
RAG技术与应用
# 大模型应用开发
提示工程VS RAG VS微调,什么时候使用?
- 没问清楚 => 提示工程
- 缺乏背景知识 => RAG
- 能力不足 => 微调
# 什么是RAG
RAG(Retrieval-Augmented Generation):
- 检索增强生成,是一种结合信息检索(Retrieval)和文本生成(Generation)的技术
- RAG技术通过实时检索相关文档或信息,并将其作为上下文输入到生成模型中,从而提高生成结果的时效性和准确性。
# RAG的优势
- 解决知识时效性问题:大模型的训练数据通常是静态的,无法涵盖最新信息,而RAG可以检索外部知识库实时更新信息。
- 减少模型幻觉:通过引入外部知识,RAG能够减少模型生成虚假或不准确内容的可能性。
- 提升专业领域回答质量:RAG能够结合垂直领域的专业知识库,生成更具专业深度的回答
# RAG的核心原理与流程
- 数据预处理
- 知识库构建:收集并整理文档、网页、数据库等多源数据,构建外部知识库。
- 文档分块:将文档切分为适当大小的片段(chunks),以便后续检索。分块策略需要在语义完整性与检索效率之间取得平衡。
- 向量化处理:使用嵌入模型(如BGE、M3E、Chinese-Alpaca-2等)将文本块转换为向量,并存储在向量数据库中
- 检索阶段
- 查询处理:将用户输入的问题转换为向量,并在向量数据库中进行相似度检索,找到最相关的文本片段。
- 重排序:对检索结果进行相关性排序,选择最相关的片段作为生成阶段的输入
- 生成阶段
- 上下文组装:将检索到的文本片段与用户问题结合,形成增强的上下文输入。
- 生成回答:大语言模型基于增强的上下文生成最终回答。
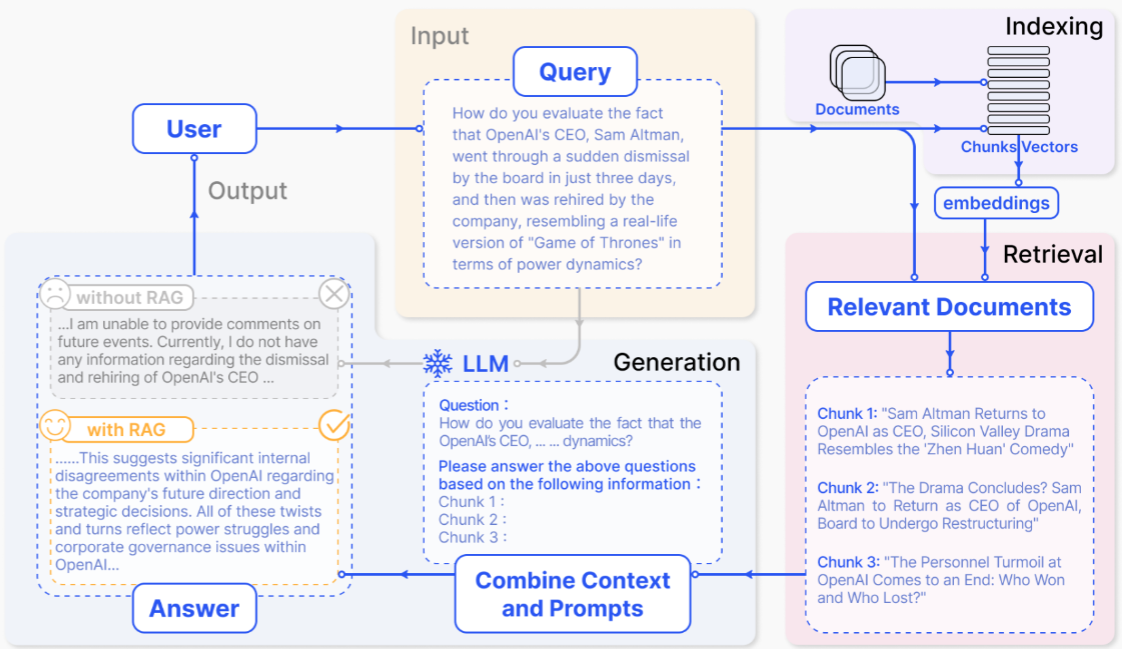
# NativeRAG
RAG的步骤:
- Indexing =>如何更好地把知识存起来。
- Retrieval =>如何在大量的知识中,找到一小部分有用的,给到模型参考。
- Generation =>如何结合用户的提问和检索到的知识,让模型生成有用的答案。
这三个步骤虽然看似简单,但在RAG应用从构建到落地实施的整个过程中,涉及较多复杂的工作内容
对于AI来说,什么格式是最友好的?
markdown
# 文档切分方法
人工切分缺点 效率问题:人工逐篇阅读切分工作量巨大,仅适用于极小规模文本处理
一致性差:人工判断标准难以统一,容易造成切分结果不一致机器切分规则 1)Chunk size设置
参数设定:典型设置如chunk_size=1000,表示每个文本块不超过1000个token
平衡原则:需要权衡信息完整性与处理效率,过大影响检索精度,过小破坏语义连贯
2)Overlap设置
冗余设计:建议设置10%-20%的重叠区域(overlap),防止关键信息被硬切断
补偿机制:重叠部分虽然增加冗余,但能有效避免主题被分割到不同chunk的问题
- 语义切分方法 智能切分:利用大模型分析文本语义,按主题自然切分
进阶方案:
结合文章总结提升切分质量
通过数据清洗优化原始文本
平衡计算成本与切分效果
混合策略:实际应用中常采用规则切分+语义修正的混合方案
# NotebookLM使用
NotebookLM 是一款由 Google 开发的 AI 笔记与研究助手,它能帮助你快速消化和理解复杂的信息。你可以把它想象成一个非常聪明的研究助理,能够基于你提供的资料进行学习、总结和回答问题。
以下是 NotebookLM 的核心功能和使用方法:
# 如何开始使用
- 访问方式:你可以通过网页端访问 NotebookLM 官网,或在手机应用商店下载其移动应用(支持 iOS 和 Android)。
- 创建笔记本:登录后,点击“创建新笔记本”(Create New Notebook)。
- 添加资料:这是最关键的一步。NotebookLM 的核心特点是“以你的资料为本”,它不会随意从网上搜索信息,而是专注于你提供的内容。你可以上传以下类型的文件作为资料来源:
- PDF 文档
- Google Docs / Slides
- 网页链接 (URL)
- YouTube 视频链接
- 直接粘贴的文本
- 开始对话:资料上传完成后,AI 会自动分析并生成一个资料摘要。你可以在底部的对话框中向它提问,它会基于你提供的资料给出回答,并自动标注引用来源。
# 核心功能亮点
NotebookLM 提供了许多强大的功能来提升你的学习和工作效率:
音频概览 (Audio Overviews)
这是 NotebookLM 最受欢迎的功能之一。它可以将你上传的枯燥文档、论文或笔记,自动生成一段类似播客的 AI 对话音频。
效果:由两位 AI 主持人进行自然的对话,有问有答,甚至可以模拟“新手采访专家”或“专家辩论”的形式,让学习过程更轻松有趣。
多语言支持:现已支持包括简体中文在内的多种语言播报。自动生成内容 基于你的资料,NotebookLM 可以快速生成多种格式的内容,帮你理清思路:
- 报告 (Reports):自动生成博客文章、学习指南、常见问题解答 (FAQ) 等。
- 思维导图 (Flowcharts):可视化地展示资料中的核心概念和它们之间的关系。
- 幻灯片 (Slides):自动生成演示文稿,并支持导出为 PPTX 格式。
发现资料 (Discover Sources)
如果你还没有现成的资料,这个功能可以帮助你。你只需输入想研究的主题,NotebookLM 就会利用 Google 的搜索能力,在网上自动查找并推荐相关的高质量资料,你可以一键导入到笔记本中。
# 高效使用技巧
精准提问:为了让 AI 生成更符合你需求的答案,可以尝试在提问时加入具体的角色、背景和格式要求。
例如:你可以对 AI 说:“请扮演一位资深产品经理,根据我上传的竞品分析文档,为我们的新产品 FloraFriend 起草一份包含‘问题陈述’、‘核心功能’和‘成功指标’的产品需求文档(PRD)初稿。” 利用“电影级视频概览”:这是一个更高级的视觉功能。NotebookLM 可以利用先进的 AI 模型,根据你的资料自动生成带有流畅动画和个性化视觉效果的沉浸式讲解视频,让内容呈现更具吸引力。
# 现成的RAG产品
- Cherry Studio
- imacopilot
- NotebookLM (表现最优)
- 钉钉助理
# Embedding模型选择
https://huggingface.co/spaces/mteb/leaderboard (opens new window)比较了1000多种语言中的100多种文本嵌入模型
- 有哪些常见的Embedding模型?
