
AI大赛-二手车价格预测
# 题目
- 数据集:
used_car_train_20200313.csv
used_car_testB_20200313.csv
数据来自某交易平台的二手车交易记录 https://tianchi.aliyun.com/competition/entrance/231784/introduction (opens new window)
ToDo:给你一辆车的各个属性(除了price字段),预测它的价格
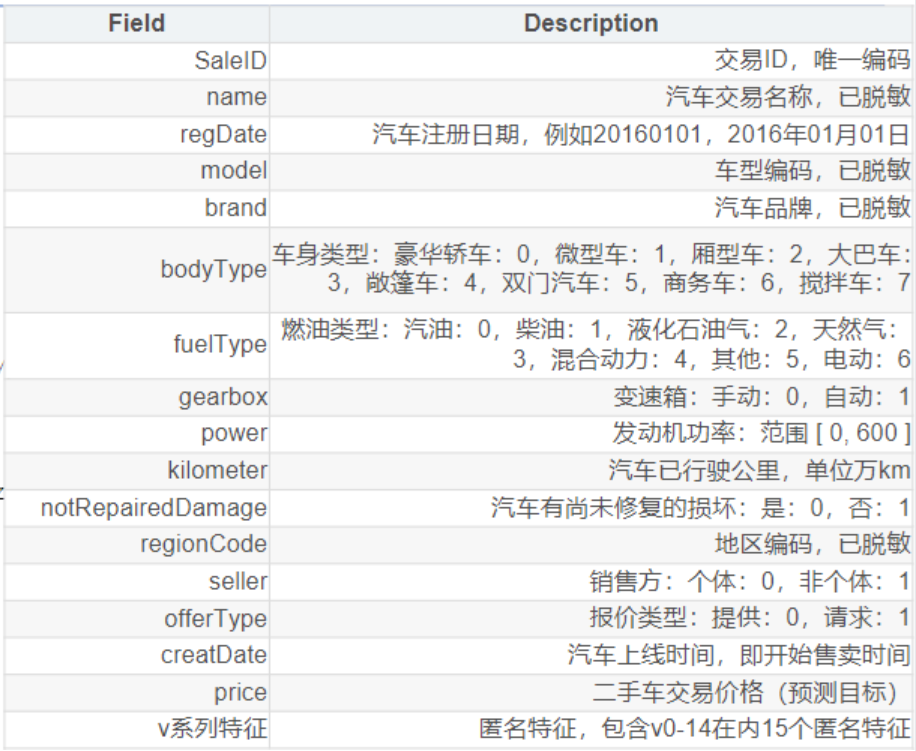

# 题目解释
# 这个题目要你干什么?
一句话:给你一堆二手车的信息,让你预测这辆车能卖多少钱。
这就是一个典型的回归问题——预测的是一个具体数字(价格),不是分类(像垃圾邮件那种0或1)。
# 拆开来看
你有什么:
- 每辆车的各种属性:品牌、车型、车身类型、燃油类型、变速箱、功率、行驶公里数、有没有没修的损坏、地区、注册日期、上线日期……
- 还有15个v系列匿名特征(不知道具体含义,但也是数据)
你要预测什么:
- price,二手车交易价格
你怎么算分:
- MAE(平均绝对误差)
- 你的预测价格跟真实价格差多少,差的绝对值加起来除以总数
- MAE越小越好
# MAE用大白话理解
你猜3辆车价格:
- 真实价格15万,你猜17万,差2万
- 真实价格20万,你猜24万,差4万
- 真实价格12万,你猜9万,差3万
MAE = (2+4+3) ÷ 3 = 3万
意思是:你平均每次猜偏3万。 偏得越少越厉害。
# 这个题目在考你什么?
这不是单纯考你跑个模型,它考的是完整的机器学习项目流程:
- 数据探索——先看看数据长什么样,有没有缺失值、异常值
- 特征工程——这是重点。比如:
- 注册日期和上线日期的差 = 车龄(这个原始字段里没有,你得自己造)
- 功率和车身类型组合起来可能有新含义
- v系列匿名特征怎么处理
- 模型选择——刚学了8个模型,这是回归问题(预测数字),你该选哪些?
- 线性回归:先跑个baseline
- 随机森林:稳
- XGBoost/LightGBM/CatBoost:冲高分用这些
- 模型调优——调参数,让MAE更低
- 提交结果——格式要对,SaleID + 预测价格
# 为什么选这个题目?
阿里天池的入门题,选它有几个原因:
- 数据是表格型的(Excel那种),最适合你刚学的这些模型
- 字段含义清晰,不需要领域专家知识也能理解
- 回归问题比分类问题更直觉——价格嘛,谁都能看懂对不对
# 分类与回归的区别
别急,我帮你翻译成人话。
# 分类 vs 回归:一句话区分
分类:猜"是什么" → 答案是几个选项里选一个
回归:猜"是多少" → 答案是一个具体数字
# 用例子感受
分类:
- 这封邮件是垃圾邮件还是正常邮件?(二选一)
- 这张图是猫还是狗还是鸟?(三选一)
- 这个客户会违约吗?(是/否)
答案都是固定的选项,就那么几个。
回归:
- 这套房子值多少钱?(可能100万,也可能103.5万,连续的)
- 明天气温多少度?(可能25度,也可能25.3度)
- 这辆二手车能卖多少?(可能8万,也可能8.7万)
答案是任意数字,不是选A还是B。
# 它们的内在联系
其实没那么泾渭分明,很多时候可以互相转换。
1. 回归可以变成分类
比如你要预测一个人年龄(回归),但你说我不要精确数字,我只要知道他属于哪个年龄段:
- 0-18岁 → 少年
- 18-35岁 → 青年
- 35-60岁 → 中年
- 60岁以上 → 老年
你看,回归问题(预测具体年龄)就变成了分类问题(猜年龄段)。
2. 分类背后其实也是算概率
逻辑回归名字里有"回归",但它是做分类的。为什么?
因为它先回归出一个概率值(0到1的连续数字),然后看这个概率:
- 概率>0.5 → 判断为正类
- 概率<0.5 → 判断为负类
先回归(算概率),再分类(画条线切开)。
3. 有些分类天然就像回归
比如评分1-5星。1星和2星是"相邻"的,4星和5星差距很小,但1星和5星差距很大。
这不只是"选哪个类别",类别之间是有顺序、有远近的。这种"有序分类"本质上就接近回归。
# 术语翻译
| 原文 | 大白话 |
|---|---|
| 离散类别标签 | 几个固定选项,比如A/B/C |
| 连续数值 | 任意数字,比如3.14、8.7万 |
| 交叉熵损失 | 分类时用的"扣分规则",猜错扣多少分 |
| 均方误差(MSE) | 回归时用的"扣分规则",猜偏多少扣多少 |
| Softmax | 把数字变成概率的函数,比如算出来2、5、3,变成10%、70%、20%的概率分布 |
| f(X)→Y | 输入X,输出Y,就是"给特征,出结果" |
| 阈值 | 分界线,比如0.5,超过就算正类 |
# 刚刚的二手车题目串起来
- 预测二手车卖多少钱 → 回归(价格是具体数字)
- 如果改成"这辆车是贵还是便宜" → 分类(贵/便宜,两个选项)
- 逻辑回归算出概率0.73 → 回归(0.73是个连续数字)
- 0.73>0.5所以判断为"贵" → 分类(做了选择)
分类和回归就像一把尺子的两端,不是两个世界,而是同一个事情的不同用法。
# 解题思路
好,把解题思路从头到尾捋一遍。
# 第一步:先看数据长什么样
拿到数据别急着跑模型,先摸清楚数据的情况。
要看的几件事:
- 有多少条数据? 几千条还是几十万条?数据量决定你用什么模型
- 有没有缺失值? 比如有的车没填变速箱类型,这就是空缺
- 有没有异常值? 比如功率写着600(上限就是600),或者价格为0的
- 各字段分布是什么样的? 大部分车跑了多少公里?什么品牌最多?
这一步就是"先侦察",不了解数据就上手等于蒙着眼打靶。
# 第二步:特征工程(最重要的一步)
这一步做得好不好,直接决定你最终分数。
什么叫特征工程? 就是把原始数据变成模型更好消化的形式,或者从现有数据里"造"出更有用的新特征。
# 2.1 清洗数据
- 缺失值填充:空的地方补上合理的值(比如用中位数、众数填)
- 异常值处理:功率600的那种,可能是数据错误,要么修正要么删掉
- notRepairedDamage字段可能是"-"字符串而不是数字,要转成0/1
# 2.2 构造新特征(这是拉开差距的关键)
原始字段里有宝藏,但得你自己挖:
- 车龄 = 上线时间 - 注册时间。这个字段原始数据里没有,但对价格影响巨大——越老越便宜
- 使用强度 = 行驶公里数 / 车龄。每年跑的公里数越多,车磨损越大
- 品牌热度 = 某品牌的交易量。热门品牌保值
- 地区价格水平 = 某地区的平均成交价
这些你自己"造"出来的特征,往往比原始字段更有用。
# 2.3 处理类别特征
- bodyType、fuelType、gearbox这种类别型的,有些模型(比如LightGBM)能直接吃,有些需要你转成数字
- v系列匿名特征也别忽略,虽然不知道具体含义,但15个特征里说不定有重要的
# 第三步:选模型
这是回归问题(预测价格),你今天学的模型里能用的是:
先跑baseline:
- 线性回归:最快最简单,先跑一版看看MAE多少,作为参照
再冲高分:
- 随机森林:稳定不容易翻车
- LightGBM:速度快,表格数据之王
- XGBoost:准确率高,但比LightGBM慢
- CatBoost:类别特征多的话开箱即用
实际策略: 先用LightGBM跑一版,调调参,再试试XGBoost,最后把两个模型的预测结果取平均(这叫模型融合),通常比单个模型更好。
# 第四步:训练和验证
不能把所有数据都用来训练,否则你不知道模型好不好。
常用方法:5折交叉验证
把数据切成5份,每次用4份训练、1份验证,轮5次,取平均MAE。这样评估更可靠。
# 第五步:调参
每个模型都有参数可以调,比如LightGBM的:
n_estimators:树的数量,越多越好但太慢max_depth:树的深度,太深容易过拟合learning_rate:学习步长,太大容易走过头,太小训练慢
调参就是不断尝试,找到MAE最低的那组参数。可以用网格搜索或者贝叶斯调参。
# 第六步:模型融合(冲分利器)
一个模型可能MAE是700,另一个是710,你把两个模型的预测结果按比例混合:
最终预测 = 0.6 × LightGBM预测 + 0.4 × XGBoost预测
往往比单个模型更好,因为两个模型犯的错不一样,混合之后互相抵消。
# 完整流程图
原始数据
↓
1. 数据探索(看看长什么样)
↓
2. 数据清洗(填缺失、去异常)
↓
3. 特征工程(造新特征、处理类别)
↓
4. 切分训练集/验证集
↓
5. 选模型训练(线性回归→LightGBM→XGBoost)
↓
6. 调参(找MAE最低的参数)
↓
7. 模型融合(多模型混合)
↓
8. 预测测试集,提交结果
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
最关键的两步:特征工程和模型融合。 这两步做好,排名能上去一大截。其他步骤大家都会做,这两步是拉差距的。
# 第一步:数据探索
import pandas as pd
import numpy as np
# 1. 读取数据
train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')
# 2. 看数据长什么样
print("=== 数据形状 ===")
print(train_data.shape)
print("\n=== 前5行数据 ===")
print(train_data.head())
print("\n=== 数据基本信息 ===")
print(train_data.info())
print("\n=== 数值型字段统计 ===")
print(train_data.describe())
print("\n=== 缺失值统计 ===")
print(train_data.isnull().sum())
print("\n=== 缺失值比例 ===")
print((train_data.isnull().sum() / len(train_data) * 100).round(2))
# 3. 看目标变量price的分布
print("\n=== price统计 ===")
print(train_data['price'].describe())
print("\n=== price为0的数量 ===")
print((train_data['price'] == 0).sum())
# 4. 看各字段的唯一值数量
print("\n=== 各字段唯一值数量 ===")
for col in train_data.columns:
print(f"{col}: {train_data[col].nunique()}个唯一值")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# import 部分
import pandas as pd
import= 导入,把别人写好的工具箱拿过来用pandas= Python里处理表格数据最常用的库,能读Excel、CSV,能筛选、统计、计算as pd= 给pandas起个短名,以后写pd就代表pandas,省事
import numpy as np
numpy= Python里做数学计算的库,尤其擅长处理数字数组as np= 同理,短名
类比:pandas就像一个超级Excel,numpy就像一个超级计算器。
# 读取数据
train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')
pd.read_csv()= pandas的读文件函数,把CSV文件读进来变成表格'used_car_train_20200313.csv'= 文件名,你要确保这个文件在代码同目录下sep=' '= 分隔符。正常CSV用逗号分隔,但这个数据集用空格分隔,所以要指定train_data= 变量名,读进来的数据存在这里
类比:就像你用Excel打开一个文件,表格内容就显示出来了。
# 看数据形状
print(train_data.shape)
train_data.shape= 返回(行数, 列数)- 比如输出(150000, 31)就是15万条数据、31个字段
print()= 把结果打印出来,不然你看不到
类比:先看看这个Excel有几行几列。
# 看前5行
print(train_data.head())
.head()= 看前5行数据- 不加参数默认5行,想看10行就写
.head(10) - 快速了解每列大概长什么样:数字还是文字?有没有明显的异常?
类比:扫一眼Excel的前几行,看看长什么样。
# 看基本信息
print(train_data.info())
.info()= 显示每列的名字、数据类型(整数/浮点数/字符串)、有多少非空值- 能发现哪些列有空缺,哪些列类型不对(比如应该是数字却是字符串)
类比:Excel里选中全部列,看看每列的数据类型和空单元格。
# 数值型统计
print(train_data.describe())
.describe()= 对所有数字类型的列做统计:数量、平均值、最小值、最大值、四分位数- 一眼能看出:
- power最小0最大600,有没有异常?
- price最小0?价格0合理吗?
- kilometer平均跑了多少?
类比:Excel里每列做一个"数据分析→描述统计"。
# 缺失值统计
print(train_data.isnull().sum())
.isnull()= 对每个格子检查是不是空值,返回True/False的表格.sum()= 把True当1加起来,就是每列有多少个空值
print((train_data.isnull().sum() / len(train_data) * 100).round(2))
len(train_data)= 总行数/ len(train_data) * 100= 空值数÷总行数×100 = 缺失比例.round(2)= 保留2位小数
拆开算一遍: 假设model列有500个空值,总数据15万条
- 500 / 150000 × 100 = 0.33%
- 意思是model列0.33%的数据缺失
类比:看每列有多少单元格是空的,算个百分比。
# 看price分布
print(train_data['price'].describe())
train_data['price']= 只取price这一列.describe()= 对这一列做统计- 重点关注:最小值、最大值、平均值、中位数
print((train_data['price'] == 0).sum())
train_data['price'] == 0= 逐行检查price是不是0,返回True/False.sum()= True的数量,就是price=0的有几条- 价格为0大概率是数据有问题,得处理
# 各字段唯一值数量
for col in train_data.columns:
print(f"{col}: {train_data[col].nunique()}个唯一值")
2
for col in train_data.columns= 遍历每一列,col是当前列名train_data.columns= 所有列名的列表.nunique()= 这一列有多少种不同的值(去重后的数量)f"{col}: ..."= 格式化字符串,把col变量的值嵌进文字里
为什么看这个? 能帮你判断哪些是类别特征、哪些是连续特征:
- brand有40个唯一值 → 类别特征,40个品牌
- power有几百个唯一值 → 连续特征,数字有很多种
- SaleID每条都不一样 → ID,没信息量,后面可以扔掉
# 第一步数据探索的思考
好,我带你一段一段看,重点教你怎么"思考"而不是死记结论。
# 一、数据形状:(150000, 31)
我的思考过程:
15万行31列。15万条不算少了,够模型吃的。31个字段,要搞清楚哪些有用哪些没用。
先看总量,心里有个数,数据量大模型选择余地就大,数据量少就得谨慎。
# 二、缺失值分析
这是最该先看的东西,因为缺数据=模型吃不饱=预测不准。
| 字段 | 缺失数 | 缺失比例 | 我的判断 |
|---|---|---|---|
| model | 1 | 0% | 只差1条,基本忽略,填个众数就行 |
| bodyType | 4506 | 3.00% | 不多,要填 |
| fuelType | 8680 | 5.79% | 最多,接近6%,要填 |
| gearbox | 5981 | 3.99% | 4%,要填 |
我的思考过程:
- 先看有没有缺特别多的——如果某列缺了50%以上,那这列基本废了,可以考虑扔掉
- 这里最多的也才5.79%,不算严重,可以补
- 怎么补?类别型的字段(bodyType、fuelType、gearbox)用众数(出现最多的那个值)来填,因为这些是分类选项,填最常见的最合理
另外注意: notRepairedDamage显示0个缺失,但它的类型是object(字符串),唯一值有3个。按照题目说的应该是0和1,多出来的那个很可能是"-"。这其实是隐藏的缺失值,后面要处理。
思考习惯: isnull()只能检测真正的空值,有些数据用"-"、"NA"、"未知"代替空值,这种要自己发现。类型是object的列要多留个心眼。
# 三、price分析
count 150000
mean 5923 平均价格5923
std 7502 标准差7502,波动很大
min 11 最低11块?
