
Fine-tuning微调艺术
# 大模型应用开发
提示工程VS RAG VS微调,什么时候使用?
# 高效微调方法
# 模型微调
做AI应用需要的微调和基座模型公司做的微调,一般都是什么区别?
基座模型公司(OpenAI、Google、Meta、阿里、DeepSeek、月之暗面)
- 目标:通用语言能力→规模大(100B+)、数据通用(万亿token)、成本高(千卡月级)。
- 技术:继续预训练(continue pre-training)+指令微调(instruction tuning)+ RLHF/PPO/DPO。
- 使用方式:公开权重或API。
应用开发者(企业IT部门、创业公司、个人开发者)
- 目标:垂直领域、私域知识(医疗、法律、客服…)。
- 规模:6B–70B,LoRA/QLoRA为主,数小时~数天即可。
- 数据:1k–1M条高质量指令-回答对,业务本身产生。
- 交付形式:增量LoRA权重(几十MB),可热插拔。
我们可以用一个生动的比喻来解释:
- 基座模型公司(如OpenAI、阿里)的微调,就像是“九年义务教育 + 岗前培训”。
- 应用开发者(如企业、个人)的微调,就像是“专业技能进修班”。
基座模型公司:打造“通才”毕业生
基座模型公司(如OpenAI、Google、阿里等)的目标是创造一个什么都能聊、什么都懂一点的“通才”。他们的工作分两步:
- 预训练(九年义务教育):让模型阅读海量的书籍、网页、文章(万亿级别的文本),学习语言规律和世界常识。这时的模型就像一个知识渊博但只会“文本接龙”的“野生学霸”,你问它“北京的首都是哪里?”,它可能会接着续写“上海的首都是哪里?”。
- 指令微调与对齐(岗前培训):这是您提到的关键一步。公司会用大量精心编写的“问题-标准答案”对来训练模型,教它如何听懂人类的指令,并以礼貌、安全、符合人类价值观的方式进行对话。经过这一步,模型才从一个只会“接龙”的学霸,变成了一个能正常交流、能回答问题的“通用助理”(比如我们日常用的ChatGPT、通义千问)。
简单来说,基座模型公司的微调,是为了让模型“学会说话、学会做人”,成为一个合格的、通用的产品。
应用开发者:培养“专才”员工
应用开发者拿到这个“通才”毕业生后,发现它虽然博学,但在处理专业工作时就不够用了。比如,让它当法律顾问,它不懂最新的法条;让它当公司客服,它不懂内部的产品信息和话术。
这时,应用开发者就需要进行第二次微调:
目标:不是教它说话,而是教它“行话”和“规矩”。
数据:使用自己私有的、垂直领域的少量高质量数据,比如公司的产品手册、客服对话记录、医疗病例、法律判例等。
方法:通常采用LoRA、QLoRA等高效方法。这就像是给这个“通才”员工发一本“岗位技能手册”,让他快速掌握特定工作的流程和风格,而不需要重新学习所有基础知识。这个过程成本低、速度快。
简单来说,应用开发者的微调,是为了让“通才”变成“专才”,成为一个能解决特定业务问题的“行业专家”。
总而言之,基座模型公司的微调是“从0到1”,创造了一个通用的AI大脑;而应用开发者的微调是“从1到N”,在这个大脑的基础上,为它加载了特定的“技能插件”,使其能够胜任具体的工作。
# 高效微调的方法
| 方法 | 可训练参数比例 | 核心思想 | 常用场景 |
|---|---|---|---|
| Prompt Tuning | 极低(<0.01%) | 【软提示】冻结整个预训练模型,只在输入层添加一串可训练的“软提示”向量(即不是人能读的自然语言词),让模型自适应地理解任务。 | 模型规模非常大(>10B)时效果才好,资源极度受限的场景。 |
| P-Tuning v1/v2 | 极低(<0.1%~1%) | 【可深度的软提示】是Prompt Tuning的升级版。将可训练的“软提示”向量插入到每一层的输入中,而不仅仅是输入层,使提示更深入、效果更强。 | 自然语言理解(NLU)任务,如分类、阅读理解。在中小模型(~10B)上效果也比Prompt Tuning好。 |
| Prefix Tuning | 低(~0.1%~3%) | 【隐式前缀】与P-Tuning类似,也是在每一层头部添加可训练向量。但它将这些向量视为虚拟的“前缀token”,通过一个更复杂的网络(MLP)生成,之后被冻结。 | 自然语言生成(NLG)任务,如对话、摘要、翻译。 |
| LoRA | 低-中(~1%~10%) | 【低秩更新】冻结预训练模型权重。假设模型微调时的权重变化是低秩的,用两个小矩阵(降维再升维)的乘积来近似这个更新量。 | 几乎全能,是目前最流行、最通用的方法。尤其适合微调LLM和扩散模型(如Stable Diffusion)。 |
| QLoRA | 低-中(~1%~10%) | 【量化LoRA】LoRA的内存高效版。先将预训练模型量化为4bit以极大减少内存占用,然后再使用LoRA进行微调。保证了性能几乎无损。 | 资源受限的场景(如单张消费级显卡),想要微调极其巨大的模型(如65B)。 |
Prompt Tuning,P-Tuning,Prefix Tuning和系统提示词有什么区别
简单来说,系统提示词(System Prompt)是我们“口头上的指令”,而 Prompt Tuning、P-Tuning、Prefix Tuning 是模型“脑子里的神经连接”。
我们可以从以下三个维度来区分它们:
核心区别:看得见 vs 看不见
系统提示词(System Prompt):是“人话”,看得见。
它是你写在代码里或对话框顶部的文字,比如“你是一个专业的程序员助手”。
模型会像阅读普通文章一样阅读它,把它转化成向量。
本质:它是输入数据的一部分。
Prompt/Prefix Tuning:是“数学向量”,看不见。
它们不是“你好”、“请回答”这种文字,而是一串人类看不懂的、随机初始化的数字序列(比如 [0.12, -0.55, ...])。