- 通用文本嵌入模型
BGE-M3(智源研究院)
- 特点:支持100+语言,输入长度达8192 tokens,融合密集、稀疏、
- 多向量混合检索,适合跨语言长文档检索。
- 适用场景:跨语言长文档检索、高精度RAG应用。
- 文件大小:2.3G
text-embedding-3-large(OpenAI)
- 特点:向量维度3072,长文本语义捕捉能力强,英文表现优秀。
- 适用场景:英文内容优先的全球化应用。
Jina-embeddings-v2-small(Jina AI)
- 特点:参数量仅35M,支持实时推理(RT<50ms),适合轻量化部署。
- 适用场景:轻量级文本处理、实时推理任务。
- 中文嵌入模型 xiaobu-embedding-v2
- 特点:针对中文语义优化,语义理解能力强。
- 适用场景:中文文本分类、语义检索。
M3E-Base
- 特点:针对中文优化的轻量模型,适合本地私有化部署。
- 适用场景:中文法律、医疗领域检索任务。
- 文件大小:0.4G(m3e-base)
stella-mrl-large-zh-v3.5-1792
- 特点:处理大规模中文数据能力强,捕捉细微语义关系。
- 适用场景:中文文本高级语义分析、自然语言处理任务。
- 指令驱动与复杂任务模型
gte-Qwen2-7B-instruct(阿里巴巴)
- 特点:基于Qwen大模型微调,支持代码与文本跨模态检索。
- 适用场景:复杂指令驱动任务、智能问答系统。
E5-mistral-7B(Microsoft)
- 特点:基于Mistral架构,Zero-shot任务表现优异。
- 适用场景:动态调整语义密度的复杂系统。
- 企业级与复杂系统
BGE-M3(智源研究院)
- 特点:适合企业级部署,支持混合检索。
- 适用场景:企业级语义检索、复杂RAG应用。
E5-mistral-7B(Microsoft)
- 特点:适合企业级部署,支持指令微调。
- 适用场景:需要动态调整语义密度的复杂系统
# CASE: bge-m3使用
# 从 modelscope(魔搭社区,阿里推出的模型开源平台)导入下载工具
from modelscope import snapshot_download
"""
'BAAI/bge-m3': 指定要下载的模型 ID(由北京智源人工智能研究院发布)。
cache_dir='D:/models/modelscope': 指定模型文件保存的本地路径。如果不指定,默认会下载到 C 盘用户目录下。
返回值 model_dir: 返回模型在本地磁盘的具体文件夹路径(例如 'D:/models/modelscope/BAAI/bge-m3'),供后续代码使用。
注意:如果是第一次运行,这行代码会花费较长时间下载几个 GB 的文件;如果已下载过,它会直接检查并返回路径,秒级完成。
"""
model_dir = snapshot_download('BAAI/bge-m3', cache_dir='D:/models/modelscope')
# 从 FlagEmbedding 库中导入专门用于 BGE-M3 模型的类
from FlagEmbedding import BGEM3FlagModel
"""
初始化模型对象。
- 第一个参数: 模型本地的路径(即上面 model_dir 指向的文件夹)。
- use_fp16=True: 关键优化参数。
表示使用 半精度浮点数 (Float 16) 进行计算。
好处:显存占用减少约 50%,推理速度显著提升。
代价:精度会有极微小的损失,但在绝大多数检索和相似度任务中,这种损失可以忽略不计。
注:如果你的显卡不支持 FP16(非常老的卡),这里可能会报错,需改为 False。
"""
model = BGEM3FlagModel('D:/models/modelscope/BAAI/bge-m3',
use_fp16=True)
sentences_1 = ["What is BGE M3?", "Defination of BM25"]
sentences_2 = ["BGE M3 is an embedding model supporting dense retrieval, lexical matching and multi-vector interaction.",
"BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document"]
# 将文本列表转换为向量(Embedding)。
"""
参数详解:
sentences_1: 输入待编码的文本列表。
batch_size=12: 批处理大小。一次送 12 句话进显卡计算。显存大可以调大,显存小调小。
max_length=8192: BGE-M3 的核心特性。它支持超长上下文(最大 8192 token)。
如果你的文本很短(如普通句子),设为 512 或 1024 会更快。
如果你要处理长文档,这个值很有用。
['dense_vecs']:
BGE-M3 是一个多向量模型,它一次编码会返回三种结果:
dense_vecs: 稠密向量(用于传统的语义相似度搜索)。
sparse_vecs: 稀疏向量(用于关键词匹配,类似 BM25)。
colbert_vecs: 多向量交互表示(用于更精细的重排序)。
这里只取了 dense_vecs,即最常用的稠密向量,用于计算余弦相似度。
结果: embeddings_1 是一个 numpy 数组或 tensor,形状约为 (2, 1024)(2 句话,每句 1024 维向量)。
"""
embeddings_1 = model.encode(sentences_1,
batch_size=12,
max_length=8192,
)['dense_vecs']
"""
与上一行完全相同,只是处理的是 sentences_2。
这里省略了 batch_size 和 max_length 参数,意味着使用模型初始化的默认值(通常默认 max_length 也是 8192 或 512,取决于版本配置,但通常不影响短文本)。
"""
embeddings_2 = model.encode(sentences_2)['dense_vecs']
"""
@: Python 中的矩阵乘法运算符。
embeddings_2.T: 对 embeddings_2 进行转置(行列互换)。
embeddings_1 形状: (2, 1024)
embeddings_2 形状: (2, 1024) -> 转置后 -> (1024, 2)
矩阵乘法结果形状: (2, 2)
数学含义:
由于 BGE-M3 输出的向量通常已经做过归一化(L2 Normalization),矩阵乘法等价于计算余弦相似度 (Cosine Similarity)。
结果矩阵中的 similarity[i][j] 代表 sentences_1[i] 和 sentences_2[j] 之间的相似度得分(范围 -1 到 1,越接近 1 越相似)。
"""
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
矩阵乘法
矩阵乘法(Matrix Multiplication)是线性代数的核心,也是深度学习(包括你刚才用的 BGE-M3 模型)的“发动机”。
别被名字吓到,它其实就是一个行与列的配对游戏。我们分三步走:规则、计算过程、直观意义。
- 铁律:什么时候能乘? 矩阵乘法有一个绝对的硬性规定:
前一个矩阵的【列数】必须等于 后一个矩阵的【行数】。
- 矩阵 A 形状:M 行,K列
- 矩阵 B 形状:K 行,N 列
- 中间的两个K必须相等! 就像拼图接口一样,凸出来的是 K,凹进去的也必须是 K。
结果形状: 剩下的两头决定结果:(M, K)×(K, N) = (M, N)。
- 结果的行数 = A 的行数 (M)
- 结果的列数 = B 的列数 (N)
回到你的代码:
embeddings_1: (2, 1024)embeddings_2.T: (1024, 2) (转置后,行变成了 1024)- 中间都是 1024,匹配成功!