25% 1300 25%的车低于1300
50% 3250 中位数3250
75% 7700 75%的车低于7700
max 99999 最高接近10万
2
3
4
5
6
7
8
我的思考过程:
平均5923,中位数3250——平均数比中位数高很多,说明被少数高价车拉高了。大部分车其实比较便宜,少数车特别贵。
标准差7502 > 平均值5923——标准差比均值还大,说明价格分布非常散,贵的便宜的差距极大。
最低11块——这合理吗?一辆二手车卖11块?这很可能是异常值,后面要看看是几条,要不要处理。
最高99999——接近10万,倒也不是不可能,但看是不是99666这种整整齐齐的数,可能是封顶了。
price为0的数量=0——好消息,至少没有0价格的。
思考习惯: 看统计数字时,不是只看平均数,要同时看中位数、极值、标准差。平均数会被极端值拉偏,中位数更靠谱。极值往往藏异常。
# 四、各字段唯一值——判断特征类型
这步特别重要,帮你判断每个字段是什么类型,后面处理方式不一样。
| 字段 | 唯一值数 | 我的判断 | 理由 |
|---|---|---|---|
| SaleID | 150000 | 扔掉 | 每条都不一样,跟价格没关系 |
| name | 99662 | 可能扔掉 | 几乎每条都不一样,信息量低 |
| regDate | 3894 | 连续/日期 | 要转成车龄 |
| model | 248 | 类别 | 248种车型,类别特征 |
| brand | 40 | 类别 | 40个品牌 |
| bodyType | 8 | 类别 | 8种车身类型 |
| fuelType | 7 | 类别 | 7种燃油类型 |
| gearbox | 2 | 类别 | 手动/自动,二选一 |
| power | 566 | 连续 | 功率,数字范围大 |
| kilometer | 13 | 有序类别 | 只有13种值,比如0、1、2...15万公里 |
| notRepairedDamage | 3 | 类别 | 应该是0/1,多了个"-" |
| regionCode | 7905 | 类别 | 地区编码,种类很多 |
| seller | 2 | 类别 | 但只有2种,看看分布是否极端 |
| offerType | 1 | 扔掉 | 只有1个值,没有任何区分度 |
| creatDate | 96 | 日期 | 要跟regDate一起算车龄 |
| price | 3763 | 目标变量 | 这是要预测的,不是特征 |
| v_0~v_14 | 14万左右 | 连续 | 匿名特征,值很分散,是连续数字 |
我的思考过程:
- 唯一值=总行数 → 扔:SaleID每条不一样,对预测没帮助,就是编号
- 唯一值=1 → 扔:offerType只有一个值,所有人都一样,区分不了任何东西
- 唯一值很少(2~10) → 类别特征:bodyType、fuelType、gearbox这些
- 唯一值很多且是数字 → 连续特征:power、v系列
- 日期类型 → 要转换:regDate和creatDate本身没意义,但它们的差(车龄)很有意义
思考习惯: 看到nunique()的结果,先分三类:扔掉的、类别型的、连续型的。这决定你后面每列怎么处理。
# 五、特别要注意的问题
总结一下从数据里发现的坑:
- notRepairedDamage:类型是object,有3个唯一值(应该是0和1,多了个"-"),这是隐藏缺失值
- seller只有2个唯一值:很可能是99.9%都是同一类,另一个类几乎没数据,这种特征没意义
- price最低11:可能是异常值,后续要检查
- name有99662个唯一值:几乎每条都不同,信息量低,可能要扔或者只保留高频的
# 总结:下一步要做什么
根据分析,第二步数据清洗要处理这些:
- 扔掉无用列:SaleID、offerType
- 处理notRepairedDamage的"-",转成数字
- 填充缺失值:model、bodyType、fuelType、gearbox
- 检查seller的分布,可能也扔掉
- 构造车龄特征:creatDate - regDate
- 处理price异常值(11块的)
# 第二步:数据清洗
import pandas as pd
import numpy as np
# 1. 读取数据
train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')
# 2. 扔掉无用列
train_data = train_data.drop(['SaleID', 'offerType', 'name'], axis=1)
# 3. 处理notRepairedDamage的"-"问题
print("=== notRepairedDamage的值分布 ===")
print(train_data['notRepairedDamage'].value_counts())
train_data['notRepairedDamage'] = train_data['notRepairedDamage'].replace('-', np.nan)
train_data['notRepairedDamage'] = train_data['notRepairedDamage'].astype(float)
mode_value = train_data['notRepairedDamage'].mode()[0]
train_data['notRepairedDamage'] = train_data['notRepairedDamage'].fillna(mode_value)
# 4. 检查seller分布
print("\n=== seller的值分布 ===")
print(train_data['seller'].value_counts())
train_data = train_data.drop(['seller'], axis=1)
# 5. 填充缺失值
for col in ['model', 'bodyType', 'fuelType', 'gearbox']:
mode_val = train_data[col].mode()[0]
train_data[col] = train_data[col].fillna(mode_val)
print(f"{col}填充众数: {mode_val}")
# 6. 构造车龄特征
train_data['regDate_dt'] = pd.to_datetime(train_data['regDate'].astype(str), format='%Y%m%d', errors='coerce')
train_data['creatDate_dt'] = pd.to_datetime(train_data['creatDate'].astype(str), format='%Y%m%d', errors='coerce')
train_data['car_age_days'] = (train_data['creatDate_dt'] - train_data['regDate_dt']).dt.days
train_data['car_age'] = train_data['car_age_days'] // 365
train_data['car_age_month'] = train_data['car_age_days'] // 30
# 修正负数车龄
print(f"\n车龄为负的数量: {(train_data['car_age'] < 0).sum()}")
train_data.loc[train_data['car_age'] < 0, 'car_age'] = 0
train_data.loc[train_data['car_age_month'] < 0, 'car_age_month'] = 0
train_data.loc[train_data['car_age_days'] < 0, 'car_age_days'] = 0
# 填充车龄缺失值(日期格式不对导致的NaN)
age_median = train_data['car_age'].median()
print(f"车龄缺失数量: {train_data['car_age'].isnull().sum()}")
print(f"车龄中位数: {age_median}")
train_data['car_age'] = train_data['car_age'].fillna(age_median)
train_data['car_age_month'] = train_data['car_age_month'].fillna(age_median * 12)
train_data['car_age_days'] = train_data['car_age_days'].fillna(age_median * 365)
# 删掉临时列
train_data = train_data.drop(['regDate_dt', 'creatDate_dt', 'creatDate'], axis=1)
# 7. 构造使用强度
train_data['use_intensity'] = train_data['kilometer'] / (train_data['car_age'] + 1)
# 8. 处理power异常值(先填0,再封顶)
power_median = train_data.loc[train_data['power'] > 0, 'power'].median()
print(f"\npower中位数: {power_median}")
print(f"power=0的数量: {(train_data['power'] == 0).sum()}")
print(f"power>600的数量: {(train_data['power'] > 600).sum()}")
train_data.loc[train_data['power'] == 0, 'power'] = power_median
train_data.loc[train_data['power'] > 600, 'power'] = 600
# 9. 处理price异常值
print(f"\nprice<50的数量: {(train_data['price'] < 50).sum()}")
train_data = train_data[train_data['price'] >= 50]
# 10. 检查清洗结果
print("\n=== 清洗后缺失值 ===")
print(train_data.isnull().sum())
print("\n=== 清洗后数据形状 ===")
print(train_data.shape)
print("\n=== car_age统计 ===")
print(train_data['car_age'].describe())
# 11. 保存
train_data.to_csv('used_car_train_cleaned.csv', index=False)
print("\n清洗后的数据已保存")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# 第1步:读取数据
import pandas as pd
import numpy as np
2
- 上一步讲过了,导入pandas和numpy两个工具库
train_data = pd.read_csv('used_car_train_20200313.csv', sep=' ')
- 也讲过了,读CSV文件,
sep=' '指定空格分隔
# 第2步:扔掉无用列
train_data = train_data.drop(['SaleID', 'offerType', 'name'], axis=1)
.drop()= 删除指定的列- 一次删3列,用列表包起来
- SaleID:每条都不一样的编号,对预测没帮助
- offerType:只有1个唯一值,区分不了任何东西
- name:99662个唯一值,15万条数据几乎每条都不一样,噪音太大
为什么不是所有唯一值多的都删? regionCode也有7905个唯一值,但地区对价格有影响(北京和三线城市价格差很多),所以留着。name是交易编号,没有实际意义。
思考习惯:删列之前想两件事——①这列跟预测目标有没有逻辑关系?②这列有没有区分度?两个都没有就删。
# 第3步:处理notRepairedDamage
print(train_data['notRepairedDamage'].value_counts())
.value_counts()= 统计每个值出现了多少次- 你会看到类似:0: 100000, 1: 30000, -: 20000
- "-"就是隐藏的缺失值,需要处理
train_data['notRepairedDamage'] = train_data['notRepairedDamage'].replace('-', np.nan)
.replace('-', np.nan)= 把字符串"-"替换成NaN(真正的空值)- 为什么不直接替换成0或1?因为我们不知道应该填哪个,先变成空值,再统一用众数填充
train_data['notRepairedDamage'] = train_data['notRepairedDamage'].astype(float)
.astype(float)= 把数据类型从字符串转成浮点数- 原来是object类型,"0"和"1"是文字,不是数字
- 转成float后变成0.0和1.0,模型才能计算
类比:Excel里有一列写着"0"、"1"、"-"的文字,你先把"-"清空,然后把整列格式从文本改成数字。
mode_value = train_data['notRepairedDamage'].mode()[0]
.mode()= 求众数(出现最多的值)- 返回的是一个Series(可能不止一个众数),
[0]取第一个 - 比如0出现了10万次,1出现了3万次,众数就是0.0
train_data['notRepairedDamage'] = train_data['notRepairedDamage'].fillna(mode_value)
.fillna()= 填充空值- 把所有NaN都填成众数0.0
- 逻辑:不知道有没有损坏,就假设跟大多数人一样——没损坏
# 第4步:检查seller并删除
print(train_data['seller'].value_counts())
- 先看看分布,你会看到0有149999条,1只有1条
- 这种极端分布叫"低方差",模型从中学不到任何东西
train_data = train_data.drop(['seller'], axis=1)
- 直接删掉
思考习惯:一个特征如果99.9%都是同一个值,它就没有区分能力。想象考试全班只有1个人不及格,"是否及格"这个指标就没法帮你判断谁学得好谁学得差。
# 第5步:填充类别型缺失值
for col in ['model', 'bodyType', 'fuelType', 'gearbox']:
for ... in ...= 循环,依次遍历列表里的4个列名- 每次循环
col就是当前列名
mode_val = train_data[col].mode()[0]
train_data[col]= 取当前列,方括号里是列名变量.mode()[0]= 这列的众数
train_data[col] = train_data[col].fillna(mode_val)
- 用众数填充这一列的空值
print(f"{col}填充众数: {mode_val}")
f"..."= 格式化字符串,花括号里的变量会被替换成实际值- 比如
col='model',mode_val=228.0,输出就是"model填充众数: 228.0" - 打印出来是为了让你知道每列填了什么,方便检查
为什么用众数不用别的? 这4列都是类别特征。类别特征填平均数没意义——"第3.5种车身类型"不存在。填最常见的类别最合理。
# 第6步:构造车龄特征
train_data['regDate_dt'] = pd.to_datetime(train_data['regDate'].astype(str), format='%Y%m%d', errors='coerce')
这行比较长,拆开看:
train_data['regDate']= 原始注册日期列,是整数,比如20040402.astype(str)= 转成字符串"20040402",因为to_datetime需要字符串pd.to_datetime()= 把字符串解析成真正的日期类型format='%Y%m%d'= 告诉pandas格式:4位年+2位月+2位日%Y= 4位年份(2004)%m= 2位月份(04)%d= 2位日期(02)
errors='coerce'= 如果有格式不对的日期(比如20161332这种不存在的日期),不要报错,变成NaT(日期版的NaN)
train_data['creatDate_dt'] = pd.to_datetime(train_data['creatDate'].astype(str), format='%Y%m%d', errors='coerce')
- 同上,处理上线日期
train_data['car_age_days'] = (train_data['creatDate_dt'] - train_data['regDate_dt']).dt.days
creatDate_dt - regDate_dt= 两个日期相减,结果是"时间差"类型(比如"4395天").dt.days= 从时间差中提取天数部分,变成普通整数
train_data['car_age'] = train_data['car_age_days'] // 365
- 天数整除365 = 年数
//= 整除,只留整数部分(4395//365=12,不是12.04)
train_data['car_age_month'] = train_data['car_age_days'] // 30
- 天数整除30 = 大约的月数(4395//30=146个月)
- 不精确但够用,比按年粗多了
print(f"\n车龄为负的数量: {(train_data['car_age'] < 0).sum()}")
- 检查有没有负数车龄
- 可能是数据录入错误,注册日期比上线日期还晚
train_data.loc[train_data['car_age'] < 0, 'car_age'] = 0
train_data.loc[train_data['car_age_month'] < 0, 'car_age_month'] = 0
train_data.loc[train_data['car_age_days'] < 0, 'car_age_days'] = 0
2
3
.loc[条件, 列名] = 值= 选中满足条件的行的某列,设成指定值- 把负数车龄全部设成0(不能是负的,最低就是0)
train_data = train_data.drop(['regDate_dt', 'creatDate_dt', 'creatDate'], axis=1)
- 删掉3列:
regDate_dt、creatDate_dt:临时列,算完就没用了creatDate:原始日期列,信息已经提取到car_age里了,留着是噪音
思考习惯:临时列用完就删,保持数据干净。原始列如果信息已经提取到新特征里,也可以删。
# 第7步:构造使用强度
train_data['use_intensity'] = train_data['kilometer'] / (train_data['car_age'] + 1)
kilometer= 已行驶公里数(万公里)car_age + 1= 车龄+1,加1防止除以0- 结果 = 每年跑了多少万公里
为什么这个特征有用? 同样5年的车,一个跑了2万公里,一个跑了15万公里,价格肯定差很多。单独看公里数或单独看车龄都区分不了,但组合起来就能。
思考习惯:把两个有关系的特征组合起来,往往比单独用效果更好。
# 第8步:处理power异常值
power_median = train_data.loc[train_data['power'] > 0, 'power'].median()
train_data['power'] > 0= 找出power大于0的行(排除异常的0值).median()= 求中位数- 为什么不直接用所有行的中位数?因为power=0是异常值,会拉低中位数
train_data.loc[train_data['power'] == 0, 'power'] = power_median
- 把power=0的行用中位数填充
- 为什么不用众数?power是连续数字,566个唯一值,众数可能就多出现几次,不够代表性。中位数更稳
train_data.loc[train_data['power'] > 600, 'power'] = 600
- 把power>600的封顶到600
- 题目说范围是[0,600],超过的就是异常
先填0再封顶,顺序不能反。 如果先封顶,600那个值会影响中位数的计算。
# 第9步:处理price异常值
train_data = train_data[train_data['price'] >= 50]
train_data['price'] >= 50= 保留价格>=50的行,删掉低于50的train_data[条件]= 用条件筛选行,只保留满足条件的
类比:Excel里筛选price列,大于等于50的保留,其余删掉。
为什么删行而不是填值? price是目标变量,填错了会直接教坏模型。而且异常价格只有几条,删了也不心疼。特征列的异常可以填,目标变量的异常建议删。
# 第10步:检查清洗结果
print(train_data.isnull().sum())
- 确认所有列的缺失值都是0
print(train_data.shape)
- 看清洗后还有多少行多少列(应该比15万少一点,因为删了异常行)
print(train_data['car_age'].describe())
- 检查车龄分布是否合理(min应该>=0,max应该不会太离谱)
# 第11步:保存
train_data.to_csv('used_car_train_cleaned.csv', index=False)
- 保存成新文件,下一步直接读这个文件就行,不用重复清洗
index=False= 不保存行号
# 第三步特征工程思考
# 先说"特征"是啥
特征就是影响价格的线索。
你去买二手车,你会看什么?看品牌、看车龄、看跑了多少公里、看有没有修过。这些你"看的东西",就是特征。
现在数据里已经有一些特征了,比如品牌、车龄、功率。特征工程就是自己再"造"一些线索出来,让模型更容易猜对价格。
# 造特征——就像你买房时的直觉
例子1:车龄分组
数据里车龄是0、1、2、3……一直到25,一串数字。
但现实中你不会这么想,你想的是:
- 3年以内的——新车,还值钱
- 3到7年的——中年车,开始掉价
- 7年以上的——老车,掉价厉害
你给模型一个数字"12",它不知道12年是新车还是老车。但你直接告诉它"这是老车",它就秒懂了。
这就是造特征——把你脑子里的常识,变成数据告诉模型。
例子2:品牌均价
你说你买了一辆奥迪,我啥都不知道,但我一听奥迪就知道大概不便宜。为啥?因为我知道奥迪这个牌子均价就高。
模型不知道奥迪贵不贵,但你可以算一下:数据里所有奥迪的均价是多少,然后把这个数字当成一条新特征加上去。
这样模型一看,哦,这个品牌均价5万,那这辆车大概也不便宜。
例子3:交叉特征
单独看"奥迪"你知道贵,单独看"手动挡"你知道便宜。那"奥迪+手动挡"呢?这种组合很少见,可能贬值更狠。
这种两个特征拼在一起的,模型自己很难学到,你得手动拼给它。
# 编特征——把文字变成数字
模型只认数字,不认文字。你的数据里有些是类别,比如:
- fuelType:汽油、柴油、电动
- gearbox:自动、手动
少量选项的(比如燃料类型就3种),你搞3列:是汽油写1不是写0,是柴油写1不是写0,是电动写1不是写0。这叫one-hot,就像考试做选择题,A/B/C/D各涂一个圈。