这些数字直接作为模型的输入或内部状态,跳过了“文字转向量”的过程。
本质:它是模型参数的一部分(虽然很少)。变化方式:固定 vs 学习
系统提示词:是静态的。
写好之后,它就固定了。如果你觉得效果不好,你必须手动修改文字(比如把“程序员助手”改成“资深架构师”)。模型自己不会改你的提示词。
Prompt/Prefix Tuning:是动态可训练的。
刚开始它是一串随机数字。在训练过程中,通过梯度下降(AI的学习方式),这串数字会自动调整,直到模型发现“哦,当这串数字是XYZ时,我回答得最准确”。
你不需要知道这串数字代表什么意思,模型自己学会了最优的“暗号”。作用位置:表层 vs 深层
系统提示词:只在输入层起作用。
它就像书的序言,读完就进去了。虽然会影响后续内容,但它无法直接干预模型深层的复杂计算逻辑。
Prefix Tuning / P-Tuning v2:深入每一层。
它们不仅在开头出现,还会在模型计算的每一个环节(每一层Transformer)中“插嘴”,直接干预注意力的计算。这就像不仅给了书一个序言,还在每一页的页眉都写了批注,强行控制模型的思维路径。
| 维度 | 系统提示词 (System Prompt) | Prompt/Prefix Tuning (软提示) |
|---|---|---|
| 形式 | 自然语言 (如:“请用中文回答”) | 连续向量 (一串人类看不懂的小数) |
| 来源 | 人工编写 (工程师/产品经理写的) | 机器训练 (通过算法自动优化出来的) |
| 修改 | 需要人去改文字 | 需要GPU去跑梯度更新参数 |
| 位置 | 仅在输入端 (Embedding层) | 可在输入端,也可在模型深层 (Attention层) |
| 成本 | 零成本 (推理时直接输入) | 训练成本 (需要算力去训练这些向量) |
| 比喻 | 给员工发任务书 | 给员工做脑部手术/植入芯片 |
LoRA和QLoRA的实际应用场景
案例一:电商与游戏美术(LoRA的主场)
场景:一家做“国潮”服装的初创公司,或者一个独立游戏开发者。
痛点:
电商:每次上新款衣服,请模特拍摄、修图,一套图要几千块,还要等好几天。
游戏:需要大量特定风格(如水墨风、赛博朋克风)的图标或立绘,外包太贵。
LoRA的应用:
训练:他们收集公司过去拍摄的50张模特照片,或者画师画的30张原画,使用LoRA训练一个“专属风格模型”。这个模型文件非常小,可能只有100MB左右。
使用:设计师在Stable Diffusion里加载这个LoRA插件。输入“穿着红色连衣裙的女孩”,AI生成的图片立刻就是他们公司那个模特的脸,或者是那种特定的水墨画风。
结果:
成本:从几千元/天变成几乎零成本(电费)。
效率:从3天变成30分钟。
为什么用LoRA? 因为图像生成对风格的一致性要求高,LoRA能完美锁定“人脸”或“画风”,且文件小,方便在团队间传输。案例二:个人开发者打造“随身法律专家”(QLoRA的主场)
场景:一个程序员想在自己只有单张显卡(如RTX 3090/4090)的电脑上,微调一个超级聪明的法律大模型。
痛点:
他想用强大的开源模型(如Llama-3-70B,有700亿参数),但这个模型太大了,普通显卡根本装不下(显存溢出)。
如果用全量微调,需要好几万块钱的A100服务器。
QLoRA的应用:
压缩(量化):先用QLoRA的4-bit量化技术,把这个700亿参数的模型“压缩”一下,显存占用减少75%。
微调:在压缩的基础上,挂上LoRA适配器,喂入《民法典》、律师咨询记录等数据。
结果:
奇迹:原本需要昂贵服务器集群才能跑的超大模型,现在可以在单张消费级显卡上进行训练。
效果:模型变成了懂中国法律的专家,能回答“离婚财产怎么分”这种专业问题。
为什么用QLoRA? 为了在硬件受限的情况下,强行跑起来超大参数的模型。
案例三:医院的“病历整理助手”(LoRA的多任务切换)
场景:一家智慧医疗公司,他们有一个通用的AI底座,既要能写病历,又要能回答患者咨询,还要能辅助诊断。
痛点:
如果训练三个不同的模型,存储和部署成本太高(每个模型几十GB)。
医生在不同场景下需要不同的能力。
LoRA的应用:
训练:
训练一个“病历LoRA”(专门把口语转成专业术语)。
训练一个“客服LoRA”(专门用温柔语气回答患者)。
部署:服务器上只存一个基础大模型(比如10GB)。
早上8点查房时,加载“病历LoRA”(仅几百MB)。
下午2点回复咨询时,热切换成“客服LoRA”。
结果:
灵活性:像给手机换SIM卡一样切换AI的技能,不需要重启服务器。
为什么用LoRA? 因为LoRA权重独立,支持“热插拔”,非常适合多任务场景。
案例四:K12教育的“自动作业批改机”(QLoRA的降本增效)
场景:一个教育科技公司,需要处理数百万份学生的数学和作文作业。
痛点:
通用大模型(如ChatGPT)不懂小学特定的教学大纲,经常判错,或者给出的评语太生硬。
人工批改太慢,且由于数据隐私问题,不能把学生作业传到公有云。
QLoRA的应用:
数据:收集过去5年优秀教师的批改记录(题目+学生答案+老师评语)。
训练:使用QLoRA技术在本地服务器上微调一个中等规模的模型(如7B或13B)。
结果:
准确率:模型学会了老师的“红笔逻辑”,不仅判对错,还能写出“这一步计算粗心了哦”这种针对性评语。
成本:利用QLoRA,一家小公司甚至不需要买昂贵的服务器,用几块普通显卡就能完成训练和私有化部署。总结:什么时候用谁?
LoRA:“我要给AI装个插件。”
适合:画特定风格的图、让AI学会特定格式、多任务快速切换。
硬件要求:中等(普通显卡即可)。
QLoRA:“我想开法拉利,但我只有自行车的车库(显存)。”
适合:想玩超大模型(如70B参数以上)、硬件显存非常吃紧、预算极低的个人开发者或小团队。
硬件要求:低(能把大模型压缩塞进小显存)。
# LoRA的数学原理
# Lora原理
LoRA微调的核心思想是什么?
