
Fine-tuning实操
# 李飞飞50美金复刻R1模型
# s1:Simpletest-timescaling
https://arxiv.org/pdf/2501.19393 (opens new window)
李飞飞等研究人员用不到50美元的云计算费用,成功训练出了一个名为s1的推理模型。
- 该模型在数学和编码能力中的表现,与OpenAI的O1和DeepSeek-R1等尖端推理模型不相上下。
- s1模型的训练只用了1000个样本数据,具体过程是:使用Gemini对这1000个样本完善推理过程,然后对Qwen模型进行监督微调。
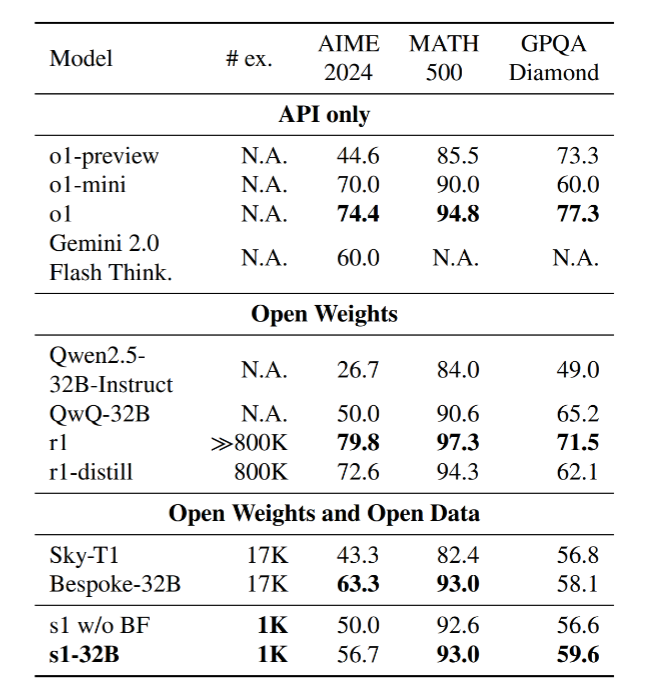
# S1模型方法论:
- 数据集构建(s1K):
从三个标准——难度、多样性和质量——出发,挑选了1000个问题及其对应的推理路径。
数据集包括来自不同领域,如数学竞赛、物理竞赛,并且新增了两个原创的数据集:s1-prob和s1-teasers,分别涵盖了概率问题和定量交易面试中的难题。
- 预算强制(Budget Forcing):
一种控制测试时计算的技术,通过强制终止或延长模型的思考过程(通过添加“Wait”字符串),使模型有机会重新检查答案,从而可能纠正错误的推理步骤。
设定思考时间限制:
当模型开始处理一个问题时,首先为其设定了一个最大思考时间(以token数量衡量)。如果模型在这个时间内完成了思考并准备给出答案,则按照正常流程进行。强制结束思考过程:
如果模型生成的思考token超过了预设的最大值,系统会强行终止模型的思考过程。这通常是通过添加一个特殊的end-of-thinking token delimiter实现的,促使模型停止进一步的推理,并转向生成最终答案。鼓励更深入的探索:
如果希望模型花更多的时间来考虑一个问题,可以抑制end-of-thinking token delimiter的生成,并在当前的推理路径后面追加“Wait”字符串=>为了让模型有机会重新评估其先前的推理步骤,可能会纠正一些快速但不准确的回答。
如何知道每个任务需要多少时间,如何控制这个预算限制的方向(多一些,少一些)?
基于训练数据的分析:
通过分析训练集中的问题,可以估计出不同复杂度的问题所需的平均思考时间。例如,在实验中,将推理路径按照长度(以token数量计)分组,并据此对模型进行提示。基于实验评估的时间调整: 在初步设定的时间预算基础上运行模型,并记录其在各种问题上的表现。这包括准确性和生成的答案长度等指标。基于此决定增加思考时间,还是减少思考时间。
使用分类条件控制:
论文提到了一种叫做“class-conditional control”的方法,它允许用户通过API参数设置不同的“reasoning_effort”级别(低、中、高)。虽然这种方法不能精确控制计算量,但可以根据期望的响应速度和细节水平调整思考时间。
S1整个的训练过程是怎样的?