选项太多的(比如品牌40个),你就别搞40列了,太浪费。直接给每个品牌编个号0-39就行,这叫label encoding。
# 选特征——别给太多干扰信息
你想,如果有人给你加一条"车主身份证号",这玩意跟车价有关系吗?没有。但模型不知道,它可能会瞎学。
所以造完特征之后要筛选:
- 跟价格没啥关系的,删
- 两个特征说的差不多是一回事的,留一个就行
总结一句话:特征工程就是把你买二手车时的经验和常识,翻译成模型能看懂的数字。
# 第三步:特征工程
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
import warnings
warnings.filterwarnings('ignore')
print("=" * 60)
print("Step3: 特征工程")
print("=" * 60)
# ======= 读取数据 =======
data_path = "used_car_train_cleaned.csv"
output_path = "used_car_train_featured.csv"
df = pd.read_csv(data_path, sep=',')
print(f"数据量:{df.shape[0]}行,{df.shape[1]}列")
# 记住原来的列名,后面对比用
original_columns = df.columns.tolist()
# =====================================
# 一,造特征
# =====================================
# 1. 车龄分组:0-3年新车,3-7年中年车,7年以上老车
def categorize_car_age(car_age):
if pd.isna(car_age):
return '未知'
elif car_age <= 3:
return '新车'
elif car_age <= 7:
return '中年车'
else:
return '老车'
df['car_age_group'] = df['car_age'].apply(categorize_car_age)
print("车龄分组完成:", df['car_age_group'].value_counts().to_dict())
# 删冗余车龄
df = df.drop(['car_age_days', 'car_age_month'], axis=1)
# 2. 品牌统计特征:每个品牌的均价,中位价,数量
brand_stats = df.groupby('brand')['price'].agg([
('brand_mean_price', 'mean'),
('brand_median_price', 'median'),
('brand_count', 'count')
]).reset_index()
df = df.merge(brand_stats, how='left', on='brand')
print("品牌统计特征完成")
# 3. 车型统计特征:每个车型的均价,中位价,数量
model_stats = df.groupby('model')['price'].agg([
('model_mean_price', 'mean'),
('model_median_price', 'median'),
('model_count', 'count')
]).reset_index()
df = df.merge(model_stats, how='left', on='model')
print("车型统计特征完成")
# 4. 交叉特征:品牌*车身类型 的均价, 品牌*变速箱 的均价
brand_body_stats = df.groupby(['brand','bodyType'])['price'].mean().reset_index()
brand_body_stats.columns = ['brand', 'bodyType', 'brand_body_price']
df = df.merge(brand_body_stats, how='left', on=['brand','bodyType'])
brand_gearbox_stats = df.groupby(['brand','gearbox'])['price'].mean().reset_index()
brand_gearbox_stats.columns = ['brand', 'gearbox', 'brand_gearbox_price']
df = df.merge(brand_gearbox_stats, how='left', on=['brand','gearbox'])
print("交叉特征完成")
# 5. 注册月份
df['reg_month'] = (df['regDate'] % 100) % 12 + 1
df = df.drop(['regDate'], axis=1)
print("注册月份特征完成")
# 6. 城市统计特征
city_stats = df.groupby('regionCode')['price'].agg([
('regionCode_mean_price', 'mean'),
('regionCode_count', 'count')
]).reset_index()
df = df.merge(city_stats, how='left', on='regionCode')
print("城市统计特征完成")
# ===============================
# 二,编特征(文字转数字)
# ===============================
# one-Hot编码:选项少的
one_hot_cols = ['fuelType', 'gearbox', 'notRepairedDamage']
for col in one_hot_cols:
if col in df.columns:
dummies = pd.get_dummies(df[col], prefix=col, drop_first=False)
df = pd.concat([df, dummies], axis=1)
# Label编码:选项多的
label_cols = ['brand', 'model', 'bodyType', 'city', 'car_age_group']
for col in label_cols:
if col in df.columns:
le = LabelEncoder()
df[col + '_code'] = le.fit_transform(df[col]).astype(int)
# 布尔转0/1
bool_cols = df.select_dtypes(include=['bool']).columns
for col in bool_cols:
df[col] = df[col].astype(int)
print("编码完成")
# =================================
# 三,选特征
# =================================
# 1.删除跟price相关性极低的特征
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
numeric_cols = [col for col in numeric_cols if col != 'price']
correlations = df[numeric_cols].corrwith(df['price']).abs().sort_values(ascending=False)
print("\n与price相关性Top10:")
for i,(col, corr) in enumerate(correlations.head(49).items(), 1):
print(f"{i}. {col}: {corr:.4f}")
# 删除相关性 < 0.01的
low_corr = correlations[correlations < 0.01].index.tolist()
if low_corr:
df = df.drop(columns=low_corr)
print(f"删除了{len(low_corr)}个低相关特征")
# 2. 处理共线性(两个特征高度相关的留一个)
stat_cols = ['brand_mean_price', 'brand_median_price', 'model_mean_price', 'model_median_price', 'city_mean_price']
existing = [c for c in stat_cols if c in df.columns]
if len(existing) > 1:
corr_matirx = df[existing].corr()
to_remove = []
for i in range(len(existing)):
for j in range(i+1, len(existing)):
if abs(corr_matirx.iloc[i, j]) > 0.95:
col1, col2 = existing[i], existing[j]
# 留跟price相关性更高的那个
if abs(df[col1].corr(df['price'])) < abs(df[col2].corr(df['price'])):
to_remove.append(col1)
else:
to_remove.append(col2)
to_remove = list(set(to_remove))
if to_remove:
df = df.drop(columns=to_remove)
print(f"删除了共线性特征:{to_remove}")
# ======= 保存 =======
df.to_csv(output_path, index=False, sep=' ')
print(f"\n保存完成!最终{df.shape[0]}行*{df.shape[1]}列")
# 新增特征列表
new_cols = [c for c in df.columns if c not in original_columns]
print(f"新增了{len(new_cols)}个特征:{new_cols}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
# 导入库
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
import warnings
warnings.filterwarnings('ignore')
2
3
4
5
一共4行,逐个讲:
1. import pandas as pd
pandas是处理表格数据的神器,你可以理解为超级Excel。
你平时用Excel能做的事——筛选、排序、求平均、合并表格——pandas全能做,而且快得多,还能处理几百万行数据(Excel几十万行就卡死了)。
as pd 就是给它起个短名字,后面写代码少打字。就像你叫"张三丰"太长,大家都喊"老张"。
后面代码里所有的 pd.xxx 都是在用pandas。
2. import numpy as np
numpy是专门做数学计算的,你可以理解为超级计算器。
pandas处理表格,numpy处理数字。比如你要算一堆数的平均值、找最大值、做加减乘除,numpy又快又方便。
你可能会问:pandas不是也能算平均数吗?对,pandas底层就是调的numpy。有些复杂计算pandas不方便,就得直接用numpy。
as np 同理,短名字。
3. from sklearn.preprocessing import LabelEncoder
sklearn全称scikit-learn,是机器学习最常用的工具包,里面有各种模型和预处理工具。
sklearn.preprocessing 是它里面的"预处理"模块,就是给数据做处理、让模型能读懂的工具。
LabelEncoder 是其中一个工具,作用就一句话:把文字变成数字编号。
比如品牌列有"奥迪、宝马、奔驰",模型不认识文字,LabelEncoder就给它编成0、1、2。后面代码会具体用到,到时候再细讲。
4. import warnings 和 warnings.filterwarnings('ignore')
这两行是一套的。
warnings是Python自带的警告系统。有时候代码能跑,但Python会弹出一些黄色警告,比如"这个功能以后会改"、"你数据里有空值"之类的。
这些警告不影响运行,但打印出来一大堆,看着烦,也容易让你以为出错了。
filterwarnings('ignore') 就是告诉Python:别废话,能跑就行,警告我不看。
总结一下这4行在干嘛:
| 代码 | 一句话解释 |
|---|---|
import pandas as pd | 叫来一个超级Excel帮我处理表格 |
import numpy as np | 叫来一个超级计算器帮我算数 |
from sklearn.preprocessing import LabelEncoder | 叫来一个翻译官,把文字翻成数字 |
warnings.filterwarnings('ignore') | 把告警关了,别烦我 |
# 读取数据
# ===== 读取数据 =====
data_path = "E:/zz/twoHandCar/used_car_train_20200313_cleaned.csv"
output_path = "E:/zz/twoHandCar/used_car_train_20200313_featured.csv"
df = pd.read_csv(data_path, sep=' ')
print(f"数据量:{df.shape[0]} 行,{df.shape[1]} 列")
original_columns = df.columns.tolist()
2
3
4
5
6
7
8
这段3件事:
1. 定义路径
data_path是Step2清洗完的数据,output_path是Step3处理完要保存的位置。你根据自己实际文件位置改就行。
2. 读取数据
pd.read_csv(data_path, sep=' ') 读取CSV文件。sep=' '是因为这个数据集是用空格分隔的,不是逗号,所以得告诉pandas用空格来切分。
如果你数据是普通逗号分隔的CSV,直接pd.read_csv(data_path)就行,默认就是逗号。
3. 记住原来的列名
df.columns.tolist() 把当前所有列名存成列表。为啥要存?因为后面你会造很多新特征,最后想看看自己到底新增了哪些,拿现在存的去对比就知道了。
就像你出门前拍张照,回来对比一下东西有没有少。
# 造特征第一招:车龄分组
def categorize_car_age(car_age):
if pd.isna(car_age):
return '未知'
elif car_age <= 3:
return '新车'
elif car_age <= 7:
return '中年车'
else:
return '老车'
df['car_age_group'] = df['car_age'].apply(categorize_car_age)
2
3
4
5
6
7
8
9
10
11
这段在干嘛: 把车龄数字变成3个档——新车、中年车、老车。
逐行拆:
def categorize_car_age(car_age):定义一个函数,接收一个车龄数字pd.isna(car_age)判断是不是空值。isna= is not available,有没有数据的意思。万一有车龄是空的,别报错,归到"未知"car_age <= 3就是3年以内算新车car_age <= 7就是3到7年算中年车else剩下的都是老车
df['car_age'].apply(categorize_car_age) 这行是关键。
apply的意思是"对这一列的每个值,都执行一遍括号里的函数"。
打个比方:你有一排人,你想知道每个人算青年、中年还是老年。apply就是让每个人走过一个检查站,检查站根据年龄给他贴个标签,最后所有人都有标签了。
结果就是数据多了一列car_age_group,每行写着"新车""中年车"或"老车"。
为什么要分组? 之前讲过了——模型看到车龄12,它不知道12算新还是老。你直接告诉它"老车",它秒懂价格大概率低。
# 品牌统计特征:
brand_stats = df.groupby('brand')['price'].agg([
('brand_mean_price', 'mean'),
('brand_median_price', 'median'),
('brand_count', 'count')
]).reset_index()
df = df.merge(brand_stats, on='brand', how='left')
2
3
4
5
6
我用具体数据带你走一遍每一步的变化。
假设原始数据长这样(简化版,只看3列):
brand price kilometer
0 0 8500 12
1 0 7200 10
2 1 3200 8
3 1 2800 5
4 0 9500 15
5 2 15000 3
6 1 3600 6
7 2 13000 4
2
3
4
5
6
7
8
9
8条数据,3个品牌,品牌0有3条,品牌1有3条,品牌2有2条。
# 第一步:groupby('brand')
df.groupby('brand')
这一步还没算任何东西,只是把数据分了堆:
- 品牌0的堆:第0、1、4行
- 品牌1的堆:第2、3、6行
- 品牌2的堆:第5、7行
就像你把扑克牌按花色分好了,但还没数每堆有几张。
# 第二步:['price']
df.groupby('brand')['price']
分好堆了,但每堆里有很多列。我只想看price,所以从每堆里只拿price出来。
- 品牌0的price:8500、7200、9500
- 品牌1的price:3200、2800、3600
- 品牌2的price:15000、13000
# 第三步:.agg([...])
.agg([
('brand_mean_price', 'mean'),
('brand_median_price', 'median'),
('brand_count', 'count')
])
2
3
4
5
对每堆的price算三个东西:
mean(平均数):所有数加起来除以个数
- 品牌0:(8500+7200+9500) ÷ 3 = 8400
- 品牌1:(3200+2800+3600) ÷ 3 = 3200
- 品牌2:(15000+13000) ÷ 2 = 14000
median(中位数):从小到大排,取中间那个
- 品牌0:7200、8500、9500 → 中间是 8500
- 品牌1:2800、3200、3600 → 中间是 3200
- 品牌2:13000、15000 → 中间是 14000
count(数量):数有几个
- 品牌0:3条
- 品牌1:3条
- 品牌2:2条
结果变成这样:
brand_mean_price brand_median_price brand_count
brand
0 8400 8500 3
1 3200 3200 3
2 14000 14000 2
2
3
4
5
注意看,brand变成了最左边的索引(行号),不是普通列了。
# 第四步:reset_index()
.reset_index()
把brand从索引变回普通列:
brand brand_mean_price brand_median_price brand_count
0 0 8400 8500 3
1 1 3200 3200 3
2 2 14000 14000 2
2
3
4
为什么要变?因为下一步merge需要brand是普通列才能匹配。就像VLOOKUP需要有一个普通的列去查找,不能拿行号去查。
# 第五步:merge
df.merge(brand_stats, on='brand', how='left')
现在你有两张表:
左边——原始数据:
brand price kilometer
0 0 8500 12
1 0 7200 10
2 1 3200 8
3 1 2800 5
4 0 9500 15
5 2 15000 3
6 1 3600 6
7 2 13000 4
2
3
4
5
6
7
8
9
右边——品牌统计:
brand brand_mean_price brand_median_price brand_count
0 0 8400 8500 3
1 1 3200 3200 3
2 2 14000 14000 2
2
3
4
merge做的事情:看左边每行的brand是几,去右边找到对应的那一行,把信息贴过来。
- 第0行,brand=0 → 去右边找brand=0 → 贴上8400、8500、3
- 第1行,brand=0 → 去右边找brand=0 → 贴上8400、8500、3
- 第2行,brand=1 → 去右边找brand=1 → 贴上3200、3200、3
- ……以此类推
最终结果:
brand price kilometer brand_mean_price brand_median_price brand_count
0 0 8500 12 8400 8500 3
1 0 7200 10 8400 8500 3
2 1 3200 8 3200 3200 3
3 1 2800 5 3200 3200 3
4 0 9500 15 8400 8500 3
5 2 15000 3 14000 14000 2
6 1 3600 6 3200 3200 3
7 2 13000 4 14000 14000 2
2
3
4
5
6
7
8
9
你看,每个品牌0的车都多了3个信息:品牌均价8400、品牌中位价8500、品牌数量3。品牌1的车也都贴上了自己的信息。
模型看到第2行就知道:这车品牌均价3200,便宜牌子。看到第5行就知道:这车品牌均价14000,贵牌子。
how='left'是啥意思?
merge有几种拼法:
left:保留左边所有行,右边没匹配到的填空值right:保留右边所有行inner:两边都有的才保留outer:两边都保留
我们用left,因为左边是原始数据,一条都不能丢。万一某个品牌在统计表里没有(虽然不太可能),那行也保留,只是统计值是空的。
# 车型统计,品牌统计
车型统计特征跟品牌统计一模一样的逻辑,只是换了个字段,我快速过一下:
model_stats = df.groupby('model')['price'].agg([
('model_mean_price', 'mean'),
('model_median_price', 'median'),
('model_count', 'count')
]).reset_index()
df = df.merge(model_stats, on='model', how='left')
2
3
4
5
6
把上面brand换成model,就是这一段。brand是品牌(奥迪、宝马),model是车型(同一品牌下的不同款)。算的也是均价、中位价、数量,逻辑完全一样,不重复讲了。
# 交叉特征
这是个新概念:
brand_body_stats = df.groupby(['brand', 'bodyType'])['price'].mean().reset_index()
brand_body_stats.columns = ['brand', 'bodyType', 'brand_body_price']
df = df.merge(brand_body_stats, on=['brand', 'bodyType'], how='left')
2
3
之前你是按一个字段分组(brand),这次是按两个字段分组(brand + bodyType)。
为什么要两个一起分组?