假设模型微调过程中的权重更新(ΔW)具有“内在的低秩特性”
核心问题:微调一个巨大模型很费劲
像GPT、Stable Diffusion这样的大模型有数十亿参数。直接微调所有参数(全量微调)需要巨大的计算资源和存储空间,成本非常高。LoRA的聪明办法:不直接调原始权重 LoRA(Low-Rank Adaptation,低秩自适应)提出了一个巧妙的思路:
我们不改变模型原有的巨大权重矩阵W。
我们在其旁边增加一个小的“旁路”,通过训练这个旁路来间接影响原始权重。
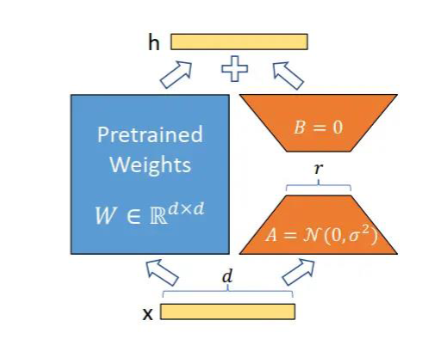
前向传播公式变为:h =Wx+BAx
W是原始预训练权重,冻结不动。
A和B是我们新引入的两个小的、低秩的矩阵。A负责降维,B负责升维。
BA合在一起就构成了对原始权重的更新ΔW。这个ΔW就是一个低秩矩阵。
微调时,我们只训练A和B这两个小矩阵,最后只需保存它们(文件很小),推理时再合并到W中即可。
这张图里的数学原理确实有点抽象,特别是那个“低秩”和矩阵乘法公式。
别被公式吓到了,其实 LoRA 的核心思想可以用“给大模型做微创手术”或者“给高速公路修匝道”来解释。
我们抛开复杂的数学符号,用大白话来拆解一下:
核心痛点:大模型太“笨重”
想象一下,基座模型(比如 GPT-3 或 Stable Diffusion)是一个巨大的、精密的机械钟表,里面有几十亿个齿轮(参数)在精密咬合。
全量微调(笨办法):你想让它学会“写法律合同”,于是你把整个钟表拆开,把几十亿个齿轮全部重新打磨一遍。
后果:累死人(算力贵),而且容易把原本“会报时”的功能给磨坏了(灾难性遗忘)。LoRA 的聪明办法:只修“旁路”
LoRA 说:“别动那个大钟表了!它已经很好了。我们在它旁边并联一个小装置就行了。”
这就引出了公式里的三个角色:
W (大矩阵):就是那个原封不动的巨型钟表。LoRA 把它冻结了,训练时完全不动它。
A 和 B (小矩阵):这是 LoRA 新加的两个小齿轮组。
A (降维):把复杂的信息压缩,提取核心特征(比如把“法律合同”压缩成几个关键代码)。
B (升维):把这几个关键代码还原成模型能听懂的指令,加回到主路上。公式大白话翻译:
ℎ=𝑊𝑥+𝐵𝐴𝑥 这个公式的意思是:最终结果 = 原模型的本事 + 新学的小本事
Wx :原模型看到问题 ,给出了它原本的回答。 BAx :LoRA 小装置看到问题x ,先压缩( A )再还原( 𝐵 ),算出一个“修正值”( ΔW )。
- :把“修正值”加到原回答上。
举个栗子:
原模型( W ):看到“苹果”,回答“好吃的水果”。
LoRA( BA ):看到“苹果”,算出修正值“是科技公司”。
最终结果( h ):好吃的水果 + 科技公司 = 苹果公司。
- 什么是低秩特性
想象一个巨大的Excel表格(比如1000行*1000列),里面填满了数字,这个表格就是一个矩阵。
高秩矩阵:这个表格里的数据五花八门,每一行,每一列的信息都独一无二,没有明显规律。你想简化它?没门!你必须原封不动的保存这100万个数字才能完整描述他
低秩矩阵:表格里的数据高度相关,存在明显的套路。
例如:可能所有航都是第一行的倍数。
你只需要保存很少的几行或几列基础数据,就能通过组合完美的重建出整个巨大的表格。
思考:比如一份全球气温报告,你不需要保存每个城市的每分钟数据。你只需要知道维度季节等几个核心因素,就能很好的推测出任意地方的气温
- 什么是“低秩”?(为什么能省这么多?)
这是最关键的数学原理,也是 LoRA 能省 10,000 倍显存的原因。
全量微调:假设你要调整 10,000 个参数,你就得训练 10,000 个数字。
LoRA(低秩分解):
LoRA 认为,模型微调其实不需要动那么多参数,只需要动几个核心维度。它把那个巨大的10000 参数矩阵,拆解成两个极小的矩阵: 一个 10000×4 的矩阵 A ,和一个 4×10000的矩阵 B 。(这里的 4就是“秩”,通常设得很小,比如 8、16、64)。
数学魔法:虽然 𝐴和 𝐵 乘起来能变回大矩阵,但训练时我们只需要训练 A 和 B 里的那几百个参数,而不是原来的几亿个。
什么是“内在的低秩特性”?
ΔW是什么:
想象你有一个已经训练好的超大语言模型(比如 ChatGPT),它内部有成千上万甚至上百亿个参数。这些参数可以看作是一个巨大的“知识库”,决定了模型如何理解语言、回答问题等。
现在你想让这个模型学会一个新任务,比如写法律文书。你不需要从头训练它,而是对它的权重做微小调整——就像给一个聪明人稍微提点一下,他就能掌握新技能。
这个“微小调整”的量,就叫做 ΔW(Delta W):
ΔW = 新权重 - 原始权重
它本身也是一个和原始权重矩阵 W 同样大小的矩阵。比如 W 是 1000×1000,那 ΔW 也是 1000×1000,看起来有 100 万个数字要调。
但神奇的是——其实你根本不需要动这 100 万个数!为什么说它“内在”是低秩的?
通俗比喻:
想象你要画一幅复杂的油画,但你发现:其实只需要几种主色调,其他颜色都是这几种的混合。也就是说,整幅画的信息“本质上”是由少数几个基础颜色决定的。
类似地,ΔW 虽然是一个巨大的矩阵,但它的“有效信息”其实只集中在少数几个方向上。其余部分几乎为零,或者可以忽略不计。
这就是“低秩”的意思。
秩
“秩”(rank) 是线性代数里的概念,表示一个矩阵中有多少个“独立的信息方向”。
如果一个 1000×1000 的矩阵,秩是 1000 → 它很“满”,信息复杂;
如果秩只有 2 → 它其实可以由两个向量组合出来,非常“简单”。
数学原理:SVD 分解
为了验证这一点,研究者对真实微调得到的 ΔW 做了 奇异值分解(Singular Value Decomposition, SVD)。
SVD 是什么?
任何矩阵 A 都可以分解成:
𝐴=𝑈Σ𝑉𝑇
U 和 V 是正交矩阵(代表方向),
Σ 是对角矩阵,对角线上的数叫奇异值(singular values),从大到小排列。
奇异值的大小,代表了对应方向上的“重要程度”。
实验发现:
对真实的 ΔW 做 SVD 后,前几个奇异值很大,后面的迅速衰减到接近零。
比如:
第1个奇异值:100
第2个:30
第3个:5
第4个及以后:< 0.1
这意味着:ΔW 几乎完全由前2~3个方向决定!