- 结果:(2, 2)。
- 怎么算?(手把手演示)
假设我们要算 C = A × B。 核心口诀:左取一行,右取一列,对应相乘,全部相加。
- 举个例子 设矩阵 A 是 (2,3),矩阵 B 是 (3, 2):
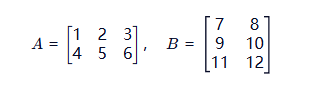
我们要计算结果矩阵 C 中的第一个元素 C11(第1行,第1列):
- 左取一行:取出 A 的第 1 行 [1, 2, 3]
- 右取一列:取出 B 的第 1 列 [7, 9, 11]^T (竖着看)
- 对应相乘:
- 1 × 7 = 7
- 2 × 9 = 18
- 3 × 11 = 33
- 全部相加:7 + 18 + 33 = 58
- 所以,C11 = 58
接下来算 C12(第1行,第2列):
- 左取一行:还是 A 的第 1 行 [1, 2, 3]
- 右取一列:换成 B 的第 2 列 [8, 10, 12]^T
- 对应相乘:
- 1 × 8 = 8
- 2 × 10 = 20
- 3 × 12 = 36
- 全部相加:8 + 20 + 36 = 64
以此类推,算出所有位置。最终结果 C 是 (2 × 2):

- 在 AI 里,这到底意味着什么?
在普通的数学课里,这只是数字游戏。但在你的 BGE-M3 代码里,它有深刻的物理意义:
- A. 它是“加权求和” 矩阵乘法本质上是在做特征的加权组合。
- $A$ 的每一行代表一个样本(一句话)。
- $B$ 的每一列代表一种“过滤器”或“查询”。
- 乘出来的结果,表示这个样本在这个过滤器下的得分。
- B. 它是“相似度计算器” (点积) 在你之前的代码中,因为向量已经被归一化(长度都为1),矩阵乘法就等同于计算余弦相似度。
- 运算逻辑: Score = x_1y_1 + x_2y_2 + ... + x_{1024}y_{1024}
- 直观理解:
- 如果两个向量方向一致(相似),对应的数字同号且大小接近,乘积相加会是一个很大的正数(接近 1)。
- 如果两个向量方向相反(不相似),正负抵消,结果接近 0 或负数。
- 如果两个向量垂直(无关),结果接近 0。
所以,embeddings_1 @ embeddings_2.T 这句话翻译成人话就是:
“请让第一组的每一句话,分别与第二组的每一句话进行特征比对,算出它们的相似程度分数,并填在一个表格里。”
- 为什么要用矩阵乘法而不是写循环?
你可能会想:“我可以用两个 for 循环慢慢算啊,为什么要搞这么复杂的矩阵?”
原因:速度(并行计算)。
CPU/GPU 的特性:显卡(GPU)里有成千上万个核心,它们最擅长的就是同时做大量的“乘加运算”。
循环 (Python):
# 慢!因为要一行一行解释执行 for i in range(2): for j in range(2): sum = 0 for k in range(1024): sum += A[i][k] * B[k][j]1
2
3
4
5
6这像是在让一个工人搬砖,一次搬一块。
矩阵乘法 (NumPy/PyTorch):
C = A @ B1这像是命令1000个工人同时开工,一瞬间就把所有砖搬完了。 在深度学习中,矩阵往往非常大(比如几万维),用循环可能需要几小时,而矩阵乘法只需要几毫秒。
- 总结
- 规则:前列 = 后行。
- 算法:左行 × 右列,对应相乘再相加。
- 意义:在 AI 中,它高效地批量计算了向量之间的相似度或特征的变换。
- 你的代码:利用这个机制,瞬间算出了两组句子之间所有的语义相似度。
# CASE:DeepSeek + Faiss搭建本地知识库检索

- 项目的架构与技术选型是什么?
RAG架构
检索(Retrieval):使用向量相似度搜索从PDF文档中检索相关内容
增强(Augmentation):将检索到的文档片段作为上下文
生成(Generation):基于上下文和用户问题生成答案技术栈选择
向量数据库:Faiss作为高效的向量检索
嵌入模型:阿里云DashScope的text-embedding-v1
大语言模型:deepseek-v3
文档处理:PyPDF2用于PDF文本提取
- 程序的逻辑结构是什么?
Step1:文档预处理
PDF文件→文本提取→文本分割→页码映射
PDF文本提取
•逐页提取文本内容
•记录每行文本对应的页码信息
•处理空页和异常情况文本分割策略
•使用递归字符分割器
•分割参数:chunk_size=1000,chunk_overlap=200
•分割符优先级:段落→句子→空格→字符页码映射处理
•基于字符位置计算每个文本块的页码
•使用众数统计确定文本块的主要来源页码
•建立文本块与页码的映射关系
Step2:知识库构建
文本块→嵌入向量→Faiss索引→本地持久化
向量数据库构建
•使用DashScope嵌入模型生成向量
•将向量存储到Faiss索引结构数据持久化
•保存Faiss索引文件(.faiss)
•保存元数据信息(.pkl)
•保存页码映射关系(page_info.pkl)
Step3:问答查询
用户问题→向量检索→文档组合→LLM生成→答案输出
相似度检索
•将用户问题转换为向量
•在Faiss中搜索最相似的文档块,返回Top-K相关文档问答链处理
•使用LangChain的load_qa_chain
•采用stuff策略组合文档
•将组合后的上下文和问题发送给LLM答案生成与展示
# 用来打开和读取 PDF 文件。
from PyPDF2 import PdfReader
# load_qa_chain: LangChain 的一个功能,用来构建“提问 - 回答”的逻辑链条。
from langchain.chains.question_answering import load_qa_chain
# RecursiveCharacterTextSplitter: 文本切割器。因为 PDF 内容太长,大模型一次读不完,需要切成小块。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# DashScopeEmbeddings: 阿里云的嵌入模型。它的作用是把文字变成一串数字(向量),计算机才能理解文字的语义。
from langchain_community.embeddings import DashScopeEmbeddings
# FAISS: Facebook 开发的向量数据库。用来存储那些数字向量,并能快速搜索“哪段文字和问题最相似”。
from langchain_community.vectorstores import FAISS
# Python 的 typing 模块中导入 List(列表)和 Tuple(元组)
from typing import List, Tuple
import os
# pickle 是 Python 内置的一个模块,用于对象的序列化 (Serialization) 和反序列化 (Deserialization)。
import pickle
DASHSCOPE_API_KEY = 'your api key'
def extract_text_with_page_numbers(pdf) -> Tuple[str, List[int]]:
"""
从PDF中提取文本并记录每个字符对应的页码
参数:
pdf: PDF文件对象
返回:
text: 提取的文本内容
char_page_mapping: 每个字符对应的页码列表
"""
text = ""
char_page_mapping = []
"""
pdf.pages: 获取 PDF 的所有页面对象。
enumerate(..., start=1): 这是一个非常实用的 Python 技巧。
它会同时给出索引(页码)和内容(页面对象)。
start=1 非常重要,因为 PDF 页码通常从 1 开始,而 Python 默认索引从 0 开始。这里强制让 page_number 从 1 开始计数(1, 2, 3...)。
循环过程:每次循环,page_number 是当前页码(如 1),page 是当前页的对象。
"""
for page_number, page in enumerate(pdf.pages, start=1):
# 调用 PyPDF2 的功能,把当前这一页的所有文字提取出来,存到 extracted_text 变量中。
extracted_text = page.extract_text()
if extracted_text:
