连的天气怎样'}, Message({'role': 'assistant', 'content': '', 'function_call': {'arguments': '{"location": "大连"}', 'name': 'get_current_weather'}}), {'role': 'function', 'name': 'get_current_weather', 'content': '{"location": "\\u5927\\u8fde", "temperature": 10, "unit": null, "forecast": ["\\u6674\\u5929", "\\u5fae\\u98ce"]}'}]
#response= {"status_code": 200, "request_id": "8ed1f482-451b-4434-ada6-21801801693c", "code": "", "message": "", "output": {"text": null, "finish_reason": null, "choices": [{"finish_reason": "stop", "message": {"role": "assistant", "content": "大连当前的天气情况是10摄氏度,晴天伴有微风。"}, "index": 0}]}, "usage": {"input_tokens": 348, "output_tokens": 21, "prompt_tokens_details": {"cached_tokens": 0}, "total_tokens": 369}}
#最终结果: {"role": "assistant", "content": "大连当前的天气情况是10摄氏度,晴天伴有微风。"}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
整体工作流程:
- 用户输入查询天气的问题
- 模型理解问题,决定需要调用天气查询函数
- 模型生成函数调用参数(城市、温度单位)
- 程序执行函数调用,获取天气数据
- 将天气数据返回给模型
- 模型生成最终的自然语言回答
# 案例:表格提取-Qwen
表格提取与理解是工作中的场景任务,需要使用多模态模型,这里可以使用通义千问VL系列的模型
- Qwen-VL(基础模型)
核心能力:支持图像描述、视觉问答(VQA)、OCR、文档理解和视觉定位 - Qwen-VL-Chat(指令微调版)
基于Qwen-VL进行指令微调(SFT),优化对话交互能力 - Qwen-VL-Plus / Qwen-VL-MAX(升级版) 性能更强,接近GPT-4V水平,但未完全开源
- Qwen2.5-VL(最新旗舰版)
模型规模:提供3B、7B、72B版本,适应不同计算需求
import json
import os
import dashscope
from dashscope.api_entities.dashscope_response import Role
# 从环境变量中,获取 DASHSCOPE_API_KEY
api_key = "******"
dashscope.api_key = api_key
# 封装模型响应函数
def get_response(messages):
response = dashscope.MultiModalConversation.call(
model='qwen-vl-plus',
messages=messages
)
return response
content = [
{'image': 'https://aiwucai.oss-cn-huhehaote.aliyuncs.com/pdf_table.jpg'}, # Either a local path or an url
{'text': '这是一个表格图片,帮我提取里面的内容,输出JSON格式'}
]
messages=[{"role": "user", "content": content}]
# 得到响应
response = get_response(messages)
print(response.output.choices[0].message.content[0]['text'])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
整体工作流程:
- 使用了多模态模型(qwen-vl-plus),可以同时处理图片和文本
- 支持表格识别和内容提取
- 可以将非结构化的表格图片转换为结构化的JSON数据
# 案例:运维事件处置-Qwen
场景描述:运维事件的分析和处置流程。包括告警内容理解,分析方法建议,分析内容自动提取,处置方法推荐和执行等环节。AI大模型可以加速了运维过程中的问题诊断、分析与处置,提高了响应速度和决策质量,降低故障对业务的影响。
运维事件的分析和处置流程。包括告警内容理解,分析方法建议,分析内容自动提取,处置方法推荐和执行等环节,其中:
- 告警内容理解。根据输入的告警信息,结合第三方接口数据,判断当前的异常情况(告警对象、异常模式);
- 分析方法建议。根据当前告警内容,结合应急预案、运维文档和大语言模型自有知识,形成分析方法的建议;
- 分析内容自动提取。根据用户输入的分析内容需求,调用多种第三方接口获取分析数据,并进行总结;
- 处置方法推荐和执行。根据当前上下文的故障场景理解,结合应急预案和第三方接口,形成推荐处置方案,待用户确认后调用第三方接口进行执行。
例子:
- 告警内容理解
假设我们有一个告警信息:
告警:数据库连接数超过设定阈值
时间:2024-08-03 15:30:00
根据这个告警信息,我们可以进行如下分析:
- 告警对象:数据库服务器
- 异常模式:连接数超过设定阈值
- 分析方法建议 结合应急预案、运维文档和大语言模型自有知识,采用以下分析方法:
- 获取实时数据:调用监控系统接口,获取当前数据库服务器的连接数、CPU使用率、内存情况等性能指标。
- 对比历史数据:分析历史数据,确定是否存在正常范围内的波动或者是异常的长期趋势。