换句话说,我们可以用一个低秩矩阵来近似 ΔW:
Δ𝑊≈𝐴𝐵𝑇
其中 A 是 1000×r,B 是 1000×r,而 r 很小(比如 r=8 或 16)。 这样,原本需要 100 万个参数,现在只需要 2×1000×r = 1.6 万个(当 r=8),压缩了 60 倍以上!
- LoRA 就是利用这个特性!
LoRA(Low-Rank Adaptation)算法的核心思想就是:
既然 ΔW 天然就是低秩的,那我们干脆直接假设它低秩,只训练两个小矩阵 A 和 B,而不是整个 ΔW。
具体做法:
冻结原始大模型的所有权重 W(不动它,省显存、省计算);
在某些层插入可训练的低秩矩阵:ΔW = A × B;
只训练 A 和 B(参数极少);
最终效果 ≈ 全参数微调,但成本极低。
# 矩阵分解与猜你喜欢
# 什么是矩阵分解
我们假设一个场景:为海量的用户和商品进行推荐:
•为用户找到其感兴趣的item推荐给他
•用矩阵表示收集到的用户行为数据,12个用户,9部电影
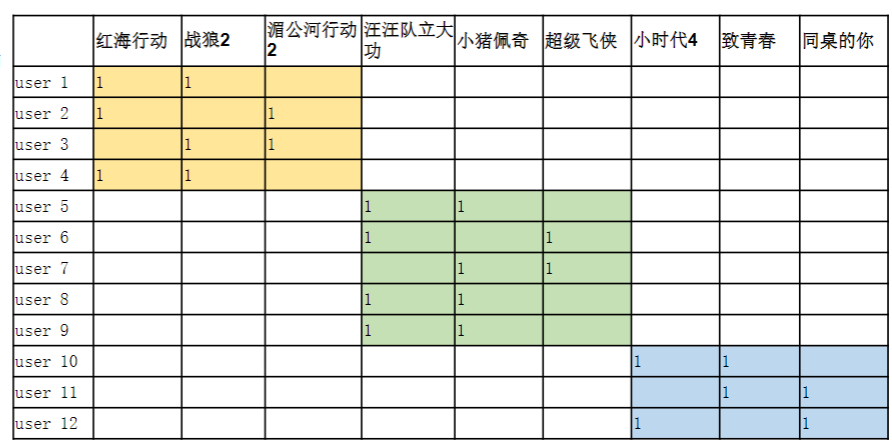
矩阵分解要做的是预测出矩阵中缺失的评分,使得预测评分能反映用户的喜欢程度
可以把预测评分最高的前K个电影推荐给用户了。
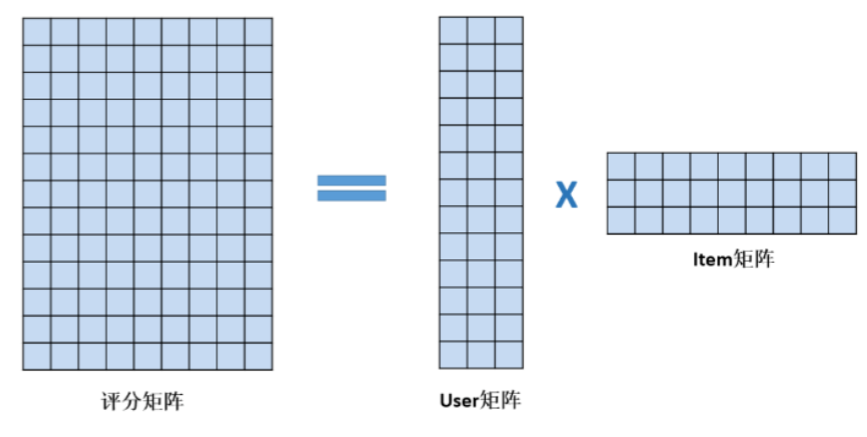
如何从评分矩阵中分解出User矩阵和Item矩阵
只有左侧的评分矩阵R是已知的
User矩阵和Item矩阵是未知
学习出User矩阵和Item矩阵,使得User矩阵*Item矩阵与评分矩阵中已知的评分差异最小=>最优化问题
观察User矩阵:用户的听歌爱好体现在User向量上
观察Item矩阵,电影的风格也会体现在Item向量上
MF用user向量和item向量的内积去拟合评分矩阵中该user对该item的评分,内积的大小反映了user对item的喜欢程度。内积大匹配度高,内积小匹配度低。
隐含特征个数k,k越大,隐类别分得越细,计算量越大。
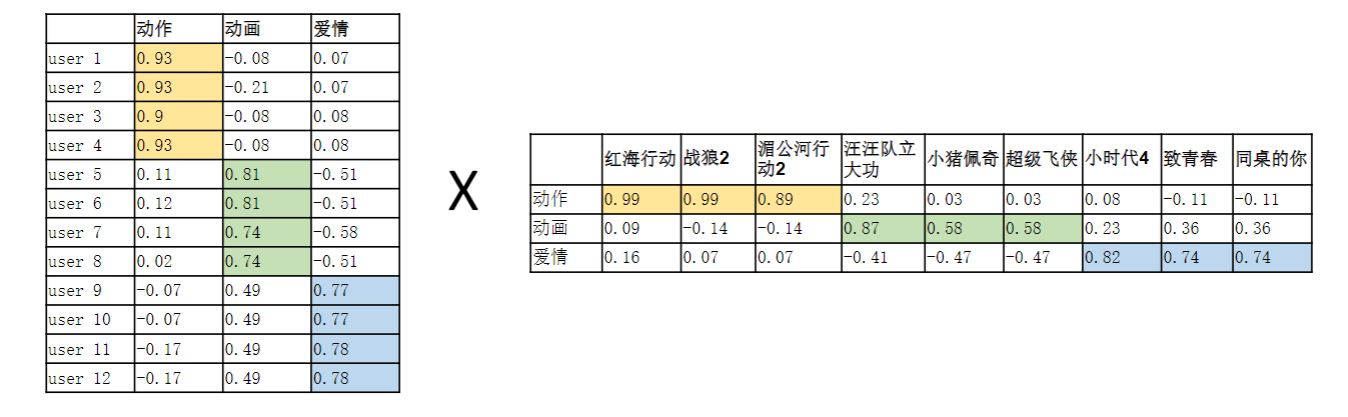
某个用户u对电影i的预测评分=User向量和Item向量的内积
把这两个矩阵相乘,就能得到每个用户对每部电影的预测评分了,评分值越大,表示用户喜欢该电影的可能性越大,该电影就越值得推荐给用户。
举个生活例子
想象你开了一家奶茶店,想推荐新品给老顾客:
你发现顾客其实只关心三个隐藏因素:甜度、茶味浓淡、有没有小料。
你不需要问他们“你喜欢什么”,而是通过他们过去点的单(比如“点了3次全糖波霸”),反推出每个人的偏好向量。
同时,你也给每款新品打上这三个维度的标签。
推荐时,就找“顾客向量”和“新品向量”最匹配的。
这就是矩阵分解的精髓!
