
分析式AI基础
# 分析式AI与生成式AI
| 分析式AI (Analytical AI) | 生成式AI (Generative AI) | |
|---|---|---|
| 目标 | 分析和解释数据,提供洞察、预测或决策支持。 | 生成新的内容,这些内容在形式和风格上与训练数据相似。 |
| 用途 | 数据分析、预测建模、风险评估、分类任务等。 | 文本生成、图像创作、音频生成、内容创作等。 |
| 输出 | 报告、图表、预测结果、决策建议等。 | 新的文本、图像、音频、视频等内容。 |
| 技术原理 | 基于统计分析、机器学习算法(如回归分析、决策树、神经网络等)。 | 基于生成式大模型,如DeepSeek,Qwen, ChatGPT(Transformer架构)。 |
| 数据需求 | 需要高质量、标注清晰的数据,以学习数据中的规律。 | 需要大量未标注数据,以学习数据分布。 |
| 应用场景 | 金融风险评估、医疗诊断、市场预测、客户行为分析等。 | 广告设计、内容创作、游戏开发、艺术创作等。 |
| 风险挑战 | 模型可能过度拟合训练数据,导致在新数据上表现不佳;数据偏差可能导致错误决策。 | 生成内容可能包含错误、误导性信息或不符合伦理的内容;需防止内容被滥用。 |
# 机器学习的模型
来源背景:由Kaggle社区投票选出,Kaggle是国外知名的数据科学竞赛平台,企业通过悬赏方式发布数据挑战,国内对应平台是阿里云天池
分类算法:C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN,Adaboost,CART
- 核心特征:预先定义类别标签(如萝莉/御姐),属于监督学习
- 决策逻辑:人工制定分类规则(如年龄>35岁归为御姐)
- 典型场景:银行客户分类、商品品类划分
- 与聚类的区别:分类是"上帝视角"已知规则,聚类是"探索视角"自动发现模式
聚类算法:K-Means,EM
- 核心思想:"人以类聚,物以群分"的降维思维
- 典型应用:银行5万客户自动分群(如A组13000人,B组8000人)
- 技术特点:无监督学习,根据多维特征(年龄/收入/消费等)自动划分
- 业务价值:实现批发式营销策略,将千万级客户简化为20种类型
关联分析:Apriori
- 核心目标:发现"闺蜜关系"式的频繁共现模式
- 经典案例:
- 沃尔玛"啤酒+尿布"组合(1993年发现)
- 超市"洗发水+护发素"连带销售
- 麦当劳"汉堡+薯条"推荐系统
- 算法本质:通过交易记录挖掘商品间的条件概率P(A|B)
连接分析:PageRank
- 核心目标:识别网络中的影响力节点
- 典型应用:
- 谷歌PageRank网页排序
- 希拉里"邮件门"关键人物识别(从9000封邮件中定位20个核心人物)
- 社交网络六度空间理论验证
- 技术特点:基于图结构计算节点权重,与关联分析的本质区别在于分析对象是网络而非共现
# 机器学习算法工具包
| 算法 | 工具 |
|---|---|
| 决策树 | from sklearn.tree import DecisionTreeClassifier |
| 朴素贝叶斯 | from sklearn.naive_bayes import MultinomialNB |
| SVM | from sklearn.svm import SVC |
| KNN | from sklearn.neighbors import KNeighborsClassifier |
| Adaboost | from sklearn.ensemble import AdaBoostClassifier |
| K-Means | from sklearn.cluster import KMeans |
| EM | from sklearn.mixture import GMM |
| Apriori | frome fficient_apriori import apriori |
| PageRank | import networkx as nx |
# 贝叶斯原理
# 正向概率 vs 逆向概率
正向概率:你知道全貌,推测结果
你知道袋子里3个黑球7个白球 → 伸手摸一次,摸到黑球的概率是30%
这是"上帝视角",你什么都知道。
逆向概率:你知道结果,反推全貌
你不知道袋子里黑白球比例,但你摸了10次,8次黑球2次白球 → 你推测袋子里黑球大概占80%
这才是我们现实中遇到的情况——我们几乎永远不知道全貌。
# 四个核心概念,用一个例子串起来
# 场景:你收到一封邮件,标题写着"恭喜中奖100万"
1. 先验概率 P(A) — 你的经验判断
在没看邮件内容之前,你就知道:邮件是垃圾邮件的概率大概80%,是正常邮件的概率20%。
这个80%就是先验概率,是你根据过去的经验提前给的判断。
2. 条件概率 P(B|A) — 如果是某种情况,出现这个结果的概率
P(B|A) 读作"在A发生的前提下,B发生的概率"
如果这封邮件确实是垃圾邮件,里面出现"恭喜中奖"这个词的概率是90%
如果这封邮件是正常邮件,里面出现"恭喜中奖"的概率是5%(可能真的是公司年会通知)
3. 似然函数 — 用来衡量"参数靠不靠谱"
你抛了10次硬币,10次都是正面朝上。那这枚硬币是均匀的可能性有多大?