# 把当前页的文字追加到总文本 text 的末尾。
# 此时,text 变得越来越长,包含了第 1 页、第 2 页...的内容。
text += extracted_text
# 为当前页面的每个字符记录页码
# 这是最精妙的一行!
# len(extracted_text): 算出这一页有多少个字(假设 100 个字)。
# [page_number] * 100: 创建一个列表,里面全是当前的页码。例如,如果是第 5 页,就生成 [5, 5, 5, ..., 5](共 100 个 5)。
# .extend(...): 把这个由 100 个 5 组成的列表,拼接到 char_page_mapping 的末尾。
# 结果:text 增加了 100 个字,char_page_mapping 就增加了 100 个对应的页码 5。两者的位置是一一对应的。
char_page_mapping.extend([page_number] * len(extracted_text))
else:
print(f"No text found on page {page_number}.")
return text, char_page_mapping
def process_text_with_splitter(text: str, char_page_mapping: List[int], save_path: str = None) -> FAISS:
"""
处理文本并创建向量存储
参数:
text: 提取的文本内容
char_page_mapping: 每个字符对应的页码列表
save_path: 可选,保存向量数据库的路径
返回:
knowledgeBase: 基于FAISS的向量存储对象
"""
# 创建文本分割器,用于将长文本分割成小块
"""
RecursiveCharacterTextSplitter:
这是一个非常智能的切割工具。它会尝试按顺序寻找切割点:
先找双换行符 \n\n(段落之间),尽量保持段落完整。
如果段落太长,再找单换行符 \n。
还不行,就找句号 .。
再不行,找空格 。
最后实在没办法,才强制切断字符。
这样切出来的文字块,语义是相对完整的,不会把一句话拦腰截断。
chunk_size=1000:
每个小块的目标长度是 1000 个字符。
chunk_overlap=200:
重叠窗口设为 200。
例子:第一块是第 1-1000 字,第二块不是从 1001 开始,而是从 801 开始(1000-200=800,即 801-1800)。
作用:防止关键信息刚好被切在两块中间,导致上下文丢失。重叠部分保证了语境的连贯性。
"""
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000,
chunk_overlap=200,
length_function=len, # 使用 Python 内置的 len() 函数来计算每一段文字的长度
)
# 分割文本
chunks = text_splitter.split_text(text)
print(f"文本被分割成 {len(chunks)} 个块。")
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 从文本块创建知识库
knowledgeBase = FAISS.from_texts(chunks, embeddings)
print("已从文本块创建知识库。")
# 为每个文本块找到对应的页码信息,因为 FAISS 只存了文字和向量,它不知道这段文字原本在 PDF 的第几页。我们需要手动补上这个信息。
page_info = {}
current_pos = 0
for chunk in chunks:
# 1. 计算当前这块文字在原文中的起止位置
chunk_start = current_pos
chunk_end = current_pos + len(chunk)
# 2. 从总映射表中,切片取出这块文字对应的所有页码
# 假设这块文字长 100 字,我们就取出 100 个页码数字
chunk_pages = char_page_mapping[chunk_start:chunk_end]
# 3. 统计众数 (出现次数最多的页码)
if chunk_pages:
# 统计每个页码出现的次数
page_counts = {}
for page in chunk_pages:
# 查看字典 page_counts 中是否已经记录了 page 这个页码。如果有,就取出它的当前次数并加 1;如果没有(第一次遇到),就默认它是 0,然后加 1(变成 1),最后存回去。
page_counts[page] = page_counts.get(page, 0) + 1
# 找到出现次数最多的页码
"""
page_counts:
这是我们要搜索的对象。它是一个字典,例如 {1: 2, 5: 4, 2: 1}。
注意:当把字典直接传给 max() 时,默认遍历的是字典的键 (Keys),也就是页码 [1, 5, 2]。
max() 函数在比较 [1, 5, 2] 这几个页码谁“最大”时,不再比较页码数字本身(不是比 5 比 2 大),而是比较它们对应的值 (Values)。
page_counts.get 是一个函数。对于每一个页码 p,max() 会调用 page_counts.get(p) 来获取它的计数值。
"""
most_common_page = max(page_counts, key=page_counts.get)
page_info[chunk] = most_common_page
else:
page_info[chunk] = 1 # 默认页码
# 4. 更新指针,准备处理下一块
current_pos = chunk_end
knowledgeBase.page_info = page_info