# 矩阵分解的目标函数


你看到的这个公式,是推荐系统(比如“猜你喜欢”)中一个非常核心的优化目标。
它的作用是:让机器学会预测用户对商品的评分,从而推荐他们可能喜欢的东西。
别被吓到!我们把它拆成两部分来看:
第一部分:让预测更准
第二部分:防止模型太复杂(过拟合)
- 第一部分:让预测更接近真实评分
想象场景:
你有10个朋友,他们看过一些电影,并打了分。你想知道他们没看过的电影会不会喜欢。
𝑟𝑢𝑖 :用户 u 对物品 i 的实际评分(比如小明给《肖申克》打了5分)
𝑥𝑢 :用户 u 的“兴趣向量”(比如他爱剧情片、讨厌喜剧)
𝑦𝑖 :物品 i 的“特征向量”(比如《肖申克》是剧情+压抑+励志)
𝑥𝑢T :这两个向量的内积 → 表示“用户u对物品i的预测喜欢程度”
所以:
(𝑟𝑢𝑖−𝑥𝑢𝑇𝑦𝑖)2
就是:预测值和真实值之间的误差平方
我们要做的,就是让所有已知评分的误差加起来尽可能小!
这就像你在玩“猜数字”游戏,每次猜错了,你就调整策略,直到越来越接近正确答案。
- 第二部分:防止“作弊”——正则项(L2)
问题来了:
如果我不加限制,模型可能会变得特别“聪明”,只记住每一个用户的每一条评分,完全不思考规律 —— 这叫过拟合(死记硬背)。
比如它会说:“小明打过5分的电影,我全部给他打5分!”但这样就失去了泛化能力。
解决办法:加入惩罚项!
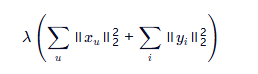
这叫做 L2 正则化,意思是:
不要让用户的兴趣向量或物品的特征向量太大!
向量越大,说明它越“极端”,容易过度拟合。
∥xu∥22 :用户向量的长度平方(比如 [3,4] 的长度是 5,平方是 25)
∥𝑦𝑖∥22 :物品向量的长度平方
λ :控制惩罚力度的参数(越大,越严格)
所以这一项的作用是:
“你可以学得好,但不能靠‘死记硬背’,要保持简洁、合理。”
目标函数最优化问题的工程解法:
- ALS,Alternating Least Squares,交替最小二乘法
- SGD,Stochastic Gradient Descent,随机梯度下降
# ALS求解方法
ALS,AlternativeLeastSquare, ALS,交替最小二乘法
- Step1,固定Y优化X
- Step2,固定X优化Y
- 重复Step1和2,直到X和Y收敛。每次固定一个矩阵,优化另一个矩阵,都是最小二乘问题


我们要为每个用户 𝑢找到一个兴趣向量 𝑥𝑢(比如 [喜欢剧情, 喜欢动作]),使得: 用 𝑥𝑢 和他看过的电影的特征 𝑦𝑖 做“匹配”,得到的分数 ≈ 他实际打的分
但问题是:
𝑥𝑢 和 𝑦𝑖 都是未知的!
所以 ALS 说:咱俩轮流来,你先定,我再调;我定好,你再调。
我们现在聚焦在:当所有电影的特征 𝑦𝑖 已经暂时固定时,怎么求出最优的 𝑥𝑢 ?
第一步:写出“误差”有多大 对用户 u 来说,他只给一部分电影打了分(比如电影 A、B、C)。
我们希望: 𝑥𝑢𝑇𝑦𝐴≈𝑟𝑢𝐴
𝑥𝑢𝑇𝑦𝐵≈𝑟𝑢𝐵 𝑥𝑢𝑇𝑦𝐶≈𝑟𝑢𝐶 如果差太多,就说明𝑥𝑢不准。
于是我们定义一个“总误差”(越小越好):
误差=(𝑟𝑢𝐴−𝑥𝑢𝑇𝑦𝐴)+(𝑟𝑢𝐵−𝑥𝑢𝑇𝑦𝐵)+(𝑟𝑢𝐶−𝑥𝑢𝑇𝑦𝐶)+𝜆∥𝑥𝑢∥2 最后一项𝜆∥𝑥𝑢∥2是防止𝑥𝑢变得太夸张(比如 [1000, -999]),叫正则化。第二步:把上面的东西写成“矩阵打包”形式(只是为了简洁)
把用户 𝑢 打过分的电影的特征向量拼成一个矩阵:
𝑌𝑢=[𝑦𝐴, 𝑦𝐵, 𝑦𝐶](假设隐因子维度是 k,那 𝑌𝑢是 k×3)
把他的评分拼成一个向量:
𝑅𝑢=[𝑟𝑢𝐴, 𝑟𝑢𝐵,𝑟𝑢𝐶]𝑇
那么,“预测分”就是:
𝑌𝑢𝑇𝑥𝑢
(结果是一个 3 维向量)
“误差”就变成:
∥𝑅𝑢−𝑌𝑢𝑇𝑥𝑢∥2+𝜆∥𝑥𝑢∥2 别被符号吓到!这还是那个“预测分 vs 真实分”的平方和,只是打包写了。第三步:怎么让误差最小?→ 解一个“最佳匹配”问题
我们现在要找一个 𝑥𝑢,让上面的误差最小。
这在数学上是一个经典的 “带正则的最小二乘问题”。
它的最优解有一个现成的公式(不用猜、不用试、不用梯度下降):
𝑥𝑢=(𝑌𝑢𝑌𝑢𝑇+𝜆𝐼)−1𝑌𝑢𝑅𝑢
现在,一句一句解释为什么是这个公式(结合求逆)
𝑌𝑢𝑅𝑢 :“用户用评分投票选出来的理想风格” 每部电影有风格( 𝑦𝑖 )
用户给高分 = 给这个风格投赞成票
𝑌𝑢𝑅𝑢就是:把每部电影的风格 × 它的票数(评分),然后加起来
结果是一个 k 维向量,代表:“在我眼里,完美的电影应该长这样”
这是我们的目标方向。𝑌𝑢𝑌𝑢𝑇 :“这些电影风格之间的‘重叠度’或‘信息相关性’”
如果用户看的电影都很像(比如都是爱情片),那它们的风格向量很接近;
这时候,直接加权平均会重复计算同一个特点;
𝑌𝑢𝑌𝑢𝑇就是在量化:这些电影提供的信息有多少是独立的?