似然函数就是在回答:给定观察到的数据,我的假设(硬币均匀)有多大可能成立?
10次全正面 → 硬币均匀的似然极低 → 你会怀疑这硬币有问题
4. 后验概率 P(A|B) — 看到结果后,反推原因
P(A|B) 读作"在B发生的前提下,A发生的概率"
你已经看到了邮件里写着"恭喜中奖"(B发生了),那这封邮件是垃圾邮件(A)的概率有多大?
这就是后验概率——看到证据之后,更新你的判断
# 贝叶斯公式:一句话版本
后验概率 = 先验概率 × 似然函数 / 证据
翻译成人话:
看到证据后的新判断 = 原来的判断 × 证据支持程度 / 参照基准
# 完整算一遍
回到垃圾邮件的例子:
| 垃圾邮件(A) | 正常邮件(非A) | |
|---|---|---|
| 先验概率 | 80% | 20% |
| 出现"恭喜中奖"的条件概率 | 90% | 5% |
收到一封写着"恭喜中奖"的邮件,它是垃圾邮件的概率?
不用公式的直觉:本来就是垃圾邮件的概率很高(80%),加上"恭喜中奖"这个词在垃圾邮件里出现概率远高于正常邮件(90% vs 5%),所以它大概率是垃圾邮件。
用公式算:
- P(垃圾邮件|恭喜中奖) = P(垃圾邮件) × P(恭喜中奖|垃圾邮件) / P(恭喜中奖)
- = 80% × 90% / (80%×90% + 20%×5%)
- = 72% / 73%
- ≈ 98.6%
看到"恭喜中奖"之后,垃圾邮件的概率从80%飙升到了98.6%。
# 贝叶斯的核心思想
不是一次性给出准确答案,而是不断用新证据修正你的判断。
初始判断:80%是垃圾邮件(先验) → 看到"恭喜中奖":更新到98.6%(后验) → 又发现发件人是你公司邮箱:再更新,可能降到20% → 打开发现真的是年会通知:再更新到5%
每一条新证据都在修正你的判断,越来越接近真相。
公式里的 P(B) 那个分母,叫"证据"或"归一化常数",它的作用就是保证所有可能性的概率加起来等于100%。实际计算时经常可以忽略,因为你是比较哪个更大概率,不需要精确值。
就这样,贝叶斯其实就是:先猜一个,看到新证据就更新猜测,越更新越准。
贝叶斯公式推导
# 贝叶斯公式推导,一步步来
# 起点:条件概率的定义
条件概率本身就是个常识,不用背。
P(A|B) = A和B同时发生的概率 / B发生的概率
为什么?举个例子:
班上40人,20个男生,20个女生 戴眼镜的有12人,其中8个男生4个女生
问:已知一个人戴眼镜,这个人是男生的概率?
直觉就能算:戴眼镜的12人里,8个是男生,所以 8/12 ≈ 67%
用公式写就是:
P(男生|戴眼镜) = P(男生且戴眼镜) / P(戴眼镜)
= (8/40) / (12/40)
= 8/12
2
3
这就是条件概率的定义,就是数数,没什么高深的。
# 推导:两行就够了
同一个定义,换一下A和B的位置:
P(A|B) = P(A和B同时发生) / P(B) ...①
P(B|A) = P(A和B同时发生) / P(A) ...②
2
3
注意到了吗?①和②的分子是一样的,都是 P(A和B同时发生)。
从②变形一下,把分子单独拎出来:
P(A和B同时发生) = P(B|A) × P(A) ...③
把③代入①的分子:
P(A|B) = P(B|A) × P(A) / P(B)
完事了。这就是贝叶斯公式。
# 所以贝叶斯公式本质上是什么?
就是把条件概率定义里的 P(A和B同时发生) 换了一种写法而已。
原来你写成:
P(A|B) = P(A和B同时发生) / P(B)
现在你把分子换成了另一个角度的表达:
P(A|B) = P(B|A) × P(A) / P(B)
为什么这个替换有意义?