print(f'页码映射完成,共 {len(page_info)} 个文本块')
# 如果提供了保存路径,则保存向量数据库和页码信息
if save_path:
# 确保目录存在,如果文件夹不存在,就创建一个;如果已经存在,也不报错 (exist_ok=True)。
os.makedirs(save_path, exist_ok=True)
# 保存向量数据库 (FAISS 自带功能)
# 把向量索引保存到硬盘。下次运行程序时,就不用重新计算向量和重新切割了,直接加载,速度极快。
knowledgeBase.save_local(save_path)
print(f"向量数据库已保存到: {save_path}")
# 将 Python 对象 page_info 序列化(打包)并保存为一个二进制文件 page_info.pkl。
# 这是 Python 中持久化存储复杂数据(如字典、列表、自定义对象等)的标准做法。
"""
os.path.join(save_path, "page_info.pkl"):
智能拼接路径。
如果 save_path 是 "./data",结果就是 "./data/page_info.pkl"。
这样做是为了兼容不同操作系统(Windows 用 \,Linux/Mac 用 /)。
"wb":
w (Write): 写入模式。如果文件存在则覆盖,不存在则创建。
b (Binary): 二进制模式。这是关键!pickle 生成的不是给人看的文本,而是机器读的字节流,所以必须加 b。如果不加 b,在 Windows 上可能会因为换行符转换导致数据损坏。
with ... as f:
上下文管理器。确保文件使用完毕后自动关闭,即使中间发生错误也不会导致文件锁死或数据丢失。
f 是这个文件的句柄(手柄),后续操作都通过它进行。
"""
with open(os.path.join(save_path, "page_info.pkl"), "wb") as f:
"""
pickle: Python 内置的序列化模块。它能把几乎任何 Python 对象(字典、列表、类实例等)转换成字节流。
.dump(obj, file):
obj (page_info): 你要保存的数据。在你的代码中,这通常是一个字典,记录了 {文件名: {页码: 内容}} 这样的复杂结构。
file (f): 刚才打开的文件句柄。
动作: 把 page_info “腌制”(Pickle 的原意是腌制)成二进制数据,写入文件 f 中。
"""
pickle.dump(page_info, f)
print(f"页码信息已保存到: {os.path.join(save_path, 'page_info.pkl')}")
return knowledgeBase
def load_knowledge_base(load_path: str, embeddings=None) -> FAISS:
"""
从磁盘加载向量数据库和页码信息
参数:
load_path: 向量数据库的保存路径
embeddings: 可选,嵌入模型。如果为None,将创建一个新的DashScopeEmbeddings实例
返回:
knowledgeBase: 加载的FAISS向量数据库对象
"""
# 如果没有提供嵌入模型,则创建一个新的
# 重要性:这是一致性的关键。如果你保存时用的是 Model A,加载时必须用同样的 Model A(或者至少是输出维度相同的模型),否则向量维度对不上,程序会报错,或者检索结果完全错误。
if embeddings is None:
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
"""
加载FAISS向量数据库,添加allow_dangerous_deserialization=True参数以允许反序列化
FAISS.load_local: LangChain 提供的便捷方法,用于从本地文件夹加载 FAISS 索引(通常包含 index.faiss 和 index.pkl 两个文件)。
背景:FAISS 的元数据(如文档内容、ID映射)通常是用 Python 的 pickle 格式保存的。pickle 有一个著名的安全漏洞:加载恶意构造的 pickle 文件可以执行任意代码。
现状:LangChain 新版本为了安全,默认禁止加载 pickle 文件,除非你显式声明“我知道我在做什么,这个文件是我自己生成的,是安全的”。
含义:这里加上它,就是告诉库:“这个文件是我刚才 save 出去的,我信任它,请解除安全限制并加载它。”如果不加这一行,代码会直接抛出 ValueError 报错。
"""
knowledgeBase = FAISS.load_local(load_path, embeddings, allow_dangerous_deserialization=True)
print(f"向量数据库已从 {load_path} 加载。")
# 加载页码信息
"""
拼接出 page_info.pkl 的路径。
检查文件是否存在(防止第一次运行还没保存过就加载)。
如果存在,用 pickle.load 读取之前保存的字典({文件名: {页码: 内容}} 结构)。
动态绑定属性:knowledgeBase.page_info = page_info。
这是 Python 的动态特性。FAISS 类原本没有 page_info 这个属性,但我们直接给它“贴”上了一个。
目的:这样在后续的检索函数中,可以直接通过 db.page_info 访问这个映射表,从而精准地回答“这句话在第几页”。
容错:如果文件没了,只打印警告,不崩溃,保证数据库主体还能用(只是失去了页码定位功能)。
"""
page_info_path = os.path.join(load_path, "page_info.pkl")