它决定了我们如何正确解读用户的投票。+𝜆:“加点常识,别太疯”
如果用户只看了一部电影,模型可能会认为:“他只爱这一种!” → 𝑥𝑢会变得极端;
加上 𝜆𝐼(I 是单位矩阵),相当于说:“就算他只看一部,我也假设他可能喜欢别的风格,别把权重全压在一个方向上。”
这保证了矩阵一定可逆,而且结果更稳定、泛化更好。
这是防过拟合的安全阀。整体求逆 (⋯ )−1 :“反向解码:从理想风格倒推个人口味”
现在我们有: 一个“混合规则”矩阵: 𝑀=𝑌𝑢𝑌𝑢𝑇+𝜆𝐼
一个“理想结果”向量: 𝑏=𝑌𝑢𝑅𝑢
我们知道:如果用户的口味是 𝑥𝑢 ,经过混合规则 M 作用后,应该得到 b。
即: 𝑀⋅𝑥𝑢=𝑏
但我们知道 b,想知道 𝑥𝑢 —— 所以要“撤销 M 的影响”。
求逆 𝑀−1 就是那个“撤销操作”!
于是:
𝑥𝑢=𝑀−1𝑏=(𝑌𝑢𝑌𝑢𝑇+𝜆𝐼)−1𝑌𝑢
就像你知道“调料混合后的味道”,现在要用“配方还原器”(求逆)算出“每种调料该放多少”。
# SVD矩阵分解
# 奇异值分解SVD
我们可以得到为奇异值分解


如何理解SVD的作用
- 对于特征值矩阵,我们如果只包括某部分特征值,结果会怎样?
矩阵A:大小为1440*1080的图片 - Step1,将图片转换为矩阵
- Step2,对矩阵进行奇异值分解,得到p,s,q
- Step3,包括特征值矩阵中的K个最大特征值,其余特征值设置为0
- Step4,通过p,s',q得到新的矩阵A',对比A'与A的差别
你可以把它想象成一种“数据压缩”或者“去粗取精”的神器。
- 核心概念:一张图片的“骨架”
想象一下,你有一张非常高清的照片(这就是图片里的矩阵 A)。这张照片里有很多细节:树叶的纹理、天空的云彩、路人的表情。这些信息量非常大,如果直接存下来很占内存。
SVD(奇异值分解)做的事就是:
它把这张复杂的照片(矩阵 A),拆解成三个更简单的部分(矩阵 P、Λ、Q),用来描述这张照片的“核心骨架”。
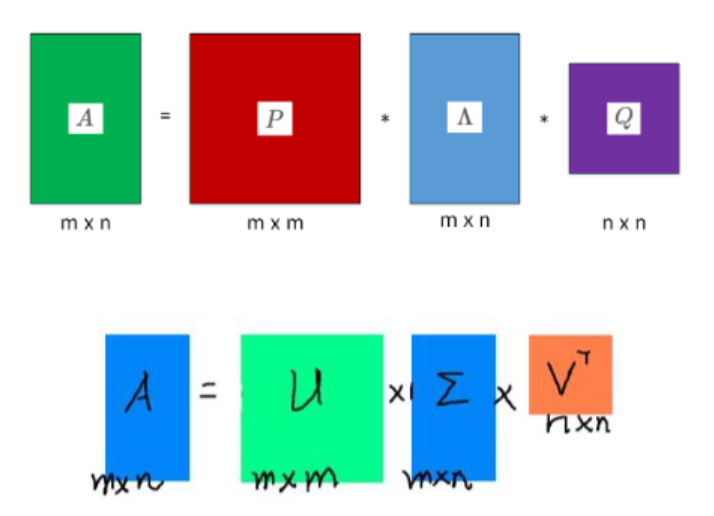
公式就是图片里写的:
𝐴=𝑃Λ𝑄T
我们来逐个拆解这三个角色(对应你第一张图片里的彩色方块):
矩阵 P(左奇异矩阵 - 红色方块)
通俗理解: 它是对“行”(比如图片里的像素行,或者推荐系统里的用户)特征的总结。
作用: 它告诉我们这张图里有哪些“基础模式”。矩阵 Λ(中间的对角矩阵 - 蓝色方块)
通俗理解: 这是最重要的部分,它是“重要性评分表”。
关键点: 这里面有一串数字(λ1, λ2...),叫奇异值。
λ1 最大,代表最重要的特征(比如图片里最大的一块颜色)。
λ2 次之,代表次要特征。
越往后,数字越小,代表的细节越不重要(比如噪点、微小的纹理)。矩阵 Q(右奇异矩阵 - 紫色方块)
通俗理解: 它是对“列”(比如图片的像素列,或者推荐系统里的商品)特征的总结。
作用: 它配合 P 矩阵,共同还原出图片的样子。SVD 到底有什么用?(结合你的第三张图)
想象一下这个场景:
你要传输一张 1440x1080 的高清大图(矩阵 A),数据量太大了,网速很慢怎么办?
SVD 的魔法操作(Step 3 & Step 4):
- 分解: 先把大图 A 拆成 P、Λ、Q 三个小矩阵。
- 筛选(关键!): 我们看中间那个“重要性评分表” Λ。
你会发现,可能前 K 个数字(比如前50个奇异值)就已经包含了这张图 99% 的轮廓信息。
剩下的几千个微小的奇异值,其实只是一些细枝末节的噪点。 - 丢弃: SVD 允许我们把那些微小的奇异值直接设为 0,或者干脆扔掉。
- 重建: 用剩下的这 K 个重要特征,重新拼凑回一张图(矩阵 A')。
结果:
原图 A:数据量巨大,非常清晰。
新图 A':数据量可能只有原来的 1/10,但肉眼看过去,它和原图几乎一模一样!