因为单独看品牌,你知道奥迪贵。单独看车身类型,你知道SUV贵。但"奥迪的SUV"和"奥迪的轿车",价格可能差很多,这个信息单独看品牌看不出来,单独看车身类型也看不出来,必须两个拼在一起看。
就像你去饭店点菜,红烧肉38,酸菜鱼48。但你问"红烧肉配酸菜鱼的套餐多少钱",这个价格单独看哪个菜都推不出来,得看菜单上的组合定价。
数据变化过程:
假设原始数据:
brand bodyType price
0 0 0 8500
1 0 1 5200
2 0 0 9000
3 1 0 3200
4 1 1 2800
5 0 1 5600
2
3
4
5
6
7
groupby(['brand', 'bodyType']) 按两个列一起分组:
- 品牌0+车身0:8500、9000 → 均价8750
- 品牌0+车身1:5200、5600 → 均价5400
- 品牌1+车身0:3200 → 均价3200
- 品牌1+车身1:2800 → 均价2800
brand_body_stats.columns = ['brand', 'bodyType', 'brand_body_price']
这行是给结果改列名。因为groupby算完mean之后,列名默认就叫'price',不够明确,改成'brand_body_price'一看就知道是什么。
然后merge回去,每条车就多了"我这个品牌+我这个车身类型的均价"这个信息。
后面品牌×变速箱也是一样的逻辑,就不重复了。
# 注册月份:
df['reg_month'] = (df['regDate'] % 100) % 12 + 1
regDate是注册日期,格式是201603这样的数字,表示2016年3月。
% 是取余数的意思。
201603 % 100→ 201603除以100,余数是 03,把月份提出来了03 % 12→ 3除以12余3,还是3(这步是处理月份为00的情况,00%12=0,再加1变1月)+ 1→ 如果余数是0,加1变成1月
所以整行的意思就是:从日期数字里把月份扣出来,变成1-12的数字。
为什么要提月份?因为有些月份注册的车可能更便宜。比如年底注册的可能是库存车,打折卖的,价格可能低一些。这种季节性规律,模型单独看年份看不出来,得看月份。
接下来城市统计特征,又跟品牌统计一样了:
city_stats = df.groupby('city')['price'].agg([
('city_mean_price', 'mean'),
('city_count', 'count')
]).reset_index()
df = df.merge(city_stats, on='city', how='left')
2
3
4
5
按城市分组算均价和数量。一线城市和三线城市的车价肯定不一样,这个信息对模型有用。
# One-Hot编码
# One-Hot编码:选项少的
one_hot_cols = ['fuelType', 'gearbox', 'notRepairedDamage']
for col in one_hot_cols:
if col in df.columns:
dummies = pd.get_dummies(df[col], prefix=col, drop_first=False)
df = pd.concat([df, dummies], axis=1)
2
3
4
5
6
之前讲过思路:选项少的,每个选项搞一列,是就写1不是就写0。
现在讲代码怎么实现的。
假设你的fuelType列长这样:
0 汽油
1 柴油
2 汽油
3 电动
4 汽油
2
3
4
5
第一步:pd.get_dummies(df[col], prefix=col, drop_first=False)
get_dummies就是"搞虚拟变量",也就是One-Hot编码。
它会自动看这一列有几种值,然后每种值搞一列。
prefix=col的意思是列名前面加个前缀,比如fuelType下面有汽油、柴油、电动三列,加前缀就变成:
fuelType_汽油 fuelType_柴油 fuelType_电动
0 1 0 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
2
3
4
5
6
第0行是汽油,所以fuelType_汽油=1,其他两列=0。就像考试做选择题,你选了A,A涂1,B和C涂0。
drop_first=False是啥?
意思是所有选项都搞一列,不删。有些人会设True删掉第一列(因为3列其实2列就够表达了——两列都是0就说明是第三种),但留着更直观,初学者不用纠结这个。
第二步:pd.concat([df, dummies], axis=1)
concat是"拼接",把新搞出来的几列贴到原始数据右边。
axis=1表示横向拼接(加列),axis=0是纵向拼接(加行)。你要加列,所以用1。
贴完之后原始数据就多了几列one-hot列。
第三步:外面套了个for循环
因为有3列要做One-Hot,所以用循环一个个来。fuelType搞完搞gearbox,gearbox搞完搞notRepairedDamage。
# Label编码
label_cols = ['brand', 'model', 'bodyType', 'city', 'car_age_group']
for col in label_cols:
if col in df.columns:
le = LabelEncoder()
df[col + '_code'] = le.fit_transform(df[col].astype(str))
2
3
4
5
为什么这些用Label编码不用One-Hot?
因为选项太多了。brand有40个品牌,model有几百个车型,你搞One-Hot就多出几百列,又占内存又没啥用。Label编码就给每个选项编个号,0、1、2、3……只多一列,干净利落。
逐行拆:
le = LabelEncoder() ——造一个编码器,你可以理解为拿了一个贴标签的机器。
df[col].astype(str) ——先把这一列转成字符串。为啥?因为有些列可能有空值或者混合类型,LabelEncoder只认字符串,转一下保险。
le.fit_transform(...) ——这行是核心,干了两件事:
- fit:看一遍数据,记住有哪些类别,给每个类别编个号
- transform:按编号把原始数据替换成数字
假设brand列长这样:
0 奥迪
1 宝马
2 奔驰
3 奥迪
4 宝马
2
3
4
5
fit_transform之后变成:
0 0 (奥迪第一次出现,编0)
1 1 (宝马第一次出现,编1)
2 2 (奔驰第一次出现,编2)
3 0 (奥迪见过,还是0)
4 1 (宝马见过,还是1)
2
3
4
5
df[col + '_code'] ——新列名在原列名后面加个"_code",比如brand变成brand_code。原来的brand列还留着,没删。
# 布尔转0/1
bool_cols = df.select_dtypes(include=['bool']).columns
for col in bool_cols:
df[col] = df[col].astype(int)
2
3
前面做One-Hot的时候,pandas默认生成的列是True/False类型,不是1/0。有些模型不吃True/False,只吃数字。所以把True变1,False变0。
select_dtypes(include=['bool']) 就是找出所有布尔类型的列,然后逐个转成int。
总结编码这块:
| 类型 | 方法 | 适用场景 | 结果 |
|---|---|---|---|
| 选项少(2-5个) | One-Hot | fuelType、gearbox | 每个选项一列,0或1 |
| 选项多(几十上百个) | Label | brand、model | 一列数字编号 |
| True/False | astype(int) | One-Hot生成的列 | True→1,False→0 |
# 选特征
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
numeric_cols = [col for col in numeric_cols if col != 'price']
correlations = df[numeric_cols].corrwith(df['price']).abs().sort_values(ascending=False)
2
3
4
# 第一步:计算相关性
df.select_dtypes(include=[np.number])
从所有列里挑出数字类型的列。因为相关性只能算数字列,文字列算不了。经过前面的编码,文字列基本都变数字了,但可能还留着原始的文字列(比如brand原文还在),所以先筛一遍。
[col for col in numeric_cols if col != 'price']
从数字列里把price踢出去。为啥?因为price是你要预测的目标,你不能拿目标来预测目标。
df[numeric_cols].corrwith(df['price'])
corrwith就是"算相关系数"。相关系数衡量两个东西的关系有多紧密:
- 1:完全正相关——A越大B越大
- -1:完全负相关——A越大B越小
- 0:没关系——A怎么变B都不受影响
举个例子:
- 车龄和价格:车龄越大价格越低 → 负相关,比如-0.6
- 品牌均价和价格:品牌越贵车越贵 → 正相关,比如0.8
- 注册月份和价格:几乎没关系 → 接近0
.abs() 取绝对值。因为不管是正相关还是负相关,绝对值越大说明关系越强。我只想知道"关系强不强",不关心"正还是负"。
.sort_values(ascending=False) 从大到小排,相关性最强的排最前面。
# 第二步:删除低相关特征
low_corr = correlations[correlations < 0.01].index.tolist()
if low_corr:
df = df.drop(columns=low_corr)
2
3
相关系数小于0.01的特征,说明它跟价格几乎没关系,留着只会干扰模型,删掉。
就像你预测一个人工资高低,"他身份证尾号是几"这个信息跟工资没关系,留着反而可能让模型走歪——万一碰巧训练数据里身份证尾号8的人工资都高,模型就学了个错误规律。
df.drop(columns=low_corr) 删除指定的列,columns=告诉它删列不删行。
我拿具体数据带你走一遍。
假设经过前面算相关性之后,correlations长这样:
brand_mean_price 0.8521
model_mean_price 0.7832
car_age -0.6234
power 0.5421
kilometer -0.4312
city_count 0.0082
reg_month 0.0031
name 0.0015
2
3
4
5
6
7
8
# 第一步:筛选出小于0.01的
correlations[correlations < 0.01]
这行是拿条件去筛选,就像Excel里筛选"小于0.01的行"。
结果:
city_count 0.0082
reg_month 0.0031
name 0.0015
2
3
只剩这3个不够格的。
# 第二步:取列名
.index.tolist()
.index 取索引(就是列名),.tolist() 转成Python列表。
结果:
low_corr = ['city_count', 'reg_month', 'name']
现在你要删的列名拿到了。
# 第三步:判断有没有要删的
if low_corr:
if low_corr 就是"如果这个列表不是空的"。如果所有特征相关性都大于0.01,low_corr就是空列表[],空列表相当于False,就不执行里面。
现在有3个要删的,所以进去执行。
# 第四步:删除
df = df.drop(columns=low_corr)
drop 是删除,columns=low_corr 告诉它删列,删哪些?删low_corr列表里的那些。
删完之后,city_count、reg_month、name这三列就从数据里消失了。
完整走一遍就是:
correlations(所有特征的相关性)
↓ 筛选 < 0.01
得到低相关特征:city_count、reg_month、name
↓ 判断有没有
有,3个
↓ drop删列
数据少了3列
2
3
4
5
6
7
就这几步,本质上就是:找出没用的 → 删掉。
# 第三步:处理共线性
stat_cols = ['brand_mean_price', 'brand_median_price',
'model_mean_price', 'model_median_price', 'city_mean_price']
existing = [c for c in stat_cols if c in df.columns]
if len(existing) > 1:
corr_matrix = df[existing].corr()
to_remove = []
for i in range(len(existing)):
for j in range(i+1, len(existing)):
if abs(corr_matrix.iloc[i, j]) > 0.95:
col1, col2 = existing[i], existing[j]
if abs(df[col1].corr(df['price'])) < abs(df[col2].corr(df['price'])):
to_remove.append(col1)
else:
to_remove.append(col2)
to_remove = list(set(to_remove))
if to_remove:
df = df.drop(columns=to_remove)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
共线性是啥? 就是两个特征说的几乎是同一件事。
比如brand_mean_price(品牌均价)和brand_median_price(品牌中位价),这俩数字通常很接近,相关系数可能高达0.98。它们俩同时在,等于同一个信息说了两遍。
为什么要删? 因为冗余信息会干扰模型。就像你听两个人同时说同一件事,不是更清楚,而是更吵。模型可能会在两个特征之间摇摆,反而学不稳定。
我一步一步来,用具体数据带你走。
# 先搞懂:corr() 会生成什么
假设我们有5个统计特征,它们跟price的相关性是这样的:
brand_mean_price → 跟price相关性 0.85
brand_median_price → 跟price相关性 0.82
model_mean_price → 跟price相关性 0.78
model_median_price → 跟price相关性 0.76
city_mean_price → 跟price相关性 0.45
2
3
4
5
然后df[existing].corr()算出来它们两两之间的相关性:
brand_mean brand_median model_mean model_median city_mean
brand_mean 1.00 0.98 0.45 0.43 0.30
brand_median 0.98 1.00 0.44 0.42 0.29
model_mean 0.45 0.44 1.00 0.97 0.28
model_median 0.43 0.42 0.97 1.00 0.27
city_mean 0.30 0.29 0.28 0.27 1.00
2
3
4
5
6
这就是一个5×5的矩阵,每个格子是两个特征之间的相关系数。
# 现在看代码,逐行拆
第一行:确定要检查哪几列
stat_cols = ['brand_mean_price', 'brand_median_price',
'model_mean_price', 'model_median_price', 'city_mean_price']
existing = [c for c in stat_cols if c in df.columns]
2
3
定义了5个要检查的特征名,然后看看数据里实际存在几个(万一前面被删了就不在了)。
第二行:算相关矩阵
corr_matrix = df[existing].corr()
就是上面那个5×5的表。
第三行:准备一个空袋子装要删的列名
to_remove = []
第四行:双重循环,两两比较
for i in range(len(existing)):
for j in range(i+1, len(existing)):
2
为什么要双重循环?因为你需要每两个特征比一次。
5个特征,两两组合有这些:
- 0和1、0和2、0和3、0和4
- 1和2、1和3、1和4
- 2和3、2和4
- 3和4
一共10对。i从0开始,j从i+1开始,这样就每对只比一次,不会重复。
第五行:检查这对特征是否高度相关
if abs(corr_matrix.iloc[i, j]) > 0.95:
corr_matrix.iloc[i, j] 是矩阵里第i行第j列的值,就是这两个特征的相关系数。
abs() 取绝对值,> 0.95 判断是否超过0.95。
走一遍10对:
| 组合 | 相关系数 | 超过0.95? |
|---|---|---|
| brand_mean vs brand_median | 0.98 | ✅ 超了 |
| brand_mean vs model_mean | 0.45 | ❌ |
| brand_mean vs model_median | 0.43 | ❌ |
| brand_mean vs city_mean | 0.30 | ❌ |
| brand_median vs model_mean | 0.44 | ❌ |
| brand_median vs model_median | 0.42 | ❌ |
| brand_median vs city_mean | 0.29 | ❌ |
| model_mean vs model_median | 0.97 | ✅ 超了 |
| model_mean vs city_mean | 0.28 | ❌ |
| model_median vs city_mean | 0.27 | ❌ |
只有2对超过0.95。
第六行:两列高度相关,留谁删谁?
col1, col2 = existing[i], existing[j]
if abs(df[col1].corr(df['price'])) < abs(df[col2].corr(df['price'])):
to_remove.append(col1)
else:
to_remove.append(col2)
2
3
4
5
逻辑很简单:两个特征说差不多的话,保留跟price关系更强的那个,删掉更弱的。
第一对:brand_mean(0.85) vs brand_median(0.82)
- brand_mean跟price相关性0.85
- brand_median跟price相关性0.82
- 0.85 > 0.82,所以删brand_median,留brand_mean
第二对:model_mean(0.78) vs model_median(0.76)
- model_mean跟price相关性0.78
- model_median跟price相关性0.76
- 0.78 > 0.76,所以删model_median,留model_mean
此时 to_remove = ['brand_median_price', 'model_median_price']
第七行:去重
to_remove = list(set(to_remove))
万一多个特征对都指向同一个要删的,用set去重。比如两对都删了brand_median,那就只留一个。
这里没有重复,所以还是 ['brand_median_price', 'model_median_price']。
第八行:删列
if to_remove:
df = df.drop(columns=to_remove)
2
把这2列从数据里删掉。
完整流程图:
5个统计特征
↓ 两两算相关系数
得到5×5矩阵
↓ 找出相关系数>0.95的对
brand_mean ↔ brand_median(0.98)
model_mean ↔ model_median(0.97)
↓ 每对里,删跟price关系弱的
删brand_median(0.82 < 0.85)
删model_median(0.76 < 0.78)
↓ 去重
还是这2个
↓ drop删列
数据少了2列
2
3
4
5
6
7
8
9
10
11
12
13
为什么要做这件事? 一句话:两个特征说几乎一样的话,同时留着是废话,反而让模型学的时候分不清该信谁。留一个就够了。
通用特征工程五步法
不管什么领域,你拿到数据都按这个顺序走:
# 第一步:摸清数据类型
每一列要么是数字,要么是类别,先分清楚。
| 类型 | 例子 | 特征工程思路不同 |
|---|---|---|
| 数字 | 价格、年龄、温度、面积 | 直接用、做分组、做比率 |
| 类别 | 品牌、城市、性别、学历 | 编码成数字、做统计特征 |
这一步不需要你懂业务,看数据类型就够了。
# 第二步:数字特征 → 三招
第1招:直接用
大部分数字特征本身就有用,比如车龄、公里数,不用动。
第2招:分组
把连续数字切成几档。怎么切?