if os.path.exists(page_info_path):
with open(page_info_path, "rb") as f:
page_info = pickle.load(f)
knowledgeBase.page_info = page_info
print("页码信息已加载。")
else:
print("警告: 未找到页码信息文件。")
return knowledgeBase
# # 读取PDF文件
# pdf_reader = PdfReader('./浦发上海浦东发展银行西安分行个金客户经理考核办法.pdf')
# # 提取文本和页码信息
# text, char_page_mapping = extract_text_with_page_numbers(pdf_reader)
# #print('page_numbers=',page_numbers)
#
# print(f"提取的文本长度: {len(text)} 个字符。")
#
# # 处理文本并创建知识库,同时保存到磁盘
# save_dir = "./vector_db"
# knowledgeBase = process_text_with_splitter(text, char_page_mapping, save_path=save_dir)
# 示例:如何加载已保存的向量数据库
# 注释掉以下代码以避免在当前运行中重复加载
# 创建嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
dashscope_api_key=DASHSCOPE_API_KEY,
)
# 从磁盘加载向量数据库
knowledgeBase = load_knowledge_base("./vector_db", embeddings)
# 使用加载的知识库进行查询
#docs = loaded_knowledgeBase.similarity_search("客户经理每年评聘申报时间是怎样的?")
# 直接使用FAISS.load_local方法加载(替代方法)
# loaded_knowledgeBase = FAISS.load_local("./vector_db", embeddings, allow_dangerous_deserialization=True)
# 注意:使用这种方法加载时,需要手动加载页码信息
#这里引入了阿里云的“通义千问”接口,并创建了一个叫 llm (Large Language Model,大语言模型) 的对象。
from langchain_community.llms import Tongyi
llm = Tongyi(model_name="qwen-turbo", dashscope_api_key=DASHSCOPE_API_KEY) # qwen-turbo
# 设置查询问题
#query = "客户经理被投诉了,投诉一次扣多少分"
query = "高级客户经理的个人业绩考核标准"
if query:
# 执行相似度搜索,找到与查询相关的文档
"""
拿着问题去之前加载好的 knowledgeBase (向量数据库) 里找最相关的片段。
关键参数 k=10:意思是“给我找 10 个最相关的文本块”。
原理:
系统把你的问题变成一串数字(向量)。
在数据库里计算这串数字和库里的哪 10 串数字最像。
把那 10 段文字找出来,放进列表 docs 里。
"""
docs = knowledgeBase.similarity_search(query,k=10)
# 加载问答链
"""
创建一个工作流(链条)。
stuff 模式:这是一种策略,意思是“把所有找到的资料塞进提示词里”。
比喻:你把刚才找到的 10 页纸,全部摊开在专家面前,说:“请基于这些材料,回答我的问题。”
"""
chain = load_qa_chain(llm, chain_type="stuff")
# 准备输入数据
input_data = {"input_documents": docs, "question": query}
# 执行问答链
"""
正式执行。把 docs (10 段材料) 和 query (问题) 打包发给 AI。
结果:AI 阅读材料,总结归纳,生成答案,存在 response 变量里。
"""
response = chain.invoke(input=input_data)
print(response["output_text"])
print("来源:")
# 记录唯一的页码
# # 1. 准备一个空集合,用来存页码(集合会自动去重)
unique_pages = set()
# 显示每个文档块的来源页码
for doc in docs:
print('doc=',doc)
text_content = getattr(doc, "page_content", "")
source_page = knowledgeBase.page_info.get(
text_content.strip(), "未知"
)
if source_page not in unique_pages:
unique_pages.add(source_page)
print(f"文本块页码: {source_page}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
# LangChain中的问答链
LangChain问答链中的4种chain_type:
stuff 直接把文档作为prompt输入给OpenAI
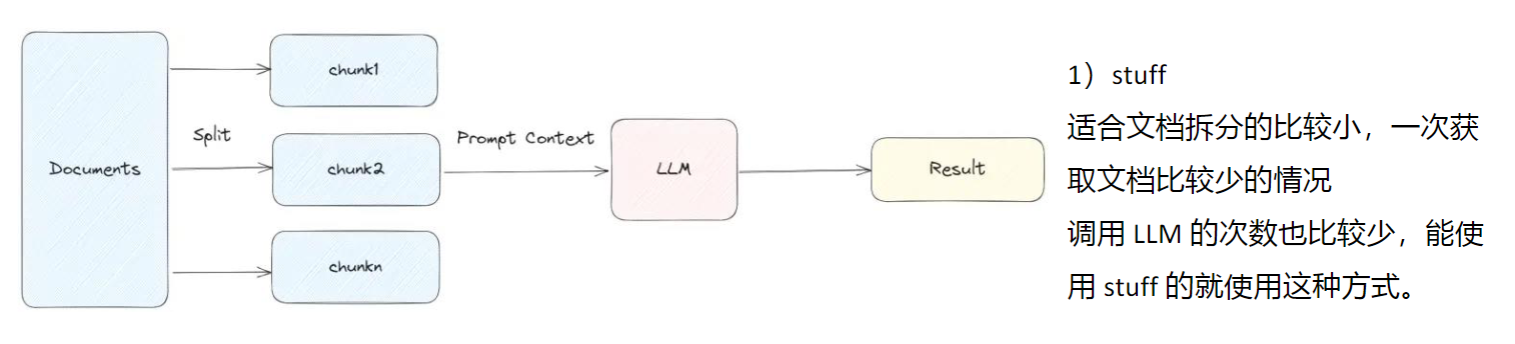
map_reduce
对于每个chunk做一个prompt(回答或者摘要),然后再做合并
refine
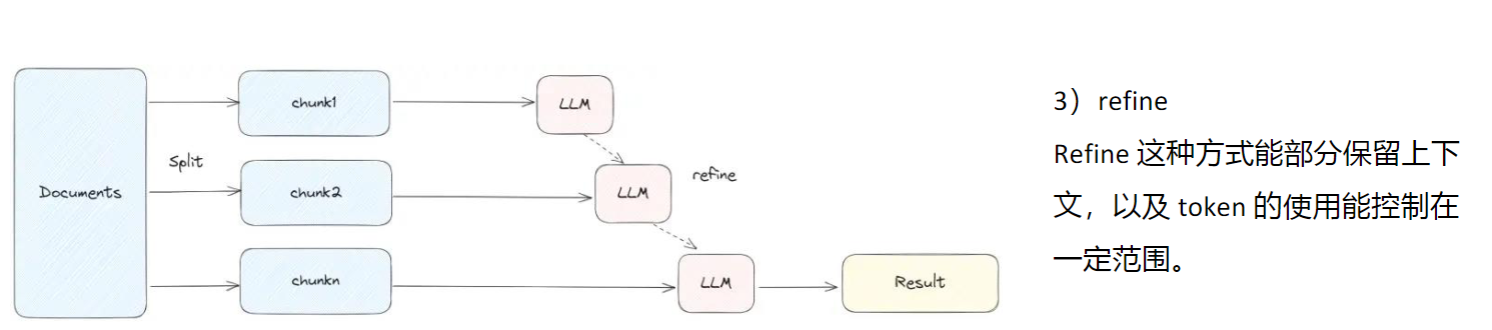