- 识别潜在原因:根据数据库连接数异常的时间点、相关日志和监控数据,尝试识别可能导致连接数增加的具体原因,如程序异常、大量查询请求等。
- 分析内容自动提取
根据用户需求,自动调用多种第三方接口获取分析数据,并进行总结,比如:
- 查询性能监控系统接口,获取当前数据库连接数和系统负载情况。
- 检索日志管理系统接口,查看与数据库连接数相关的日志记录。
- 调用事件管理系统接口,获取先前类似事件的解决方案和操作记录。
- 处置方法推荐和执行
基于当前的故障场景理解,结合应急预案和第三方接口数据,可以形成以下处置方案:
- 优化数据库配置:根据实时监控数据,调整数据库连接池的大小和相关参数,以减少连接数超过阈值的风险。
- 排查异常会话:通过数据库管理工具,查找并终止占用大量连接资源的异常会话或查询。
- 系统重启或备份恢复:如果上述措施无效,考虑在非业务高峰时段进行系统重启或者从备份恢复数据库,以恢复正常操作。
"""
1、告警内容理解。根据输入的告警信息,结合第三方接口数据,判断当前的异常情况(告警对象、异常模式);
2、分析方法建议。根据当前告警内容,结合应急预案、运维文档和大语言模型自有知识,形成分析方法的建议;
3、分析内容自动提取。根据用户输入的分析内容需求,调用多种第三方接口获取分析数据,并进行总结;
4、处置方法推荐和执行。根据当前上下文的故障场景理解,结合应急预案和第三方接口,形成推荐处置方案,待用户确认后调用第三方接口进行执行。
"""
import json
import os
import random
import dashscope
from dashscope.api_entities.dashscope_response import Role
# 从环境变量中,获取 DASHSCOPE_API_KEY
api_key = "your api key"
dashscope.api_key = api_key
# 通过第三方接口获取数据库服务器状态
def get_current_status():
# 生成连接数数据
connections = random.randint(10, 100)
# 生成CPU使用率数据
cpu_usage = round(random.uniform(1, 100), 1)
# 生成内存使用率数据
memory_usage = round(random.uniform(10, 100), 1)
status_info = {
"连接数": connections,
"CPU使用率": f"{cpu_usage}%",
"内存使用率": f"{memory_usage}%"
}
return json.dumps(status_info, ensure_ascii=False)
# 封装模型响应函数
def get_response(messages):
response = dashscope.Generation.call(
model='qwen-turbo',
messages=messages,
tools=tools,
result_format='message' # 将输出设置为message形式
)
return response
# 功能:获取当前作用域的局部变量字典
# 用途:用于后续根据函数名称动态查找并调用对应的函数
current_locals = locals()
tools = [
{
"type": "function",
"function": {
"name": "get_current_status",
"description": "调用监控系统接口,获取当前数据库服务器性能指标,包括:连接数、CPU使用率、内存使用率",
"parameters": {
},
"required": []
}
}
]
query = """告警:数据库连接数超过设定阈值
时间:2024-08-03 15:30:00
"""
messages = [
{"role": "system",
"content": "我是运维分析师,用户会告诉我们告警内容。我会基于告警内容,判断当前的异常情况(告警对象、异常模式)"},
{"role": "user", "content": query}]
# In[2]:
while True:
response = get_response(messages)
message = response.output.choices[0].message
messages.append(message)
# print('response=', response)
if response.output.choices[0].finish_reason == 'stop':
break
# 判断用户是否要call function
if message.tool_calls:
# 获取fn_name, fn_arguments
fn_name = message.tool_calls[0]['function']['name']
fn_arguments = message.tool_calls[0]['function']['arguments']
arguments_json = json.loads(fn_arguments)
# print(f'fn_name={fn_name} fn_arguments={fn_arguments}')
function = current_locals[fn_name]
tool_response = function(**arguments_json)
tool_info = {"name": "get_current_weather", "role": "tool", "content": tool_response}
# print('tool_info=', tool_info)
messages.append(tool_info)
# In[6]:
print(messages)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98