- 按常识切:年龄→未成年/青年/中年/老年,你知道18和60是分界线
- 按分位数切:没有常识就用数据说话——前25%一档、25%-50%一档、50%-75%一档、后25%一档
df['age_group'] = pd.qcut(df['age'], q=4, labels=['低', '中低', '中高', '高'])
qcut会自动按数据分布切成4等份,每份数量差不多。你不懂业务也能用。
第3招:做比率
A除以B,往往比单独看A或B更有信息量。
通用公式:
- A / B:单价、均值、密度(面积/人口、收入/工时)
- A - B:差额(实际收入-预期收入)
- A × B:交互(面积×单价=总价)
什么时候该做比率? 你问自己一个问题:"单独看A有意义吗?如果B不同,A的含义会变吗?"
比如:
- 收入10万,在北京算穷,在小城市算富 → 收入要除以当地均价
- 面积100平,在住宅算大,在商铺算小 → 面积要配合用途看
只要你发现"同一个数字在不同条件下含义不同",就该做比率或分组。
# 第三步:类别特征 → 两招
第1招:编码成数字(前面讲过了,One-Hot和Label)
第2招:做target encoding(目标编码)
这一招是普适的、最强的,不管什么领域都能用。
做法就是:按这个类别分组,算目标变量的统计量。
- 按城市分组算均价 → 城市均价
- 按店铺分组算销量中位数 → 店铺销量中位数
- 按用户分组算点击率 → 用户点击率
你不需要懂业务,你就对每个类别列都做一遍groupby+agg,准没错。
为什么好用? 因为类别本身是抽象的,模型不知道"城市3"是贵还是便宜。但你算出城市3的均价是8000,模型立刻就懂了。
# 第四步:交叉特征 → 通用方法
你不需要懂业务才能做交叉,有一个暴力但有效的方法:
把所有类别特征两两组合,都做一遍target encoding。
假设你有5个类别特征,两两组合有10对,每对算一个均价,你就多了10个特征。大部分可能没啥用,后面选特征的时候会被筛掉,但有用的那几个会留下来。
# 暴力交叉:所有类别列两两组合
cat_cols = ['brand', 'bodyType', 'gearbox', 'city', 'fuelType']
for i in range(len(cat_cols)):
for j in range(i+1, len(cat_cols)):
col1, col2 = cat_cols[i], cat_cols[j]
new_col = f"{col1}_{col2}_price"
stats = df.groupby([col1, col2])['price'].mean().reset_index()
stats.columns = [col1, col2, new_col]
df = df.merge(stats, on=[col1, col2], how='left')
2
3
4
5
6
7
8
9
不需要动脑子,循环一跑全出来。
# 第五步:选特征 → 通用方法
跟前面讲的一样,两步:
- 删低相关:跟目标变量相关性太低的删掉
- 删高共线:两个特征太像的留一个
这两步不需要任何业务知识,纯看数据。
# 总结:普适流程
| 步骤 | 做什么 | 需要业务知识吗 |
|---|---|---|
| 1. 分类型 | 数字列 vs 类别列 | 不需要 |
| 2. 数字特征 | 分组 + 做比率 | 分组需要一点,比率看情况 |
| 3. 类别特征 | target encoding | 不需要 |
| 4. 交叉特征 | 两两组合暴力做 | 不需要 |
| 5. 选特征 | 删低相关 + 删共线 | 不需要 |
5步里只有第2步偶尔需要业务知识,其他4步都是纯数据驱动的,换个领域一样这么干。
所以以后你拿到一个新项目,不管是什么领域,先跑一遍这个流程,基准成绩就出来了。然后再根据你对业务的了解,手动加一些有针对性的特征,那是锦上添花。
# 第四步:选模型思路
不急着写代码,先把思路理清楚。
# Step4 到底在干什么
前三步你在做一件事:把数据变成模型能吃的东西。清洗、造特征、编码,都是准备食材。
Step4开始进入新阶段:选一个模型,让它从数据里学规律。
但你不能上来就选一个模型用到死,因为你不知道哪个模型适合你的数据。所以Step4的本质是——试几个模型,对比效果,选最好的那个当主力。
# 怎么思考"选模型"这件事
问自己三个问题,按顺序来:
第一:我的任务是什么类型?
这个决定了你能选哪些模型。你预测的是价格(连续数字),不是分类(猫/狗),所以:
- 用的是回归模型(Regressor),不是分类模型(Classifier)
- 评估指标是MAE(预测价和真实价差多少),越小越好
如果你预测的是"这车会不会卖出去",那就是分类任务,用的是Classifier。任务类型决定了方向,方向错了后面全白费。
第二:我有什么模型可以选?
你之前学了这些算法:决策树、随机森林、SVM、逻辑回归、朴素贝叶斯、XGBoost、LightGBM、CatBoost
但不是每个都适合你现在的场景,要逐一排除:
- 逻辑回归:名字里有"回归"但其实是分类用的,排除
- 朴素贝叶斯:也是分类用的,排除
- SVM:回归版叫SVR,但15万行数据跑SVR极慢,排除
- 决策树:单棵树太弱,容易过拟合,不如直接用集成方法
- CatBoost:可以用,但安装经常踩坑,先不碰
剩下三个:随机森林、XGBoost、LightGBM
随机森林是Bagging思路,XGBoost和LightGBM是Boosting思路。你之前学过区别——Boosting是后面的树纠正前面的错误,通常效果更好。
第三:怎么对比才算公平?
不能把所有数据都给模型学,然后又用同样的数据考试——那叫"开卷考",考出来的分数没意义,因为模型可能只是死记硬背了答案(过拟合)。
所以要把数据劈成两份:
- 训练集(80%):给模型学习用
- 验证集(20%):模型没见过的数据,用来考试
三个模型用同一份训练集学、同一份验证集考,MAE最低的那个就是当前最好的。
# 为什么是这个顺序
选任务类型 → 筛候选模型 → 公平对比 → 选最优
而不是"别人用什么我就用什么"。因为不同数据适合的模型不一样,别人用LightGBM效果好,可能是因为他的数据特征跟你的不同。你得自己跑一遍才知道。
# 对比完之后呢
Step4只是"初选",得到一个排名。比如LightGBM最好、XGBoost差不多、随机森林差一截。
接下来的Step5会用最优模型做更靠谱的验证(交叉验证),Step6调参数再压一波分数,Step7把几个模型融合起来——但那些都是后话,前提是Step4先把"哪个模型最有潜力"搞清楚。
# 总结一句话
Step4的核心思路就是:用排除法缩小候选范围,用公平测试选出赢家,不靠猜靠数据说话。
# 第四步:选择模型
"""
Step 4: 二手车价格预测 - 模型选择
======================================
本步骤要做的事情:
1. 把数据分成学习用和考试用两个部分
2. 用三个模型分别学习和考试
3. 对比成绩,选出最好的模型
就想上次说的
- 80%的数据当课本,让模型学习
- 20%的数据当模拟卷,考模型没见过的题
- 三个候选人:随机森林,XGBoost, LightGBM
- 谁MAE最低,谁就是赢家
"""
# =========================================
# 第一步 导入需要用到的工具
# =========================================
import pandas as pd
import numpy as np
import warnings
# ------数据切割工具------
from sklearn.model_selection import train_test_split # 把数据劈成训练集和验证集
# ------三个候选模型------
from sklearn.ensemble import RandomForestRegressor # 随机森林(回归版)
from xgboost import XGBRegressor # XGBoost(回归版)
from lightgbm import LGBMRegressor # LightGBM(回归版)
# -----评分工具------
from sklearn.metrics import mean_absolute_error # MAE计算器
# 忽略一些不重要的警告,让输出更干净
warnings.filterwarnings('ignore')
# 打印分割线
print("="*60)
print("step4 二手车价格预测 - 模型选择")
print("="*60)
# ========================================
# 第二步: 读取Step3特征工程后的数据
# ========================================
print("\n>>> 正在读取Step3特征工程后的数据")
data_path = "./used_car_train_featured.csv"
# 读取数据
df = pd.read_csv(data_path, sep=" ")
print(" 数据读取成功! ")
print(f" - 数据量:{df.shape[0]} 行 ")
print(f" - 列数{df.shape[1]} 列 ")
# =========================================
# 第三步: 准备 x 和 y
# =========================================
print("\n" + "="*60)
print("[准备数据]把数据拆成X(题目)和y(答案)")
print("="*60)
# -----3.1 分离目标变量 ------
print("\n>>> 3.1 分离目标变量 price")
# y = 答案 (我们要预测的东西:价格)
y = df['price']
# X = 题目(用来预测价格的特征)
# 我们要删掉price列,还有一些文字列(模型只认数字)
drop_cols = ['price'] # 必须删掉答案,不然就是作弊了
# 还要删掉Step3中没被编码的原始文字列(如果还存在的话)
# 这些列里是中文或文字,模型看不懂,编码后的 _code 列才是数字版
text_col_to_drop = ['car_age_group'] # 车龄分组的文字版,已经有_code 列了
for col in text_col_to_drop:
if col in df.columns and col not in drop_cols:
drop_cols.append(col)
# 生成 X: 从df里删掉答案列和文字列
X = df.drop(columns=drop_cols)
# 只保留数字类型的列(把漏网的文字列去掉)
X = X.select_dtypes(include=[np.number])
print(f" ✓ 目标变量 y:price,共 {len(y)} 个值")
print(f" ✓ 特征矩阵 X:{X.shape[1]} 个特征,{X.shape[0]} 条数据")
print(f" ✓ 使用了以下特征:")
for i,col in enumerate(X.columns, 1):
print(f" {i:2d}.{col}")
# ------- 3.2 处理缺失值 ------
print("\n>>> 3.2 检查并处理缺失值...")
# 看看 X 里还有没有空值
missing_count = X.isnull().sum().sum()
print(f" X 中缺失值总数 {missing_count}")
if missing_count > 0:
# 如果有缺失值,用该列的中位数填充
# 为什么用中位数不用平均值?因为中位数不怕极端值干扰
X = X.fillna(X.median())
print(f" ✓ 已用中位数填充所有缺失值")
else:
print(f" ✓ 没有缺失值,不需要处理")
# =====================================================
# 第四步: 切割数据 - 课本和模拟卷
# =====================================================
print("\n" + "=" * 60)
print("【切割数据】把数据分成训练集(课本)和验证集(模拟卷)")
print("=" * 60)
# train_test_split 就是切蛋糕的工具
# 参数解释:
# X, y -> 题目和答案
# test_size = 0.2 -> 20%当模拟卷,80%当课本
# random_state = 42 -> 随机种子,保证每次切出来的结果一样
X_train, X_val, y_train, y_val = train_test_split(
X, y,
test_size=0.2,
random_state=42
)
print(f" ✓ 数据切割完成!")
print(f" - 训练集(课本):{X_train.shape[0]} 条,占 80%")
print(f" - 验证集(模拟卷):{X_val.shape[0]} 条,占 20%")
# ============================================
# 第五步: 三个模型分别面试
# ============================================
print("\n" + "=" * 60)
print("【模型面试】三个候选人依次上场")
print("=" * 60)
# 用一个字典来储存结果,方便最后对比
results = {}
# ----5.1 候选人1:随机森林 ------
print("\n" + "-" * 60)
print(">>> 候选人1:随机森林(RandomForest)")
print(" 特点:老实人,经验丰富,不容易犯错,但也不会特别出彩")
print("-" * 60)
# 创建随机森林
# 参数解释:
# n_estimators = 100 -> 种100颗树(树越多越稳,但越慢)
# random_state = 42 -> 同样固定随机种子
# n_jobs = -1 -> 用电脑所有CPU核心加速
rf_model = RandomForestRegressor(
n_estimators=100,
random_state=42,
n_jobs=-1
)
print(" 正在学习课本(训练中)...")
rf_model.fit(X_train, y_train) # fit = 学习,把课本喂给模型
print(" 正在做模拟卷(预测中)...")
rf_pred = rf_model.predict(X_val) # predict = 考试,让模型做模拟卷
# 算成绩:MAE = 平均差多少钱
# MAE越小越好,比如MAE = 500说明平均猜差500块
rf_mae = mean_absolute_error(y_val, rf_pred)
print(f" ✓ 成绩出来了!MAE = {rf_mae:.2f}")
print(f" (意思是:平均每辆车猜差 {rf_mae:.2f} 元)")
results["随机森林"] = rf_mae
# -------5.2 候选人2:XGBoost -------
print("\n" + "-" * 60)
print(">>> 候选人2:XGBoost")
print(" 特点:精明人,会从错误中学习,上一题做错下一题就注意了")
print("-" * 60)
# 创建XGBoost模型
# 参数解释:
# n_estimators=100 -> 学习100轮
# learning_rate=0.1 -> 每轮学习的步子大小(太大容易走偏,太小容易学得慢)
# max_depth = 6 -> 每棵树最深长6层(太深容易死记硬背=过拟合)
# random_state=42 -> 固定随机种子
# n_jobs = -1 -> 多核加速
xgb_model = XGBRegressor(
n_estimators=100,
learning_rate=0.1,
max_depth=6,
random_state=42,
n_jobs=-1
)
print(" 正在学习课本(训练中)...")
xgb_model.fit(X_train, y_train)
print(" 正在做模拟卷(预测中)...")
xgb_pred = xgb_model.predict(X_val)
xgb_mae = mean_absolute_error(y_val, xgb_pred)
print(f" ✓ 成绩出来了!MAE = {xgb_mae:.2f}")
print(f" (意思是:平均每辆车猜差 {xgb_mae:.2f} 元)")
results["XGBoost"] = xgb_mae
# ------5.3 候选人3:LightGBM ----
print("\n" + "-" * 60)
print(">>> 候选人3:LightGBM")
print(" 特点:跟XGBoost同类型,但干活更快,思路差不多")
print("-" * 60)
# 创建LightGBM模型
# 参数解释跟XGBoost类似
# n_estimators=100 → 学习100轮
# learning_rate=0.1 → 学习步子大小
# max_depth=6 → 树最大深度
# random_state=42 → 固定随机种子
# n_jobs=-1 → 多核加速
# verbose=-1 → 不输出训练日志(太啰嗦了)
lgb_model = LGBMRegressor(
n_estimators=100,
learning_rate=0.1,
max_depth=6,
random_state=42,
n_jobs=-1,
verbose=-1
)
print(" 正在学习课本(训练中)...")
lgb_model.fit(X_train, y_train)
print(" 正在做模拟卷(预测中)...")
lgb_pred = lgb_model.predict(X_val)
lgb_mae = mean_absolute_error(y_val, lgb_pred)
print(f" ✓ 成绩出来了!MAE = {lgb_mae:.2f}")
print(f" (意思是:平均每辆车猜差 {lgb_mae:.2f} 元)")
results['LightGBM'] = lgb_mae
# ========================================
# 第六步: 公布面试结果
# ========================================
print("\n" + "=" * 60)
print("【面试结果】三位候选人成绩对比")
print("=" * 60)
# 按MAE从小到大排序(越小越好)
sorted_results = sorted(results.items(), key=lambda x: x[1])
print("\n 排名 模型名称 MAE成绩")
print(" " + "-" * 40)
for rank, (name, mae) in enumerate(sorted_results, 1):
# 第一名加个★标记
medal = "★" if rank == 1 else " "
print(f" {medal} {rank} {name:<12} {mae:.2f}")
# 获胜者
winner = sorted_results[0][0]
winner_mae = sorted_results[0][1]
print(f"\n 🏆 获胜者:{winner}!MAE = {winner_mae:.2f}")
print(f" 下一步(Step5)会用 {winner} 做更严格的交叉验证")
# ============================================================
# 第七步:看看获胜模型觉得哪些特征最重要
# ============================================================
print("\n" + "=" * 60)
print("【特征重要性】获胜模型觉得哪些特征最有用?")