在第一个chunk上做prompt得到结果,然后合并下一个文件再输出结果
map_rerank
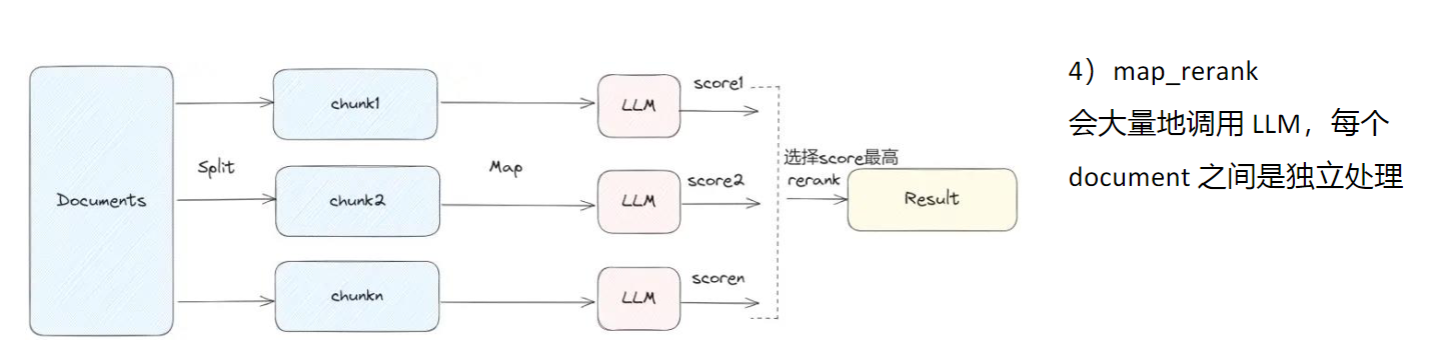
对每个chunk做prompt,然后打个分,然后根据分数返回最好的文档中的结果
如果LLM可以处理无限上下文了,RAG还有意义吗?
效率与成本:LLM处理长上下文时计算资源消耗大,响应时间增加。RAG通过检索相关片段,减少输入长度。
知识更新:LLM的知识截止于训练数据,无法实时更新。RAG可以连接外部知识库,增强时效性。
可解释性:RAG的检索过程透明,用户可查看来源,增强信任。LLM的生成过程则较难追溯。
定制化:RAG可针对特定领域定制检索系统,提供更精准的结果,而LLM的通用性可能无法满足特定需求。
数据隐私:RAG允许在本地或私有数据源上检索,避免敏感数据上传云端,适合隐私要求高的场景。
=>结合LLM的生成能力和RAG的检索能力,可以提升整体性能,提供更全面、准确的回答。
# RAG常见问题——如何提升RAG质量
# 数据准备阶段
- 数据质量差:企业大部分数据(尤其是非结构化数据)缺乏良好的数据治理,未经标记/评估的非结构化数据可能包含敏感、过时、矛盾或不正确的信息。
- 多模态信息:提取、定义和理解文档中的不同内容元素,如标题、配色方案、图像和标签等存在挑战。
- 复杂的PDF提取:PDF是为人类阅读而设计的,机器解析起来非常复杂。
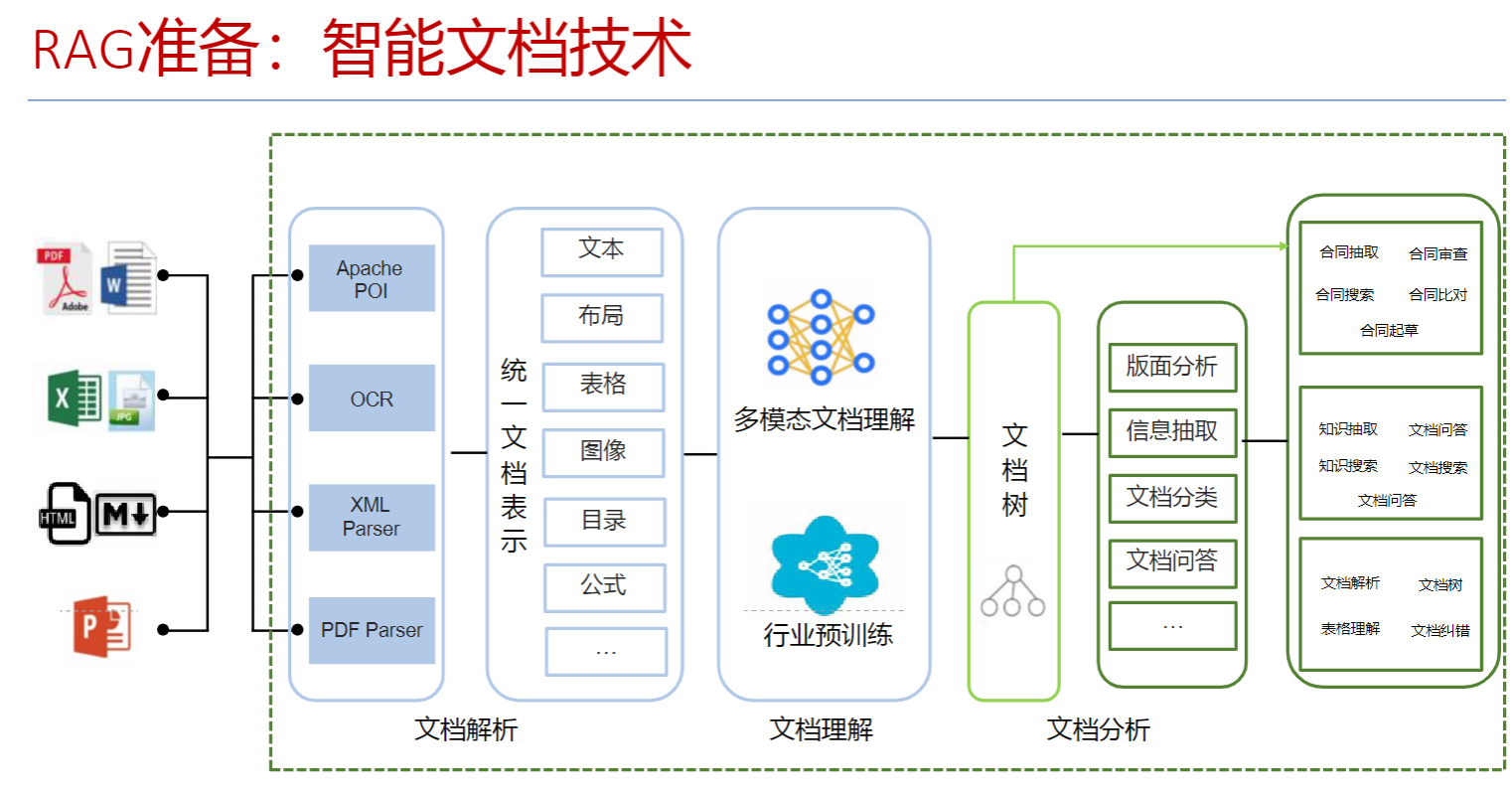
如何提升数据准备阶段的质量?
- 构建完整的数据准备流程
- 智能文档技术
构建完整的数据准备流程
- 数据评估与分类
数据审计:全面审查现有数据,识别敏感、过时、矛盾或不准确的信息。
数据分类:按类型、来源、敏感性和重要性对数据进行分类,便于后续处理
识别敏感信息,比如:
客户姓名、身份证号、手机号、银行账号、交易记录等个人身份信息(PII)。
信用卡号、CVV码、有效期等支付信息。
发现问题:
这些信息可能未经加密存储,存在泄露风险。
部分数据可能被未授权人员访问。识别过时信息,比如: 客户地址、联系方式未及时更新。已结清的贷款或信用卡账户仍被标记为“活跃”。
发现问题: 过时信息可能导致客户沟通失败或决策错误。
- 数据清洗
- 去重:删除重复数据。
- 纠错:修正格式错误、拼写错误等。
- 更新:替换过时信息,确保数据时效性。
- 一致性检查:解决数据矛盾,确保逻辑一致。
- 敏感信息处理
- 识别敏感数据:使用工具或正则表达式识别敏感信息,如个人身份信息(PII)。
- 脱敏或加密:对敏感数据进行脱敏处理,确保合规。
- 数据标记与标注
- 元数据标记:为数据添加元数据,如来源、创建时间等。
- 内容标注:对非结构化数据进行标注,便于后续检索和分析。
- 数据治理框架
- 制定政策:明确数据管理、访问控制和更新流程。
- 责任分配:指定数据治理负责人,确保政策执行。
- 监控与审计:定期监控数据质量,进行审计。
# 知识检索阶段
- 内容缺失:当检索过程缺少关键内容时,系统会提供不完整的答案=>降低RAG的质量
- 错过排名靠前的文档:用户查询相关的文档时被检索到,但相关性极低。因为在检索过程中,用户通过主观判断决定检索“文档数量”。理论上所有文档都要被排序并考虑进一步处理,但在实践中,通常只有排名top k的文档才会被召回,而k值需要根据经验确定。
如何提升知识检索阶段的质量?
- 通过查询转换澄清用户意图。
- 采用混合检索和重排策略。
1.查询转换澄清用户意图
场景:用户询问“如何申请信用卡?”
问题:用户意图可能模糊,例如不清楚是申请流程、所需材料还是资格条件。
解决方法:通过查询转换明确用户意图。
步骤:
- 意图识别:使用自然语言处理技术识别用户意图。例如,识别用户是想了解流程、材料还是资格。
- 查询扩展:根据识别结果扩展查询。例如:
如果用户想了解流程,查询扩展为“信用卡申请的具体步骤”。
如果用户想了解材料,查询扩展为“申请信用卡需要哪些材料”。
如果用户想了解资格,查询扩展为“申请信用卡的资格条件”。 - 检索:使用扩展后的查询检索相关文档。
示例:
- 用户输入:“如何申请信用卡?”
- 系统识别意图为“流程”,扩展查询为“信用卡申请的具体步骤”。
- 检索结果包含详细的申请步骤文档,系统生成准确答案。
2. 混合检索和重排策略
场景:用户询问“信用卡年费是多少?”
问题:直接检索可能返回大量文档,部分相关但排名低,导致答案不准确。
解决方法:采用混合检索+重排策略。
步骤:
- 混合检索:结合关键词检索和语义检索。比如:关键词检索:“信用卡年费”。语义检索:使用嵌入模型检索与“信用卡年费”语义相近的文档。
- 重排:对检索结果进行重排
- 生成答案:从重排后的文档中生成答案
示例:
- 用户输入:“信用卡年费是多少?”
- 系统进行混合检索,结合关键词和语义检索。
- 重排后,最相关的文档(如“信用卡年费政策”)排名靠前。
- 系统生成准确答案:“信用卡年费根据卡类型不同,普通卡年费为100元,金卡为300元,白金卡为1000元。
# 答案生成阶段
- 未提取:正确答案出现在所提供的上下文中,但LLM却没有准确提取。这种情况通常发生在上下文中存在过多噪音或存在冲突的信息。
- 不完整:尽管能够利用上下文生成答案,但存在信息缺失,最终导致LLM回答不完整。
- 格式错误:当prompt中的附加指令格式不正确时,LLM可能误解这些指令,从而导致错误的答案。
- 幻觉:大模型可能会产生虚假信息。
如何提升答案生成阶段的质量?
- 改进提示词模板。
- 实施动态防护栏。
改进提示词模板
场景:用户询问“如何申请信用卡?”
原始提示词:“根据以下上下文回答问题:如何申请信用卡?”
改进后的提示词:“根据以下上下文,提取与申请信用卡相关的具体步骤和所需材料:如何申请信用卡?”
场景:用户询问“信用卡的年费是多少?”