这就是 SVD 的强大之处:用极少的数据,近似还原最原本的信息。
在推荐系统里是怎么用的?(结合第一张图)
图片里还提到了“推荐系统”,这里的逻辑也是一样的:
矩阵 A:是一个巨大的表格,记录了所有用户对所有商品的打分。但这个表格通常是空的(很多人没买过很多商品)。
SVD 分解后:
P (User矩阵):把用户分类。比如发现你喜欢“科幻片”,他喜欢“爱情片”。
Q (Item矩阵):把商品分类。比如这部电影是“硬核科幻”,那本书是“浪漫爱情”。
Λ (重要性):告诉我们哪些分类是最主流的。
通过这种方式,SVD 就能算出:“虽然你没看过《星际穿越》,但既然你喜欢科幻(P矩阵特征),而这部电影是典型的科幻(Q矩阵特征),那我预测你会给它打 5 星!”于是就把这部电影推荐给你。
总结一下
别被公式吓到,SVD 其实就是:
拆解: 把复杂的大数据(图片、评分表)拆成三个部分。
排序: 找出哪些是核心骨架(大奇异值),哪些是无关紧要的噪音(小奇异值)。
压缩/预测: 扔掉噪音,保留精华。既能省空间(压缩图片),又能补全缺失的信息(推荐系统)。
# PEFT库
Peft库:
https://github.com/huggingface/peft (opens new window)
很方便地实现将普通的HF模型变成用于支持轻量级fine-tune的模型,目前支持4种策略:
LoRA:大模型的低秩适配器
Prefix Tuning: Optimizing Continuous Prompts for Generation
P-Tuning: GPT Understands, Too
Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
它是为了解决什么痛点? 想象一下,你要微调一个像 GPT 或 Llama 这样的大模型,它们通常有几百亿甚至几千亿个参数。
传统方法(全量微调): 就像你要给一架波音飞机重新喷漆,你得把整架飞机拆了,每个零件都重新涂一遍,然后再组装起来。这需要巨大的厂房(显存)、昂贵的油漆(算力)和很长的时间。
PEFT 的方法: 它觉得没必要拆整架飞机。它只是在飞机表面贴了一些“贴纸”(比如换个涂装、换个logo),就能让飞机看起来焕然一新。它只改动极小的一部分参数,就能让模型学会新技能。
核心优势: 省钱、省显存、省时间。它具体是怎么做的?(你提到的那 4 种策略)
你列出的那 4 种策略,其实就是给模型贴“贴纸”的 4 种不同贴法:
LoRA (低秩适配) —— 最火的“外挂”
原理: 它冻结了大模型原本的 99% 的参数(不让它们动),只在模型的某些层旁边加了一小个“旁路”。
比喻: 就像给汽车加了一个涡轮增压器,发动机本体没换,但动力变强了。
效果: 通常只需要训练 0.1% 到 1% 的参数,就能达到很好的效果。训练完的文件通常只有几 MB 到几十 MB,非常小巧。
Prefix Tuning —— “给模型戴个帽子”
原理: 它不改模型内部,只在输入给模型的数据最前面加一段特殊的“指令代码”。
比喻: 就像你每次跟 Siri 说话前,都先加一句“请用莎士比亚的风格回答我”。这段前缀就是“帽子”。
P-Tuning —— “优化提示词”
原理: 和 Prefix Tuning 类似,也是改提示词(Prompt),但它用神经网络自动去搜索最好的提示词是什么样的,而不是人工去写。
比喻: 就像你自动寻找最好的“咒语”,让模型能听懂你的指令。
Prompt Tuning —— “简单的提示微调”
原理: 这是最简单的一种,就是在输入文本的开头或结尾加一些可学习的向量。
比喻: 就像给文章加个标题,告诉模型“接下来我要问你关于数学的问题了”。
- 为什么大家都在用它?
根据 Hugging Face 官方文档和社区数据,PEFT 库主要有这三大好处:
显存杀手的救星:
如果你想微调一个 70亿参数的大模型,传统方法可能需要 80GB 显存的顶级显卡(比如 A100)。但用 PEFT(特别是 LoRA),你只需要 10GB-20GB 显存(比如 3090/4090)甚至更低就能跑起来。这让普通开发者也能玩转大模型。 存得下、传得快:
微调完一个大模型,传统方法生成的文件可能有 10GB+。但用 PEFT,你只保存那个“贴纸”(Adapter),通常只有 几兆(MB) 大小。比如,微调一个 30亿参数的模型,PEFT 保存的文件可能只有 19MB。 一个模型,多种用途:
你可以保留一个“底座”模型(比如 Qwen),然后训练很多个不同的 PEFT 小文件。比如一个用来写代码,一个用来写小说,一个用来做客服。你只需要在推理时切换不同的“小文件”即可,不用存几十个庞大的模型。
# 微调数据准备
因为可训练的参数少,模型更加依赖我们提供的数据来精准学习=>高质量的数据是微调成功的关键
高质量的数据:
一致性:提供的数据格式、指令风格和期望的输出需要统一。
比如:一条数据是“写一首诗”-> [诗歌],下一条是“Summarize this: ...”-> [摘要]
=>模型会感到困惑,不知道到底要学什么。最佳实践:所有数据都应遵循相同的模板。比如
<指令>{instruction}</指令>
<输入>{input}</输入>
<回复>{response}</回复>准确性: 数据中的答案需要保证正确性,模型会学习数据中的所有pattern
=>包括里面的错误,garbage in garbage out多样性:
在保证一致性的前提下,指令和输入要尽可能覆盖各种情况
=>提高模型的泛化能力
# 数据数量与模型尺寸、场景的关系
数据量没有绝对的标准,但它与模型大小和任务复杂度紧密相关。
| 模型规模(参数量) | 任务场景 | 建议数据量(指令-回复对) | 说明 |
|---|---|---|---|
| ~7B (70亿) | 简单任务(风格模仿、简单问答) | 1000-5000条 | 模型已有较强能力,LoRA微调主要是“引导”和“校准”。 |
| ~7B (70亿) | 复杂任务(推理、专业领域) | 5000-50000+条 | 复杂逻辑和知识需要更多样本来教会模型。 |
| ~13B~70B | 通用/复杂任务 | 1万–10万+条 | 模型容量更大,可以消化更多数据以学习更细微的模式。 |
| > 70B | 继续预训练 | 海量数据(GB级别文本) | 目标是让模型学习语言本身而非指令遵循,需要大语料 |
Step1:聚焦质量
花80%的时间在数据清洗、格式统一和答案校验上。1000条完美数据远胜于10万条杂乱数据。
Step2:评估数量
根据你的模型大小和任务难度,参考上述范围设定一个目标。从小规模开始(如1000条),进行实验,如果模型欠拟合(表现不好),再考虑增加数据。
任务越复杂,所需数据越多。
有一个“黄金起点”:对于许多任务,1000-6000条高质量指令数据已经可以产生很好的微调效果。
# 硬件需求与显存估算
Thinking:微调显存估算的逻辑是什么?