数据准备:首先,从大约59,000个问题中精心挑选并构建了一个包含1,000个高质量样本的数据集(s1K)。这些样本包含了问题、由Gemini 2.0 Flash Thinking API生成的推理路径以及对应的答案。
模型选择与微调:选择了Qwen2.5-32B-Instruct作为基础模型,并在其上进行了监督微调SFT。这里是将s1K数据集中的问题及其对应的推理路径和答案输入到Qwen2.5-32B-Instruct模型中进行训练。
预算强制技术的应用:在测试阶段,为了控制模型的计算资源使用,采用了“预算强制”技术。
当模型生成的思考token超过设定限制时,通过添加结束思考的标记强制终止思考过程。
如果希望模型花费更多时间思考,则通过追加“Wait”字符串鼓励模型进一步探索。
整个训练是在16个H100 GPU上进行的,耗时约26分钟。
# Unsloth:LLM高效微调
Unsloth https://github.com/unslothai/unsloth (opens new window)
一个高效的开源工具,专注于加速大语言模型(LLMs)的微调和训练过程。
- 高效微调:支持Llama、Mistral、Qwen等主流模型,微调速度比传统方法快2-5倍,内存使用减少50-80%。
- 低显存需求:仅需7GB显存即可训练1.5B参数的模型,15GB显存可支持高达15B参数的模型。
- 集成GRPO算法(群体相对策略优化):增强模型推理能力,比如在无人工提示下解决逻辑问题
- 广泛的模型兼容性:支持多种模型格式(如GGUF、Ollama、vLLM)和量化方法(如QLoRA、LoRA)。
- 开源与免费:提供免费的ColabNotebook,用户只需添加数据集并运行代码即可获得微调模型。
- 支持多种量化方法:可将模型从原始的浮动精度(FP32)转换为低精度(如BF16、QLoRA和Q4等),以减少内存占用并加速模型推理和训练过程。
# CASE:qwen2.5-7B微调(alpaca-cleaned)
yahma/alpaca-cleaned数据集
- Stanford发布的原始Alpaca数据集的清理版本,主要用于LLM的指令微调(Instruct Tuning)。
- 原始数据集:Alpaca-52k,最初用于微调LLaMA模型以生成Alpaca-7B模型,包含约52K条指令数据。
- 清理版本:yahma/alpaca-cleaned是对原Alpaca数据集的优化版本,修复了数据中的瑕疵(如噪声、格式问题)
数据格式(JSON格式)
- instruction:用户输入的指令(必填)。
- input:可选的上下文或补充输入(选填)。
- output:模型应生成的回答(必填)
{
"instruction": "计算这些物品的总费用。",
"input": "汽车-$3000,衣服-$100,书-$20。",
"output": "汽车、衣服和书的总费用为$3000 + $100 + $20 =$3120。"
}
2
3
4
5
# TRLSFTTrainer工具
Hugging Face的TRL (Transformer Reinforcement Learning)库中的SFTTrainer(Supervised Fine-tuning Trainer)是专门设计用于简化Transformer模型监督微调过程的工具。
- SFTTrainer提供了一系列专门为监督微调设计的功能:
内存高效训练:支持参数高效微调技术(PEFT),如LoRA(Low-Rank Adaptation),可以显著减少内存使用量。
数据集处理简化:自动处理常见的数据格式,简化了从原始文本到模型输入的转换过程。它内置了对文本补全任务的支持,这是许多语言模型微调场景中的常见需求。
训练优化:提供了针对语言模型训练的特定优化,如打包(packing)技术,可以将多个短序列合并成一个长序列,提高训练效率。
灵活配置:保留了原始Trainer的所有功能,同时添加了针对监督微调的特定参数和选项
# CASE:训练自己的R1模型
- 安装和初始化
#安装必要的库
!pip installunslothvllm
#导入FastLanguageModel和PatchFastRL
fromunslothimport FastLanguageModel,PatchFastRL
PatchFastRL("GRPO", FastLanguageModel)
2
3
4
5
FastLanguageModel,是unsloth库提供的一个优化过的
LLM加载器和处理器,主要功能:
•提供了更快的模型加载和推理速度
•支持4bit量化加载模型
•集成了vLLM进行快速推理
•支持LoRA(Low-Rank Adaptation)微调
- 模型加载
model, tokenizer =FastLanguageModel.from_pretrained(
model_name= "meta-llama/meta-Llama-3.1-8B-Instruct",
max_seq_length=max_seq_length,