print("=" * 60)
# 拿到获胜模型的特征重要性
if winner == '随机森林':
importances = rf_model.feature_importances_
elif winner == 'XGBoost':
importances = xgb_model.feature_importances_
else:
importances = lgb_model.feature_importances_
# 把特征名和重要性绑在一起,按重要性排序
feature_importance = pd.DataFrame({
'特征名称': X.columns,
'重要性': importances
}).sort_values('重要性', ascending=False)
print(f"\n {winner} 认为最重要的 Top10 特征:")
print(" 排名 特征名称 重要性")
print(" " + "-" * 55)
for i, row in enumerate(feature_importance.head(10).itertuples(), 1):
print(f" {i:2d} {row.特征名称:<30} {row.重要性:.4f}")
print("\n" + "=" * 60)
print("Step4 模型选择完成!")
print(f"最终选定模型:{winner}")
print("=" * 60)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
# 第一块:导入工具(第1-25行)
import pandas as pd
import numpy as np
import warnings
2
3
这三个你在Step1-3都见过,老朋友不说了。
from sklearn.model_selection import train_test_split
这是今天的核心工具之一。train_test_split 的作用就一个字:切。把你的数据切两半,一块学习一块考试。
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
2
3
三个候选人登场。注意每个名字后面都带 Regressor——就是"回归版"的意思。你预测的是价格(数字),所以用回归版。如果预测的是"会不会卖出去"(是/否),就要换成 Classifier(分类版)。
from sklearn.metrics import mean_absolute_error
这是判卷老师。你给它标准答案和模型的预测答案,它帮你算MAE——平均猜差多少钱。
# 第二块:读数据(第38-44行)
跟前三步一样,读Step3产出的 featured.csv。不细说了。
# 第三块:准备X和y(第49-72行)——关键!
y = df['price']
y = 答案。我们最终要预测的就是price这一列,把它单独拎出来。
X = df.drop(columns=drop_cols)
X = X.select_dtypes(include=[np.number])
2
X = 题目。两步走:
- 删掉price列(答案不能给模型看到,否则就是作弊)
- 只保留数字列(模型只认识数字,中文/文字列要干掉)
X = X.fillna(X.median())
如果还有空值,用中位数填。为什么不用平均值?举个例子:10个人,9个人月薪5千,1个人月薪500万。平均数被那个人拉到50万,中位数还是5千。中位数不怕极端值。
# 第四块:切蛋糕(第78-92行)——全篇最关键!
X_train, X_val, y_train, y_val = train_test_split(
X, y,
test_size=0.2,
random_state=42
)
2
3
4
5
这一行干了4件事,我拆开给你看:
| 输出 | 是什么 | 从哪来 | 多少 |
|---|---|---|---|
X_train | 课本的题目 | X的80% | 12万条 |
y_train | 课本的答案 | y的80% | 12万条 |
X_val | 模拟卷的题目 | X的20% | 3万条 |
y_val | 模拟卷的答案 | y的20% | 3万条 |
test_size=0.2 就是"20%当考试"。
random_state=42 是什么?想象你洗牌——每次洗出来的顺序不一样。但如果你说"第42号洗法",每次都是同样的顺序。这样你今天跑和明天跑,切出来的数据一模一样,方便对比。 42这个数字本身没意义,写0、写123都行,但大家习惯写42(程序员老梗)。
# 第五块:三个模型面试(第98-174行)
三个模型的结构一模一样,就三步:创建 → 学习(fit) → 考试(predict) → 打分(MAE)
拿随机森林举例:
rf_model = RandomForestRegressor(
n_estimators=100,
random_state=42,
n_jobs=-1
)
2
3
4
5
这是招人——告诉模型"你是谁、怎么干活":
n_estimators=100:种100棵决策树,然后投票。树越多越稳,但也越慢n_jobs=-1:用电脑所有CPU核心一起干活,加速
rf_model.fit(X_train, y_train)
这是学习——把课本(X_train)和答案(y_train)喂给模型。fit就是"拟合",模型从数据里找规律。
rf_pred = rf_model.predict(X_val)
这是考试——给模型模拟卷的题目(X_val),让它猜答案。它不知道真实答案,全凭学到的规律猜。
rf_mae = mean_absolute_error(y_val, rf_pred)
这是打分——拿模型猜的答案(rf_pred)跟真实答案(y_val)对比,算出MAE。
XGBoost和LightGBM多两个参数:
learning_rate=0.1, # 学习步子大小——每轮修正多少
max_depth=6, # 树最深几层——太深=死记硬背(过拟合)
2
learning_rate:想象你往目标走,步子太大容易走过头,步子太小走太慢。0.1是经验值,不大不小刚刚好max_depth:树长6层。树越深,模型越"聪明"(能学到更细的规律),但也越容易"死记硬背"(把训练数据背下来而不是学规律)
# 第六块:公布成绩(第180-198行)
sorted_results = sorted(results.items(), key=lambda x: x[1])
按MAE从小到大排。MAE越小 = 猜得越准 = 成绩越好。
# 第七块:特征重要性(第204-228行)
importances = rf_model.feature_importances_
模型学完之后,会告诉你"我觉得哪些特征最有用"。就像老师考完试说"这道题占分最多"。
这个信息很有用——如果某个特征重要性很低,说明它对预测没啥帮助,后面可以考虑删掉,精简数据。
# 整个流程一句话总结
读数据 → 拆出X和y → 切80/20 → 三个模型各自fit→predict→算MAE → 排名选赢家
XGBoost原理
用最简单的话说:
普通决策树:一棵树做判断,容易看错
随机森林:种100棵树,每棵独立看,投票决定
XGBoost:也是种100棵树,但不是独立的——
第1棵树先猜,猜完了看哪道题做错了
第2棵树专门练第1棵做错的题
第3棵树专门练前两棵都做错的题
……以此类推
就像你做题,第一遍全做,第二遍只做错题,第三遍只做第二遍还错的,每遍都在补前一遍的短板。这就是Boosting的核心思路。
XGBoost全称是 eXtreme Gradient Boosting,"极端梯度提升"。梯度就是"哪边错得最多就往哪边使劲"。 //
参数是随便给还是有方法
现在给的是经验默认值,不是随便给的,但也不是最优的。 后面Step6就是专门调参的。
现在先用默认值把三个模型比一轮,选出赢家后,再给赢家精调参数,就像先面试选人,入职后再培训。
# 第五步 交叉验证思路
# 为什么需要交叉验证?
上一步你把数据劈成80%和20%,80%学,20%考,随机森林考了620分。
但问题来了:这620分靠不靠谱?
你想,切数据的时候是随机切的。万一那20%的考题恰好都是简单题呢?那分数就虚高。万一恰好都是难题呢?分数就偏低。
就像你平时考试,碰上简单卷子考90,碰上难卷子考70,你到底多少水平?一次考试说不准。
交叉验证就是让你考多次,取平均分,看真本事。
# 具体怎么操作?
最常用的是K折交叉验证,一般K=5,就是5折。
把所有数据平均切成5份,编号1到5:
| 轮次 | 当"课本"学的 | 当"考卷"考的 |
|---|---|---|
| 第1轮 | 2、3、4、5 | 1 |
| 第2轮 | 1、3、4、5 | 2 |
| 第3轮 | 1、2、4、5 | 3 |
| 第4轮 | 1、2、3、5 | 4 |
| 第5轮 | 1、2、3、4 | 5 |
每一轮,换一份当考卷,其余当课本。5轮下来,每一条数据都当过一次考题,不存在"运气好碰上简单题"的问题。
最后你拿到5个分数,算个平均分,这就是模型的真实水平。
# 交叉验证能告诉我们什么?
三个关键信息:
1. 平均分 → 模型到底行不行
5次考试平均620,比一次考620可信多了。
2. 分数波动 → 模型稳不稳
5次分数分别是610、615、620、625、630,波动小,说明模型很稳。
5次分数分别是580、600、620、650、680,波动大,说明模型看数据脸色,换个数据就不一样,这不行。
3. 对比三个模型的真实排名
之前随机森林一次620排第一,但XGBoost和LightGBM用的也是同一次考试的成绩。现在三个模型都考5次,谁的平均分低且波动小,谁才是真大哥。
# 一句话总结
单次考试看运气,五次考试看实力。交叉验证就是让模型反复考,挤出运气的水分,露出真本事。
# 第五步 交叉验证
# 第五步:交叉验证 - 让模型考 5 次,挤出运气水分
import pandas as pd
import numpy as np
from sklearn.model_selection import cross_val_score, KFold
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
# ========= 1. 加载数据 ===============
df = pd.read_csv("used_car_train_featured.csv", sep=" ")
# 分离特征和目标
y = df['price']
X = df.drop(columns=['price'])
str_cols = X.select_dtypes(include=['object']).columns.tolist()
if str_cols:
print(f"发现字符串列,删除: {str_cols}")
X = X.drop(columns=str_cols)
print(f"数据形状: {X.shape}")
print(f"特征数量: {X.shape[1]}")
# ============ 2. 定义模型(默认参数,和Step4一致)============
models = {
'随机森林':RandomForestRegressor(
n_estimators=100,
random_state=42,
n_jobs=-1
),
'XGBoost': XGBRegressor(
n_estimators=100,
learning_rate=0.1,
max_depth=6,
random_state=42,
n_jobs=-1
),
'LightGBM': LGBMRegressor(
n_estimators=100,
learning_rate=0.1,
max_depth=6,
random_state=42,
n_jobs=-1,
verbose=-1
)
}
# ======== 3. 5折交叉验证 ==========
kf = KFold(n_splits=5, shuffle=True, random_state=42)
print("=" * 55)
print(f"{'模型':<10} {'平均MAE':<12} {'最低':<10} {'最高':<10} {'波动(标准差)':<12}")
print("=" * 55)
results = {}
for name, model in models.items():
# cross_val_score 默认返回负MAE,取绝对值
# scoring = 'neg_mean_absolute_error' -> 返回的是-MAE,所以取负
# 问题: 这里的参数解释一下,看不懂
scores = cross_val_score(
model,
X,
y,
cv=kf,
scoring='neg_mean_absolute_error',
n_jobs=-1
)
mae_scores = -scores # 转成正数
results[name] = {
'mean': mae_scores.mean(),
'std': mae_scores.std(),
'min': mae_scores.min(),
'max': mae_scores.max(),
'scores': mae_scores
}
print(f"{name:<10} {mae_scores.mean():<12.2f} {mae_scores.min():<10.2f} {mae_scores.max():<10.2f} {mae_scores.std():<12.2f}")
print("=" * 55)
# ========= 4. 每一折的详细分数 ===========
print("\n各模型每折MAE明细:")
print("-" * 55)
print(f"{'折数':<6}", end="")
for name in models:
print(f"{name:<14}", end="")
print("-" * 55)
for i in range(5):
print(f"第{i + 1}折 ", end="")
for name in models:
print(f"{results[name]['scores'][i]:<14.2f}", end="")
print()
# ============ 5. 对比Step4单次结果 ============
print("\n" + "=" * 55)
print("对比Step4单次测试 vs Step5交叉验证:")
print("-" * 55)
step4_scores = {'随机森林': 620.93, 'XGBoost': 663.23, 'LightGBM': 693.98}
for name in models:
cv_mean = results[name]['mean']
cv_std = results[name]['std']
single = step4_scores[name]
diff = cv_mean - single
print(f"{name}:")
print(f" Step4单次: {single:.2f} | Step5交叉验证: {cv_mean:.2f} ± {cv_std:.2f} | 差值: {diff:+.2f}")
# ============ 6. 保存结果 ============
result_df = pd.DataFrame({
name: results[name]['scores'] for name in models
}, index=[f'Fold_{i+1}' for i in range(5)])
result_df.loc['Mean'] = [results[name]['mean'] for name in models]
result_df.loc['Std'] = [results[name]['std'] for name in models]
result_df.to_csv('step5_cv_results.csv', encoding='utf-8-sig')
print(f"\n结果已保存到 step5_cv_results.csv")
# ============ 7. 总结判断 ============
print("\n" + "=" * 55)
best_model = min(results, key=lambda x: results[x]['mean'])
most_stable = min(results, key=lambda x: results[x]['std'])
print(f"平均MAE最低: {best_model} ({results[best_model]['mean']:.2f})")
print(f"最稳定(标准差最小): {most_stable} ({results[most_stable]['std']:.2f})")
print("=" * 55)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
# 第1部分:导入库
import pandas as pd
import numpy as np
from sklearn.model_selection import cross_val_score, KFold
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
2
3
4
5
6
pandas:读数据、处理表格numpy:数学计算(求平均、标准差等)cross_val_score:sklearn自带的交叉验证函数,帮你自动切数据、训练、打分KFold:定义怎么切数据(切几折、要不要打乱)RandomForestRegressor:随机森林回归模型XGBRegressor:XGBoost回归模型LGBMRegressor:LightGBM回归模型
# 第2部分:加载数据
df = pd.read_csv("used_car_train_featured.csv", sep=" ")
读取Step3输出的特征工程后的数据,空格分隔。
y = df['price']
X = df.drop(columns=['price'])
2
y:目标变量,就是你要预测的二手车价格X:特征,把price列去掉,剩下的都是给模型看的线索
str_cols = X.select_dtypes(include=['object']).columns.tolist()
if str_cols:
print(f"发现字符串列,删除: {str_cols}")
X = X.drop(columns=str_cols)
2
3
4
select_dtypes(include=['object']):找出所有"字符串类型"的列.columns.tolist():拿到这些列的名字,变成列表- 如果有字符串列,删掉它们(因为sklearn只能吃数字,它们的数字编码版已经在数据里了)
print(f"数据形状: {X.shape}")
print(f"特征数量: {X.shape[1]}")
2
X.shape返回(行数, 列数),比如(149887, 45)X.shape[1]就是列数,即特征数量
# 第3部分:定义模型
models = {
'随机森林': RandomForestRegressor(
n_estimators=100,
random_state=42,
n_jobs=-1
),
'XGBoost': XGBRegressor(
n_estimators=100,
random_state=42,
n_jobs=-1,
verbosity=0
),
'LightGBM': LGBMRegressor(
n_estimators=100,
random_state=42,
n_jobs=-1,
verbose=-1
)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这是一个字典,键是模型的名字(中文),值是模型对象。
三个参数解释:
n_estimators=100:种100棵树(三个模型都是树模型)random_state=42:随机种子,保证每次跑结果一样,方便对比n_jobs=-1:用所有CPU核心并行跑,加速verbosity=0/verbose=-1:关掉训练日志,不刷屏
# 第4部分:定义5折切法
kf = KFold(n_splits=5, shuffle=True, random_state=42)
n_splits=5:切成5折shuffle=True:先打乱再切,避免数据有顺序导致某折全是便宜车random_state=42:打乱的种子,保证每次切的折一样,三个模型面对同一套考卷
# 第5部分:打印表头
print("=" * 55)
print(f"{'模型':<10} {'平均MAE':<12} {'最低':<10} {'最高':<10} {'波动(标准差)':<12}")
print("=" * 55)
2
3
"=" * 55:55个等号,画分割线{值:<10}:左对齐,占10个字符宽度,前面讲过了
# 第6部分:核心——交叉验证循环
results = {}
空字典,用来存三个模型的成绩。
for name, model in models.items():
遍历models字典,每次拿一对:name是模型名,model是模型对象。第一轮 name='随机森林',model=RandomForestRegressor(...)。
scores = cross_val_score(
model, X, y,
cv=kf,
scoring='neg_mean_absolute_error',
n_jobs=-1
)
2
3
4
5
6
这是整个Step5最核心的一行,cross_val_score 帮你完成:
- 按kf的定义把数据切成5折
- 第1轮:用第2-5折训练,第1折考试 → 得分1
- 第2轮:用第1、3-5折训练,第2折考试 → 得分2
- ...依此类推,5轮
- 返回5个分数的数组
参数解释:
model:哪个模型去考X, y:全部数据(函数内部会自动按折切分)cv=kf:用前面定义的5折切法scoring='neg_mean_absolute_error':评分标准用MAE,sklearn的规矩加了个负号n_jobs=-1:多核并行
mae_scores = -scores
scores 是 [-618, -621, -615, -613, -623] 这样的负数,取负变回正常MAE:[618, 621, 615, 613, 623]。
results[name] = {
'mean': mae_scores.mean(),
'std': mae_scores.std(),
'min': mae_scores.min(),
'max': mae_scores.max(),
'scores': mae_scores
}
2
3
4
5
6
7
把5次成绩存进字典:
mean():5次的平均分std():5次的标准差(波动大小)min():5次最低分max():5次最高分mae_scores:原始5个分数的数组
存起来的目的是后面还要用(打印明细、对比Step4、总结判断)。
print(f"{name:<10} {mae_scores.mean():<12.2f} {mae_scores.min():<10.2f} {mae_scores.max():<10.2f} {mae_scores.std():<12.2f}")
打印一行结果。.2f 表示保留2位小数。
# 第7部分:每折详细分数
print(f"{'折数':<6}", end="")
for name in models:
print(f"{name:<14}", end="")
print()
2
3
4
打印表头:折数 随机森林 XGBoost LightGBM
end="":不换行,继续在同一行打印- 最后
print()换行
for i in range(5):
print(f"第{i+1}折 ", end="")
for name in models:
print(f"{results[name]['scores'][i]:<14.2f}", end="")
print()
2
3
4
5
- 外层循环5次(5折)
results[name]['scores'][i]:从结果字典里取第i折的分数- 比如
results['随机森林']['scores'][0]就是随机森林第1折的621.55 - 每行打印完
print()换行
# 第8部分:对比Step4
step4_scores = {'随机森林': 620.93, 'XGBoost': 663.23, 'LightGBM': 693.98}
Step4单次测试的成绩,手动填进去的。
for name in models:
cv_mean = results[name]['mean']
cv_std = results[name]['std']
single = step4_scores[name]
diff = cv_mean - single
print(f"{name}:")
print(f" Step4单次: {single:.2f} | Step5交叉验证: {cv_mean:.2f} ± {cv_std:.2f} | 差值: {diff:+.2f}")
2
3
4
5
6
7
diff:交叉验证平均分 - 单次分,正数说明交叉验证更差,负数说明更好{diff:+.2f}:+表示正数也显示加号,比如+1.51或-2.63
# 第9部分:保存结果
result_df = pd.DataFrame(
{name: results[name]['scores'] for name in models},
index=[f'Fold_{i+1}' for i in range(5)]
)
2
3
4
这是个字典推导式,构造一个DataFrame:
# 等价于:
{
'随机森林': array([621.55, 614.81, 619.47, 612.61, 623.04]),
'XGBoost': array([665.18, 663.60, 662.04, 660.68, 672.19]),
'LightGBM': array([693.98, 692.96, 691.24, 688.13, 693.73])
}
2
3
4
5
6
行索引是 Fold_1 到 Fold_5。
result_df.loc['Mean'] = [results[name]['mean'] for name in models]
result_df.loc['Std'] = [results[name]['std'] for name in models]
2
在DataFrame末尾追加两行:平均值和标准差。loc['Mean'] 是按行名定位。
result_df.to_csv('step5_cv_results.csv', encoding='utf-8-sig')
保存成CSV。utf-8-sig 是让Excel打开不乱码。
# 第10部分:总结判断
best_model = min(results, key=lambda x: results[x]['mean'])
most_stable = min(results, key=lambda x: results[x]['std'])
2
min(results, key=...):按什么规则找最小值lambda x: results[x]['mean']:匿名函数,给一个模型名x,返回它的平均MAE- 意思就是:在results的所有键里,找平均MAE最小的那个
等价于:
# 找平均MAE最低的
min_mae = 999999
best_model = ''
for name in results:
if results[name]['mean'] < min_mae:
min_mae = results[name]['mean']
best_model = name
2
3
4
5
6
7
lambda只是一行写法,更简洁。
整段代码就这些,核心其实就是 cross_val_score 那一个调用,其余都是准备数据、存结果、打印展示。
为什么要第四步和第五步
好问题,换个场景你就懂了。
# 打个比方
你要去参加一个跑步比赛,有三个选手可以选:A、B、C。
直接调参(跳过4和5)= 上来就给三个选手疯狂定制训练计划
但问题来了——你连他们三个谁跑得快、谁体力好、谁容易受伤都不知道,怎么定制?