微调时的总显存占用主要来自四个方面,可以用公式来估算:
总显存≈(模型权重显存) + (优化器状态显存) + (梯度显存) + (前向传播激活值显存)
模型权重显存:这是最大的部分。模型通常以float16 (FP16)或bfloat16 (BF16)格式加载。
计算公式:模型参数量(B) * 2字节
比如:一个7B(70亿)参数的模型,其权重显存约为7 * 10^9 * 2字节≈14 GB。
优化器状态显存:优化器(如Adam)为每个可训练参数保存的状态。
对于AdamW,它会为每个参数保存动量(momentum)和方差(variance)两个状态,通常也是FP16格式。
LoRA计算:假设LoRA可训练参数量为L,则优化器状态显存约为L * 4字节*2(两个状态)。
梯度显存:训练时反向传播计算的梯度。通常也是FP16格式。
LoRA计算:约为L * 2字节(只存LoRA参数的梯度)。
前向传播激活值显存:计算过程中产生的中间变量(激活值),用于反向传播。这部分与批次大小(batchsize)和序列长度(sequence length)强相关,估算复杂
=>可以简单估算为模型权重显存的20%-50%。
如果微调一个7B(70亿)参数的模型需要多少显存?
LoRA的魔力在于,它通过大幅减少可训练参数量L,从而极大地削减了第2、3部分的显存占用,使得第1部分(模型权重)成了绝对主力。
假设:
•模型参数量:70B
•使用AdamW优化器
•LoRA训练参数L:设为1%,已经很充裕。
•批次大小(batch size):1
•序列长度(sequence length):512
显存估算:
•模型权重(FP16):7e9 * 2字节= ~14 GB
•优化器状态:L * 4字节*2 = 7e7 * 8字节≈0.56 GB
•梯度:L * 2字节= 7e7 * 2字节≈0.14 GB
•激活值(估算):14 GB * 0.3 ≈ 4.2 GB(按30%估算)
•总显存估算:14 + 0.56 + 0.14 + 4.2 ≈ 19 GB
对于7B模型
一张24GB的消费级显卡(如RTX 4090)可以流畅地微调,甚至可以使用稍大的batch size。对于13B模型: 仅模型权重就需要26GB
=>需要至少一张32GB的显卡(如RTX5090 32GB)或使用QLoRA技术。QLoRA是终极解决方案:
它将模型权重量化到4-bit,能将模型权重显存减少到约模型参数量*0.5字节。
=>微调7B模型仅需约6-8GB显存,让绝大多数显卡都能参与进来。
显存大头是模型本身,LoRA通过减少可训练参数来优化其余部分。
估算公式:总显存≈(模型参数量*2字节) * (1 +激活系数) + (L * 10字节)。激活系数通常取0.2~0.5。
硬件选择:
•7B/8B模型:推荐24GB显存(如3090/4090)。
•13B/14B模型:推荐32GB+显存(如V100/A100),或使用QLoRA。
•70B模型:必须使用QLoRA和多卡部署。
# 微调后的模型评估
我们投入了时间、数据和算力,如何证明微调后的模型变好了?
数据集划分——验证集与测试集
训练集:用于更新模型权重的数据=>喂给LoRA微调的数据。
验证集:用于在训练过程中监控模型表现,调整超参数(如学习率),以及进行模型选择(比如选择训练得最好的那个checkpoint)=>它不能用于最终的性能报告。
测试集:用于最终、一次性的性能评估。它模拟了模型在“真实世界”中遇到的、从未见过的新数据上的表现。在整个微调过程中,测试集必须被严格“封存”,不能以任何形式用于训练。
| 测试维度 | 测试内容 | 说明 |
|---|---|---|
| 1.任务主指标 | 【核心对比】使用任务相关的量化指标进行评估。•分类任务:准确率、F1分数、精确率、召回率 •生成任务:BLEU, ROUGE (摘要),ChrF(翻译) •问答任务:EM (精确匹配), F1 | 这是衡量微调是否成功的硬性标准。直接反映了模型在目标任务上能力的提升幅度。 |
| 2.通用能力保持 | 【关键检查】测试模型在微调任务之外的通用能力是否退化。•常识推理(如:“西瓜的籽是什么颜色的?”)•基础代码能力(如:写一个简单的排序函数)•通用对话(如:“介绍一下你自己”) | 防止模型出现“灾难性遗忘”。确保模型没有因为学习新任务而“变傻”,破坏了原有的宝贵能力。 |
| 3.泛化能力 | 测试模型在同一任务但不同表述或稍复杂场景下的表现。•使用与训练数据句式、词汇不同但意图相同的指令。•构造更复杂或包含干扰信息的输入。 | 检验模型是“死记硬背”了训练数据,还是真正“学会”了任务。泛化能力差的模型无法在实际应用中落地。 |
| 4.人工评估 | 【黄金标准】由人类对模型生成的结果进行主观评分。•流畅度:输出是否通顺、符合语法?•相关性:输出是否紧扣指令和输入?•有用性:输出是否真正解决了问题或满足了需求? | 很多生成任务(如对话、创意写作)的优劣难以用量化指标衡量。人工评估能发现自动化指标无法捕捉的细微问题,是最终的质量关口。 |
| 5.输出质量分析 | 【定性分析】直接对比和分析模型在具体案例上的输入-输出。•正面案例:找出微调后效果提升显著的例子,展示成果。•失败案例:分析微调后仍表现不佳或出现负向变化的例子。 | 帮助直观地理解模型行为的变化,发现潜在问题。为下一步迭代优化提供最直接的线索和方向。 |
- 准备阶段:提前从原始数据中划分出验证集和测试集。
- 训练中:使用验证集监控训练过程,防止过拟合(如果验证集指标开始下降,而训练集指标还在上升,说明模型可能过拟合了)。
- 训练后:
- 在测试集上运行基座模型和微调后的模型,记录所有主指标。
- 进行通用能力测试和泛化能力测试。
- 人工抽查测试集和通用能力测试中的一些样本输出,进行质量分析。
- 综合所有维度做出判断。主指标大幅提升,同时通用能力没有显著退化,才是一次成功的微调。