load_in_4bit = True, #使用4bit量化加载
fast_inference= True, #启用vLLM快速推理
max_lora_rank=lora_rank,
gpu_memory_utilization= 0.6, #控制GPU内存使用
)
2
3
4
5
6
7
8
PatchFastRL,是一个用于强化学习(RL)的补丁函数:
•为语言模型添加强化学习相关的功能
•特别支持GRPO (Guided Reward Policy Optimization)算法
•优化模型训练过程
- 数据准备
使用GSM8K数据集进行训练
定义了特定的系统提示格式:
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
2
3
4
5
6
7
8
9
- 奖励函数设计
定义了多个奖励函数来评估模型输出:
•correctness_reward_func:检查答案正确性
•int_reward_func:检查输出是否为整数
•strict_format_reward_func:严格检查输出格式
•soft_format_reward_func:宽松检查输出格式
•xmlcount_reward_func:检查XML标签的正确使用
GSM8K(Grade School Math 8K)是一个高质量的小学数学应用题数据集,主要用于评估和训练人工智能模型
在数学推理和多步问题解决方面的能力https://huggingface.co/datasets/openai/gsm8k (opens new window)
- 训练配置
training_args=GRPOConfig(
use_vllm= True,
learning_rate= 5e-6,
max_steps= 250,
save_steps= 250,
#其他训练参数...
)
2
3
4
5
6
7
- 模型训练
trainer =GRPOTrainer(
model = model,
processing_class= tokenizer,
reward_funcs= [
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func,
],
args= training_args,
train_dataset= dataset,
)
trainer.train()
2
3
4
5
6
7
8
9
10
11
12
13
14
模型保存和导出 提供了多种保存格式:
•16位浮点数格式
•4位量化格式
•LoRA适配器格式
•GGUF格式(用于llama.cpp)推理示例
text =tokenizer.apply_chat_template([
{"role" : "system", "content" : SYSTEM_PROMPT},
{"role" : "user", "content" : "Calculate pi."},
], tokenize = False,add_generation_prompt= True)
2
3
4
用于训练进行结构化推理的大模型,通过特定的格式
(reasoning和answer标签)来输出推理过程和最终答案。
•使用了GRPO训练方法
•采用了LoRA进行高效微调
•支持多种量化和保存格式
•包含了详细的奖励函数设计
# GRPO学习
GRPO(Group Relative Policy Optimization)
•组相对策略优化,是一种用于训练LLM的强化学习算法,是DeepSeek-R1模型的核心技术之一
•GRPO的核心在于通过组内样本的相对奖励来优化策略模型,而不是依赖传统的价值函数模型(如PPO中的批评家模型)。它通过采样一组输出,利用这些输出的奖励值来计算相对优势,从而简化了训练过程。
工作原理:
•采样与奖励计算:对于每个输入问题,GRPO从当前策略中采样一组输出,并计算每个输出的奖励值。
•相对优势估计:通过将每个输出的奖励值与组内平均奖励值进行比较,计算出每个输出的相对优势。
•策略更新:根据相对优势,GRPO更新策略模型,优先选择相对优势更高的输出。同时,它通过KL散度约束来控制策略更新的幅度,确保策略分布的稳定性
# AI大模型趋势
小模型将成为主流(大模型蒸馏)
通过蒸馏技术将大型模型的推理能力成功迁移到小型模型中,显著提升了小型模型的性能。
DeepSeek-R1-Distill-Qwen-7B在AIME 2024竞赛中击败了32B模型使用合成数据进行训练成为主流
蒸馏数据是公开的秘密,但很多表现不是蒸馏能解释的。比如v3的中文能力,很多用词和表达方式非常接地气,可能是用了数据合成方法做的预训练。AI模型将自我迭代:强化学习新范式
让模型自己出题自己做,自己检查。
Step1,模型自己出题自己做,比如出了1亿道题目
Step2,模型自己检查对不对
Step3,筛选验证对的内容,将结果与思维链合成新的数据
比如1亿道题目中,自己检查后发现有100万道能验证是对的。那么解出这100万道题的思维链就成了新的训练数据。
不断迭代,探索出之前人类没有探索到的地方(类似AlphaGo-Zero)