给一个跑得慢但耐力好的选手练爆发力,方向就错了。
# Step4和Step5各干什么
| 步骤 | 干什么 | 为什么要干 |
|---|---|---|
| Step4 | 单次测试,看大致排名 | 知道谁强谁弱,心里有数 |
| Step5 | 交叉验证,确认排名靠谱 | 确认Step4不是运气,分数和稳定性都摸清了 |
这两步的本质是摸底——不是选最终模型,是搞清楚现状。
# 摸完底有什么用?
1. 调参知道往哪使劲
现在知道随机森林618、XGBoost 665、LightGBM 692。XGBoost差了快50分,调参空间大不大?随机森林已经很低了,调参能降多少?心里有预期,不会调完一头雾水。
2. 知道哪些参数值得调
Step5还告诉你标准差——LightGBM最稳(2.16),说明它发挥稳定,分数高是模型本身的问题,不是波动的问题,调参要调的是模型能力。如果某个模型波动特别大,说明它对数据敏感,调参可能要往正则化方向调(让它别太敏感)。
3. 调参后能对比
没有基准线,调完参你也不知道是变好了还是变差了。618→580,你知道降了38分。如果没跑过Step4和5,你只有一个580,孤零零的,没意义。
4. 排雷
刚才就排了一个雷——数据里有字符串列。如果不先跑Step4和5,直接调参,报错了你都不知道是参数的问题还是数据的问题。
# 一句话
Step4和5是体检,Step6是开药。不体检就开药,那是庸医。
# 第六步 调参思路
# 第六步要干什么?
给模型调参数,让它从裸考变成带装备上场。
# 什么是超参数?
模型有两类参数:
| 类型 | 谁定的 | 举例 |
|---|---|---|
| 普通参数 | 模型自己学出来的 | 每棵树怎么分叉、分多少条规则 |
| 超参数 | 你提前定的 | 种多少棵树、树最多多深、学习率多少 |
超参数就像车的出厂设置——你能开,但不是最快。调参就是改这些设置。
# 调哪几个?为什么?
# 1. 树的数量(n_estimators)
默认100棵。可能太少,学不透;也可能太多,浪费时间。得试。
# 2. 树的深度(max_depth)
默认不限制,树会一直长。长太深有什么问题?——把训练数据的噪音都背下来了,换个数据就不认识,这叫过拟合。
打个比方:一个学生把模拟卷的答案全背下来了,考试换道题就不会。限制深度就是让他学规律,别背答案。
# 3. 学习率(learning_rate)
每棵树往正确方向走多大步。
- 步子太大(0.2):可能冲过头,到了目标附近又冲出去,来回震荡
- 步子太小(0.01):走得太慢,要很多棵树才能到
一般规律:学习率小 + 树多 = 稳但慢,学习率大 + 树少 = 快但容易过拟合
# 4. 采样比例(subsample / colsample_bytree)
每次建一棵树,不用全部数据,只用一部分。
subsample:行采样,随机挑80%的样本colsample_bytree:列采样,随机挑80%的特征
为什么不全用?全用的话每棵树长得差不多,没多样性。采样子让每棵树看到不同的数据,就像5个医生各自看不同的病例,最后会诊,比一个医生看所有病例更靠谱。
# 怎么找最佳组合?
笨办法:把想试的参数列出来,挨个试。
比如树的数量试 [100, 200, 300, 500],深度试 [3, 5, 7, 9],学习率试 [0.01, 0.05, 0.1, 0.2]。
排列组合全试一遍叫网格搜索,但组合太多,576种×5折=2880次训练,跑一天。
所以用随机搜索:只随机抽30组试,大概率能碰到好的。因为大部分参数对结果影响不大,真正关键的就那两三个,随机30次几乎不可能全错过。
每一组参数还是用5折交叉验证打分,所以调参=调参数+交叉验证,两步合一。
# 调完之后会怎样?
预期:
- 随机森林:提升有限,因为它本身就不太吃参数,默认值已经很行了
- XGBoost:大概率大幅提升,它吃参数,调好了能从665降到600左右
- LightGBM:同理,应该也有明显提升
调完之后三个模型的排名很可能会变,XGBoost反超随机森林是大概率事件。
# 一句话总结
调参就是把"能跑"变成"跑得快",用随机搜索代替穷举,又快又管用。
参数范围怎么定
这些范围不是瞎写的,也不是万能通用的。分三层来说:
# 第一层:有经验值的参数
有些参数有大体的"安全区间",是大量实践总结出来的:
n_estimators(树的数量)
- 下限 100:再少就学不透了
- 上限 500:再多边际收益递减,还慢。竞赛里有人推到 1000-2000,但那是配合极小学习率用的
- 所以
[100, 200, 300, 500]是常规区间
max_depth(树的深度)
- 经验值 3-10 之间,极少超过 15
- 深度越大越容易过拟合。15万行数据算中等规模,3-9 够了
- 如果数据只有几千行,3-5 就得打住;如果有几百万行,10-15 也可以试
- 所以这个范围跟数据量有关
learning_rate(学习率)
- 经验区间 0.01-0.3,很少有人超过 0.3
- 0.1 是最常用的默认值
- 配合 n_estimators 有个规律:学习率小 → 树要多,学习率大 → 树可以少
subsample / colsample_bytree
- 0.6-1.0 之间,低于 0.6 每棵树看的数据太少,容易欠拟合
- 1.0 = 不采样,全部用,这是默认值
- 所以
[0.6, 0.7, 0.8, 0.9, 1.0]是合理区间
# 第二层:跟数据有关的参数
这些要根据你的数据特点来调:
min_child_weight / min_samples_leaf
- 控制叶子节点最小样本数,防过拟合
- 我们 15 万行数据,设
[1, 3, 5]是合理的 - 如果数据只有 5000 行,就得设更大比如
[5, 10, 20],不然每个叶子只有 1-2 个样本,太容易背答案
num_leaves(LightGBM 专属)
- 经验公式:
num_leaves ≤ 2^max_depth - max_depth 试 3-9,所以 num_leaves 试
[15, 31, 63](2^4≈15, 2^5≈31, 2^6≈63) - LightGBM 用 leaf-wise 生长,不设上限会疯狂长叶子
reg_alpha / reg_lambda(正则化)
- 这是给模型"踩刹车"的,防止学太猛
- 默认值基本是 0 或 1,调参时在附近试几个就行
- 不需要试很大,因为如果正则化太强,模型就学不动了
# 第三层:万能 vs 不万能
没有万能的参数范围。 但有"万能的定范围思路":
- 先看数据量:数据多 → 树可以多、可以深;数据少 → 树少点、浅点
- 先用默认值跑一次(Step4 已经做了),看模型是过拟合还是欠拟合
- 过拟合(训练集好、验证集差)→ 限制深度、加正则化、加采样
- 欠拟合(都差)→ 加树、加深、提高学习率
- 围绕默认值上下扩展:默认 100 棵树,就试 100 附近;默认深度 6,就试 3-9
- 别一上来就试极端值:学习率试到 1.0、深度试到 50 这种,基本没意义
# 一句话总结
参数范围 = 经验安全区间 × 数据量调整 × 默认值附近扩展。不是瞎写的,也不是万能的,是根据"15万行、回归任务、树模型"这个具体场景定的。
如果换个场景——比如 5000 行的图像分类——这些范围就得重新调。
# 第六步:超参调优
"""
Step6: 二手车价格预测 - 超参调优
=========================================
本步骤要做的事情:
1. 给三个模型调参数-从裸考变成带装备上场
2. 用随机搜索(RandomizedSearchCV)找最佳参数组合
3. 对比调参前后的成绩变化
上次讲的调参三件套:
- 树的数量(n_estimators): 多少颗树才够
- 树的深度(max_depth): 限高防过拟合(防背答案)
- 学习率(learning_rate):步子大小决定节奏
还有采样比例(subsample / colsample_bytree): 让每棵树看不同数据增加多样性
为什么用随机搜索不用网格搜索?
- 网格搜索全试 576种 * 5折 = 2880 次训练,太慢
- 随机搜索只试 30组, 大概率碰到好的组合
- 真正关键的参数就两三个,随机30次几乎不可能全错过
预期结果:
- 随机森林:提升优先,默认参数已经很行
- XGBoost / LightGBM 大概率大幅提升,它们吃参数
- 调完厚 XGBoost 反超随机森林是大概率事件
"""
# =========================================
# 第一步:导入工具
# =========================================
import pandas as pd
import numpy as np
import time # 计时器,看调参要花多久
import warnings
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV # 随机搜索调参工具
from sklearn.metrics import mean_absolute_error
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
warnings.filterwarnings("ignore")
print("=" * 60)
print("Step6: 二手车价格预测 - 超参调优")
print("=" * 60)
# ==============================================
# 第二步: 读取数据,准备X和y
# ==============================================
print("\n>>> 正在读取特征工程后的数据...")
data_path = "./used_car_train_featured.csv"
df = pd.read_csv(data_path, sep=" ")
print(f"✓ 数据读取成功!{df.shape[0]} 行 × {df.shape[1]} 列")
# 分离 X 和 y
y = df["price"]
drop_cols = ["price","car_age_group"]
X = df.drop(columns=drop_cols)
X = X.select_dtypes(include=[np.number])
# 填缺失值以防万一
if X.isnull().sum().sum() > 0:
X = X.fillna(X.median())
print(" ✓ 缺失值已用中位数填充")
print(f" ✓ 特征数:{X.shape[1]},数据量:{X.shape[0]}")
# 切割训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
print(f" ✓ 训练集 {X_train.shape[0]} 条,验证集 {X_val.shape[0]} 条")
# ================================================
# 第三步: 定义搜索空间
# ================================================
print("\n" + "=" * 60)
print("【参数搜索空间】每个模型要试哪些参数?")
print("=" * 60)
# ------ 3.1 随机森林参数 -------
# 随机森林不太吃参数,调的空间小
# 核心参数:树的数量,树的深度,最少分裂样本数
rf_param_grid = {
'n_estimators': [100, 200, 300, 500], # 树的数量:100颗可能不够
'max_depth': [10, 15, 20, 25, None], # 树的深度:None=不限
'min_samples_split': [2, 5, 10], # 分裂一次最少要几个样本
'min_samples_leaf': [1, 2, 3], # 叶子节点最少要几个样本
'max_features': ['sqrt', 'log2', 0.8] # 每次分裂看多少特征
}
# ------- 3.2 XGBoost 参数 ------
# XGBoost吃参数,调的空间大,是本步骤的重点
xgb_param_grid = {
'n_estimators': [100, 200, 300, 500], # 树的数量
'max_depth': [3, 5, 7, 9], # 树的深度,3-9比较合理
'leaning_rate': [0.01, 0.05, 0.1, 0.2], # 学习率:步子大小
'subsample':[0.6, 0.7, 0.8, 0.9, 1.0], # 行采样比例
'colsample_bytree':[0.6, 0.7, 0.8, 0.9, 1.0], # 列采样比例
'min_child_weight':[1, 3, 5], # 类似 min_samples_leaf
'reg_alpha': [0, 0.01, 0.1], # L1正则化(防过拟合)
'reg_lambda': [1, 1.5, 2] # L2正则化(防过拟合)
}
# -------3.3 LightGBM 参数 -------
# LightGBM 跟 XGBoost 类似,但有些专属参数
lgb_param_grid = {
'n_estimators': [100, 200, 300, 500],
'max_depth': [3, 5, 7, 9, -1], # -1=不限
'learning_rate': [0.01, 0.05, 0.1, 0.2],
'subsample': [0.6, 0.7, 0.8, 0.9, 1.0],
'colsample_bytree': [0.6, 0.7, 0.8, 0.9, 1.0],
'min_child_samples': [5, 10, 20], # LightGBM版 min_samples_leaf
'reg_alpha': [0, 0.01, 0.1],
'reg_lambda': [0, 0.01, 0.1],
'num_leaves': [15, 31, 63], # LightGBM专属:叶子数量
}
# 打印搜索空间大小
for name, grid in [('随机森林', rf_param_grid), ('XGBoost', xgb_param_grid), ('LightGBM', lgb_param_grid)]:
total = 1
for v in grid.values():
total *= len(v)
print(f" {name}:{len(grid)} 个参数,全组合 {total} 种")
# ===========================================
# 第四步: 随机搜索调参
# ===========================================
print("\n" + "=" * 60)
print("【随机搜索】开始调参!每个模型试 30 组参数")
print("=" * 60)
# 存储结果
tuned_results = {} # 调参后的MAE
best_params = {} # 最佳参数
best_models = {} # 最佳模型(后面 Step 7 融合要用)
# ------- 4.1 随机森林调参 -----------
print("\n" + "-" * 60)
print(">>> 调参 1/3:随机森林")
print(" 预期:提升有限,因为它本身不太吃参数")
print("-" * 60)
start_time = time.time()
# RandomizedSearchCV 就是“随机搜索+交叉验证”二合一
# 参数解释:
# estimator -> 要调的模型
# param_distributions -> 参数搜索空间
# n_iter=30 -> 随机试 30 组
# cv= 5 -> 5折交叉验证
# scoring -> 用什么标准评判(MAE越小越好,所以用 neg_mean_absolute_error)
# random_state=42 -> 固定随机种子
# n_jobs=-1 -> 全部用CPU核心加速
rf_search = RandomizedSearchCV(
estimator=RandomForestRegressor(random_state=42, n_jobs=1),
param_distributions=rf_param_grid,
n_iter=30,
cv=5,
scoring='neg_mean_absolute_error',
random_state=42,
n_jobs=-1,
verbose=0
)
print(" 正在搜索最佳参数(30组 × 5折 = 150次训练)...")