原始提示词:“根据以下上下文回答问题:信用卡的年费是多少?”
改进后的提示词:“根据以下上下文,详细列出不同信用卡的年费信息,并说明是否有减免政策:信用卡的年费是多少?”
场景:用户询问“什么是零存整取?”
原始提示词:“根据以下上下文回答问题:什么是零存整取?”
改进后的提示词:“根据以下上下文,准确解释零存整取的定义、特点和适用人群,确保信息真实可靠:什么是零存整取?”
- 如何对原有的提示词进行优化?
可以通过DeepSeek-R1的推理链,对提示词进行优化: - 信息提取:从原始提示词中提取关键信息。
- 需求分析:分析用户的需求,明确用户希望获取的具体信息。
- 提示词优化:根据需求分析的结果,优化提示词,使其更具体、更符合用户的需求。
实施动态防护栏
实施动态防护栏(Dynamic Guardrails)是一种在生成式AI系统中用于实时监控和调整模型输出的机制,目的是确保生成的内容符合预期、准确且安全。它通过设置规则、约束和反馈机制,动态地干预模型的生成过程避免生成错误、不完整、不符合格式要求或有幻觉的内容。
在RAG系统中,动态防护栏的作用尤为重要,因为它可以帮助解决以下问题:
- 未提取:确保模型从上下文中提取了正确的信息。
- 不完整:确保生成的答案覆盖了所有必要的信息。
- 格式错误:确保生成的答案符合指定的格式要求。
- 幻觉:防止模型生成与上下文无关或虚假的信息。
场景1:防止未提取
- 用户问题:“如何申请信用卡?”
- 上下文:包含申请信用卡的步骤和所需材料。
- 动态防护栏规则:
检查生成的答案是否包含“步骤”和“材料”。
如果缺失,提示模型重新生成。示例:
错误输出:“申请信用卡需要提供一些材料。”
防护栏触发:检测到未提取具体步骤,提示模型补充。
场景2:防止不完整
- 用户问题:“信用卡的年费是多少?”
- 上下文:包含不同信用卡的年费信息。
- 动态防护栏规则:检查生成的答案是否列出所有信用卡的年费。如果缺失,提示模型补充。
示例:
错误输出:“信用卡A的年费是100元。”
防护栏触发:检测到未列出所有信用卡的年费,提示模型补充。
场景3:防止幻觉
- 用户问题:“什么是零存整取?”
- 上下文:包含零存整取的定义和特点。
- 动态防护栏规则:检查生成的答案是否与上下文一致。如果不一致,提示模型重新生成。
示例:
错误输出:“零存整取是一种贷款产品。”
防护栏触发:检测到与上下文不一致,提示模型重新生成。
如何实现动态防护栏技术?
事实性校验规则,在生成阶段,设置规则,验证生成内容是否与检索到的知识片段一致。例如,可以使用参考文献验证机制,确保生成内容有可靠来源支持,避免输出不合理的回答。如何制定事实性校验规则?
当业务逻辑明确且规则较为固定时,可以人为定义一组规则,比如:
规则1:生成的答案必须包含检索到的知识片段中的关键实体(如“年费”、“利率”)。
规则2:生成的答案必须符合指定的格式(如步骤列表、表格等)。
实施方法:
使用正则表达式或关键词匹配来检查生成内容是否符合规则。
例如,检查生成内容是否包含“年费”这一关键词,或者是否符合步骤格式(如“1.登录;2.设置”)。
# 在不同阶段提升质量的实践
在数据准备环节,阿里云考虑到文档具有多层标题属性且不同标题之间存在关联性,提出多粒度知识提取方案,按照不同标题级别对文档进行拆分,然后基于Qwen14b模型和RefGPT训练了一个面向知识提取任务的专属模型,对各个粒度的chunk进行知识提取和组合,并通过去重和降噪,保证知识不丢失、不冗余。最终将文档知识提取成多个事实型对话,提升检索效果;
在知识检索环节,哈啰出行采用多路召回的方式,主要是向量召回和搜索召回。其中,向量召回使用了两类,一类是大模型的向量、另一类是传统深度模型向量;搜索召回也是多链路的,包括关键词、ngram等。通过多路召回的方式,可以达到较高的召回查全率。
在答案生成环节,中国移动为了解决事实性不足或逻辑缺失,采用FoRAG两阶段生成策略,首先生成大纲,然后基于大纲扩展生成最终答案。
# 企业级知识管理策略
- 多粒度知识提取
- 实施原因:处理海量知识时存在大小项混合的问题(如银行数十种信用卡产品)
- 分层方法:
- 先处理大项分类(如信用卡大类)
- 再聚焦小项细节(如具体卡种年费)
- 技术类比:类似知识图谱的分层处理逻辑
- 多通路召回机制
- 核心目标:从海量数据(如1000万条)中快速筛选潜在信息(如先召回1000条)
- 实现方式:
- 关键词触发召回:基于传统检索技术
- 向量相似度召回:利用embedding技术
- N元语法召回:捕捉文本局部特征
- 流程设计:先快速召回再精细排序的两阶段处理
- 分阶段答案生成
- 质量提升策略:将生成过程拆分为大纲构建和内容扩写两个阶段
- 优势:
- 解决一次性生成质量不稳定问题
- 允许中间结果校验和调整
- 实施建议:需要设计专门的大纲生成prompt和扩写规则
# 实施建议
# 开源方案选择
千问Agent方案 核心优势:集成召回、重排及生成策略,相比钉钉助理等产品回答质量更优(测试结果显示质量提升约30%)
技术特点:
- 消耗更多token换取质量提升
- 支持结构化数据转SQL查询
- 可扩展添加预处理、意图转换等策略
适用场景:企业级知识库搭建,特别是对数据安全性要求较高的场景Notebook LM方案
产品定位:Google开发的商业级RAG产品
技术架构:
- 使用Gemini embedding模型
- 采用GPT-3.5/4作为推理引擎
- 内置文档概览生成和关键词提取预处理
局限性:不适合涉及敏感数据的场景方案对比 开发灵活性:
LangChain > 千问Agent > Dify+Ragflow > Notebook LM
使用便捷性:
Notebook LM > Dify+Ragflow > 千问Agent > LangChain
数据安全性:
私有化部署方案 > 公有云方案
# 私有化部署
必要性分析 核心驱动因素:数据安全合规要求(特别是上市公司)
典型场景:
- 企业内部标准文档(PDF/Excel/DOC)
- 技术解决方案库
- 客户敏感资料实施路径
技术选型: - 向量数据库:支持本地存储(如FAISS) - 预处理工具链:OCR/表格识别等关键步骤: - 文档分块(chunk size=1000,overlap=100)
- 向量化存储(支持save/load本地文件) - 检索优化(添加元数据如页码、文档来源)
# 策略组合应用
多模态处理策略
图文关联方案: - 预处理阶段统一转为文本(使用LayoutLM等工具)
- 采用概要级chunk保留关联性
- 添加节点聚类机制维护结构关系检索增强策略 分级召回: - 第一级:关键词匹配
- 第二级:向量相似度
- 第三级:知识图谱关联结果重排:
- 基于语义相关性评分
- 结合业务规则加权生成优化策略
提示工程:
- 问题重写(query expansion)
- 上下文压缩(context compression)
结果验证:
- 来源标注(文档名+页码)
- 置信度评估