rf_search.fit(X_train, y_train)
# 搜索完之后,rf_search.best_estimator_ 就是最佳参数组合的模型
# rf_search.best_params_ 就是找到的最佳参数
rf_best = rf_search.best_estimator_
rf_best_mae = mean_absolute_error(y_val, rf_best.predict(X_val))
tuned_results["随机森林"] = rf_best_mae
best_params["随机森林"] = rf_search.best_params_
best_models["随机森林"] = rf_best
elapsed = time.time() - start_time
print(f" ✓ 调参完成!耗时 {elapsed:.1f} 秒")
print(f" ✓ 最佳参数:{rf_search.best_params_}")
print(f" ✓ 调参后 MAE = {rf_best_mae:.2f}")
# ----- 4.2 XGBoost 调参 -----
print("\n" + "-" * 60)
print(">>> 调参 2/3:XGBoost")
print(" 预期:大幅提升!它吃参数,调好了能从 665 降到 600 左右")
print("-" * 60)
start_time = time.time()
xgb_search = RandomizedSearchCV(
estimator=XGBRegressor(random_state=42, n_jobs=1),
param_distributions=xgb_param_grid,
n_iter=30,
cv=5,
scoring='neg_mean_absolute_error',
random_state=42,
n_jobs=-1,
verbose=0
)
print(" 正在搜索最佳参数(30组 × 5折 = 150次训练)...")
xgb_search.fit(X_train, y_train)
xgb_best = xgb_search.best_estimator_
xgb_best_mae = mean_absolute_error(y_val, xgb_best.predict(X_val))
tuned_results['XGBoost'] = xgb_best_mae
best_params['XGBoost'] = xgb_search.best_params_
best_models['XGBoost'] = xgb_best
elapsed = time.time() - start_time
print(f" ✓ 调参完成!耗时 {elapsed:.1f} 秒")
print(f" ✓ 最佳参数:{xgb_search.best_params_}")
print(f" ✓ 调参后 MAE = {xgb_best_mae:.2f}")
# ---- 4.3 LightGBM 调参 ----
print("\n" + "-" * 60)
print(">>> 调参 3/3:LightGBM")
print(" 预期:也应该有显著提升")
print("-" * 60)
start_time = time.time()
lgb_search = RandomizedSearchCV(
estimator=LGBMRegressor(random_state=42, n_jobs=1, verbose=-1),
param_distributions=lgb_param_grid,
n_iter=30,
cv=5,
scoring='neg_mean_absolute_error',
random_state=42,
n_jobs=-1,
verbose=0
)
print(" 正在搜索最佳参数(30组 × 5折 = 150次训练)...")
lgb_search.fit(X_train, y_train)
lgb_best = lgb_search.best_estimator_
lgb_best_mae = mean_absolute_error(y_val, lgb_best.predict(X_val))
tuned_results['LightGBM'] = lgb_best_mae
best_params['LightGBM'] = lgb_search.best_params_
best_models['LightGBM'] = lgb_best
elapsed = time.time() - start_time
print(f" ✓ 调参完成!耗时 {elapsed:.1f} 秒")
print(f" ✓ 最佳参数:{lgb_search.best_params_}")
print(f" ✓ 调参后 MAE = {lgb_best_mae:.2f}")
# ============================================================
# 第五步:调参前后对比
# ============================================================
print("\n" + "=" * 60)
print("【成绩对比】调参前 vs 调参后")
print("=" * 60)
# Step4 的基准成绩(默认参数)
baseline = {
'随机森林': 620.93,
'XGBoost': 663.23,
'LightGBM': 693.98,
}
# Step5 的交叉验证成绩
cv_baseline = {
'随机森林': 618.30,
'XGBoost': 664.74,
'LightGBM': 692.01,
}
print("\n 模型 Step4基准 Step5-CV Step6调参后 提升")
print(" " + "-" * 60)
sorted_tuned = sorted(tuned_results.items(), key = lambda x:x[1])
for name, tuned_mae in sorted_tuned:
base = baseline[name]
cv = cv_baseline[name]
diff = base - tuned_mae
arrow = "↑" if diff > 0 else "↓"
print(f" {name:<12} {base:>8.2f} {cv:>8.2f} {tuned_mae:>10.2f} {arrow}{abs(diff):.2f}")
winner = sorted_tuned[0][0]
winner_mae = sorted_tuned[0][1]
print(f"\n 🏆 调参后获胜者:{winner}!MAE = {winner_mae:.2f}")
# ============================================================
# 第六步:最佳参数详情
# ============================================================
print("\n" + "=" * 60)
print("【最佳参数】每个模型调出了什么参数?")
print("=" * 60)
for name in ['随机森林', 'XGBoost', 'LightGBM']:
params = best_params[name]
print(f"\n {name} 的最佳参数:")
for key, value in sorted(params.items()):
print(f" {key:<22} = {value}")
# ============================================================
# 第七步:调参后特征重要性对比
# ============================================================
print("\n" + "=" * 60)
print("【特征重要性】调参后获胜模型觉得哪些特征最重要?")
print("=" * 60)
# 拿到调参后获胜模型的特征重要性
if winner == '随机森林':
importances = best_models['随机森林'].feature_importances_
elif winner == 'XGBoost':
importances = best_models['XGBoost'].feature_importances_
else:
importances = best_models['LightGBM'].feature_importances_
feature_importance = pd.DataFrame({
'特征名称': X.columns,
'重要性': importances
}).sort_values('重要性', ascending=False)
print(f"\n {winner}(调参后)最重要的 Top10 特征:")
print(" 排名 特征名称 重要性")
print(" " + "-" * 55)
for i, row in enumerate(feature_importance.head(10).itertuples(), 1):
print(f" {i:2d} {row.特征名称:<30} {row.重要性:.4f}")
# ============================================================
# 第八步:保存最佳模型参数(给 Step7 融合用)
# ============================================================
print("\n" + "=" * 60)
print("【保存结果】为 Step7 模型融合做准备")
print("=" * 60)
# 把最佳参数保存到文件,Step7 直接读取,不用重新调参
import json
save_path = "./step6_best_params.json"
def convert_types(obj):
"""把 numpy 类型转成 Python 原生类型"""
if isinstance(obj, (np.integer,)):
return int(obj)
elif isinstance(obj, (np.floating,)):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
elif isinstance(obj, dict):
return {k: convert_types(v) for k, v in obj.items()}
return obj
params_to_save = {
'随机森林': convert_types(best_params['随机森林']),
'XGBoost': convert_types(best_params['XGBoost']),
'LightGBM': convert_types(best_params['LightGBM']),
'调参后MAE': {k: float(v) for k, v in tuned_results.items()},
}
with open(save_path, 'w', encoding='utf-8') as f:
json.dump(params_to_save, f, ensure_ascii=False, indent=2)
print(f" ✓ 最佳参数已保存到:{save_path}")
print(f" ✓ Step7 模型融合会直接读取这些参数,不用重新调参")
# ============================================================
# 总结
# ============================================================
print("\n" + "=" * 60)
print("Step6 超参调优完成!")
print("=" * 60)
print(f"""
调参前排名:随机森林(620) > XGBoost(663) > LightGBM(694)
调参后排名:{sorted_tuned[0][0]}({sorted_tuned[0][1]:.2f}) > {sorted_tuned[1][0]}({sorted_tuned[1][1]:.2f}) > {sorted_tuned[2][0]}({sorted_tuned[2][1]:.2f})
下一步 Step7:模型融合
- 把三个调好参数的模型组合起来,三个臭皮匠顶个诸葛亮
- 常见方法:简单平均、加权平均、Stacking
""")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
# 第一部分:导入工具
import pandas as pd
import numpy as np
import time # 计时用的,看每个模型调参花了多久
import warnings
from sklearn.model_selection import train_test_split
from sklearn.model_selection import RandomizedSearchCV # 核心!随机搜索+交叉验证一体机
from sklearn.metrics import mean_absolute_error
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
2
3
4
5
6
7
8
9
10
11
12
唯一新面孔是 RandomizedSearchCV,其余都是老朋友了。这个类干两件事:
- 从参数空间里随机抽 n_iter 组参数
- 每组参数跑 cv 折交叉验证,打分
# 第二部分:读数据+切分
df = pd.read_csv(data_path, sep=" ")
y = df["price"]
drop_cols = ["price", "car_age_group"]
X = df.drop(columns=drop_cols)
X = X.select_dtypes(include=[np.number])
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
2
3
4
5
6
7
8
跟 Step4 一模一样的流程,不多说。关键点:切法必须跟 Step4 一样(同样的 random_state=42),这样调参后的成绩才能跟之前的基准直接对比。如果换了切法,成绩变了你不知道是参数的功劳还是数据的运气。
# 第三部分:参数搜索空间
这是重点,逐个说:
# 随机森林
rf_param_grid = {
'n_estimators': [100, 200, 300, 500],
'max_depth': [10, 15, 20, 25, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 3],
'max_features': ['sqrt', 'log2', 0.8],
}
2
3
4
5
6
7
- n_estimators:100-500,树少了学不透,多了浪费时间
- max_depth:10-25 + None(不限),随机森林本身不太容易过拟合,所以可以试深一点
- min_samples_split:分裂一次最少需要几个样本,越大越保守(防过拟合)
- min_samples_leaf:叶子节点最少几个样本,同理
- max_features:每次分裂随机看多少特征。
sqrt=看√n个,log2=看log₂n个,0.8=看80%
注意:随机森林没有 learning_rate,因为每棵树是独立长的,不像 XGBoost 那样逐步修正。
# XGBoost
xgb_param_grid = {
'n_estimators': [100, 200, 300, 500],
'max_depth': [3, 5, 7, 9],
'learning_rate': [0.01, 0.05, 0.1, 0.2],
'subsample': [0.6, 0.7, 0.8, 0.9, 1.0],
'colsample_bytree': [0.6, 0.7, 0.8, 0.9, 1.0],
'min_child_weight': [1, 3, 5],
'reg_alpha': [0, 0.01, 0.1],
'reg_lambda': [1, 1.5, 2],
}
2
3
4
5
6
7
8
9
10
- max_depth 设得比随机森林浅(3-9 vs 10-25),因为 XGBoost 是 Boosting,每棵树只需要学一部分,不需要长太深
- learning_rate:XGBoost 专属,随机森林没有这个
- subsample / colsample_bytree:行列采样,增加多样性
- min_child_weight:XGBoost 版的 min_samples_leaf,叫法不同,意思一样
- reg_alpha / reg_lambda:L1 和 L2 正则化。可以理解成"罚单"——模型太复杂就罚它,逼它学简单规律
# LightGBM
lgb_param_grid = {
'n_estimators': [100, 200, 300, 500],
'max_depth': [3, 5, 7, 9, -1],
'learning_rate': [0.01, 0.05, 0.1, 0.2],
'subsample': [0.6, 0.7, 0.8, 0.9, 1.0],
'colsample_bytree': [0.6, 0.7, 0.8, 0.9, 1.0],
'min_child_samples': [5, 10, 20],
'reg_alpha': [0, 0.01, 0.1],
'reg_lambda': [0, 0.01, 0.1],
'num_leaves': [15, 31, 63],
}
2
3
4
5
6
7
8
9
10
11
跟 XGBoost 几乎一样,多了两个特有参数:
- max_depth=-1:LightGBM 的写法表示不限深度
- num_leaves:LightGBM 用 leaf-wise 生长策略,不按层长,而是挑损失最大的叶子继续分裂。所以光限制深度不够,还得限制叶子总数。经验值
2^max_depth,所以 15/31/63 对应 depth≈4/5/6
# 第四部分:随机搜索调参(核心)
rf_search = RandomizedSearchCV(
estimator=RandomForestRegressor(random_state=42, n_jobs=1),
param_distributions=rf_param_grid,
n_iter=30, # 随机抽 30 组参数
cv=5, # 5 折交叉验证
scoring='neg_mean_absolute_error',
random_state=42,
n_jobs=-1,
verbose=0
)
rf_search.fit(X_train, y_train)
2
3
4
5
6
7
8
9
10
11
逐个参数说:
| 参数 | 含义 |
|---|---|
estimator | 要调参的模型,把基础参数写上(random_state、n_jobs) |
param_distributions | 刚才定义的搜索空间,RandomizedSearchCV 从这里随机抽 |
n_iter=30 | 抽 30 组。每组都要跑 5 折,所以总共 150 次训练 |
cv=5 | 5 折交叉验证。跟 Step5 一样的道理 |
scoring='neg_mean_absolute_error' | 评分标准。sklearn 的规矩:分数越大越好,所以 MAE 前面加个负号。MAE=600 → score=-600,MAE=500 → score=-500,-500 > -600,所以 score 越大 MAE 越小 |
n_jobs=-1 | 并行加速,用所有 CPU 核心 |
verbose=0 | 不输出训练过程日志 |
跑完之后三个关键属性:
rf_search.best_params_→ 找到的最佳参数组合rf_search.best_estimator_→ 用最佳参数训练好的模型rf_search.best_score_→ 交叉验证的最佳分数(注意是负的 MAE)
然后用验证集算真正的 MAE:
rf_best_mae = mean_absolute_error(y_val, rf_best.predict(X_val))
这里有个细节:交叉验证的分数和验证集的分数不一样。交叉验证是在训练集内部切的,验证集是跟 Step4 一样留出来的 20%。我们最终看验证集分数,因为这样才能跟之前的基准对比。
# 第五~七部分:对比和展示
就是打印成绩、展示最佳参数、特征重要性,没什么新逻辑。
# 第八部分:保存参数
params_to_save = {
'随机森林': convert_types(best_params['随机森林']),
'XGBoost': convert_types(best_params['XGBoost']),
'LightGBM': convert_types(best_params['LightGBM']),
'调参后MAE': {k: float(v) for k, v in tuned_results.items()},
}
with open(save_path, 'w', encoding='utf-8') as f:
json.dump(params_to_save, f, ensure_ascii=False, indent=2)
2
3
4
5
6
7
8
convert_types 这个函数是因为 numpy 的整数/浮点数类型 json 不认识,得转成 Python 原生的 int/float 才能存。
# 第七步:模型融合
现在手里三个模型,调完参的最好成绩:
| 模型 | MAE |
|---|---|
| XGBoost | 569.34 |
| LightGBM | 570.33 |
| 随机森林 | 606.68 |
融合的核心问题就一个:怎么把三个模型的预测结果合在一起,比单个最好的还准?
# 三种融合方式,由简到难
1. 简单平均(Baseline)
三个模型的预测值直接取平均:
final = (pred_xgb + pred_lgb + pred_rf) / 3
优点:简单到不用动脑子 缺点:随机森林607明显拉胯,它和569同等权重,等于拖后腿
2. 加权平均(推荐先试这个)
按验证集表现分配权重,谁准谁说话算数:
final = w1 * pred_xgb + w2 * pred_lgb + w3 * pred_rf
权重的确定方法:
- 手动设:XGBoost和LightGBM各给0.4,随机森林给0.2(凭感觉,不严谨)
- 按MAE反比算:MAE越低权重越高,比如
w = 1/MAE,再归一化 - 搜索最优权重:在验证集上用scipy的
minimize搜一组合最优权重(最靠谱)
这三种都可以试,代码量都不大。
3. Stacking(进阶,比赛常客)
思路:三个模型先各自预测,把预测结果当新特征,喂给一个"裁判模型"学怎么组合。
第一层:XGBoost → pred1
LightGBM → pred2
随机森林 → pred3
第二层:把pred1、pred2、pred3当3个特征 → 喂给裁判(一般用岭回归或Lasso)
2
3
4
5
裁判模型为什么用简单的?因为第一层已经够强了,第二层只是学"怎么混",太复杂容易过拟合。
# 关键坑:数据泄漏
这是融合里最容易犯的致命错误:
- ❌ 用训练集训练模型,再用训练集的预测值训练裁判 → 裁判看到的都是"做过的题",分数虚高
- ✅ 用K折交叉的方式生成训练集的预测值(out-of-fold prediction):每折用其他折训练,预测当前折,这样每条数据的预测值都是"没见过的"才干净
简单加权平均不存在这个问题,因为不需要训练第二层。Stacking必须处理。
# 建议执行顺序
- 先试加权平均(5分钟能出结果),看能不能从569往下压
- 再试Stacking(代码稍复杂),看能不能再压一点
- 两种方式的结果对比,取更好的提交