因为在现实里:
- P(A和B同时发生) — 很难直接算,你得知道两个事同时发生的数据
- P(B|A) — 容易知道,"如果是垃圾邮件,出现'恭喜中奖'的概率",统计一下历史邮件就有了
- P(A) — 也容易知道,垃圾邮件占总邮件的比例,统计就有
所以贝叶斯公式的意义就是:把一个你算不出来的东西,用你能算出来的东西表达出来。
# 用邮件例子再走一遍
P(垃圾|恭喜中奖) = P(恭喜中奖|垃圾) × P(垃圾) / P(恭喜中奖)
- P(恭喜中奖|垃圾) = 90% → 统计历史垃圾邮件,90%含有这个词,能算
- P(垃圾) = 80% → 历史邮件里80%是垃圾邮件,能算
- P(恭喜中奖) = 73% → 所有邮件中出现这个词的比例,能算
但如果没有贝叶斯公式,你想要 P(垃圾|恭喜中奖),就得直接统计"所有含'恭喜中奖'的邮件里有多少是垃圾邮件",这个数据你可能没有。
所以贝叶斯做了一件事:让你用容易获得的数据,去推算不容易获得的数据。
这就是"逆向概率"的精髓——从结果反推原因。
Thinking:假设有一种病叫做“贝叶死”,它的发病率是万分之一,即10000人中会有1个人得病。现有一种测试可以检验一个人是否得病的准确率是99.9%,误报率(假阳)是0.1%那么,如果一个人被查出来患有“叶贝死”,实际上患有的可能性有多大?
# 先用直觉理解
10000个人去体检,查出阳性(说你有病)的有11个人:
- 1个人是真的有病,被正确查出来了
- 10个人其实没病,但是被误报了
所以你拿到阳性报告,你是真有病的概率只有 1/11 ≈ 9%
不是99.9%,而是9%! 反直觉吧?下面讲为什么。
# 画个图最清楚
10000个人:
有病的人:1人
├── 查出阳性(真阳性):99.9% × 1 = 约1人 ✓
└── 查出阴性(漏诊):0.1% × 1 = 约0人
没病的人:9999人
├── 查出阳性(误报):0.1% × 9999 = 约10人 ✗
└── 查出阴性(真阴性):99.9% × 9999 = 约9989人
2
3
4
5
6
7
所有被查出阳性的人 = 1(真有病)+ 10(误报)= 11人
这11个人里,真正有病的只有1个,所以 1/11 ≈ 9%
# 为什么不是99.9%?
99.9%是检测的准确率,不是你真有病的概率,这两个不是一回事。
打个比方:
一个老师批卷子99%正确率。但全班只有1个人真正考了满分,老师却给10个人打了满分。
你拿到满分,你是真的满分的概率 = 1/10 = 10%,不是99%。
关键在于:没病的人太多了(9999人),哪怕误报率只有0.1%,误报出来的人数(10人)也远超真正有病的人数(1人)。
# 用公式算
# 第一步:先理解联合概率 P(B1, A)
联合概率就是两件事同时发生的概率。
P(B1, A) = "既有病,又查出阳性"的概率
P(B1, A) = P(B1) × P(A|B1)
= 0.01% × 99.9%
= 0.00999%
≈ 0.01%
2
3
4
翻译:10000人里,既有病又查出阳性的,大约1个人。
怎么理解这个乘法?
- 你首先得是有病的那个人(概率0.01%,万分之1)
- 然后还得被查出来(概率99.9%)
- 两件事要同时满足,所以概率相乘
# 第二步:同理算 P(B2, A)
P(B2, A) = "没病,但查出阳性"的概率
P(B2, A) = P(B2) × P(A|B2)
= 99.99% × 0.1%
= 0.09999%
≈ 0.1%
2
3
4
翻译:10000人里,没病却被误报阳性的,大约10个人。
# 第三步:查出阳性的总概率 P(A)
所有查出阳性的人 = 真有病查出来的 + 没病被误报的
P(A) = P(B1, A) + P(B2, A)
= 0.01% + 0.1%
= 0.11%
2
3
翻译:10000人里,总共有11个人会被查出阳性。
# 第四步:算后验概率 P(B1|A)
现在终于可以回答核心问题了:查出阳性,真的有病的概率是多少?
P(B1|A) = P(B1, A) / P(A)
= 0.01% / 0.11%
= 1/11
≈ 9%
2
3
4
就是联合概率 ÷ 总阳性概率 = 真阳性 / 所有阳性
# 再对照一遍图
所有阳性的人(11人)
├── 真有病的(1人) → 来自 P(B1, A) = 0.01%
└── 误报的(10人) → 来自 P(B2, A) = 0.1%
真有病的概率 = 1 / (1+10) = 1/11 ≈ 9%
2
3
4
5
# 为什么这个结论反直觉?
因为人的直觉会忽略基础概率(先验概率)。
发病率只有万分之一,这意味着没病的人是9999个,有病的才1个。没病的人基数太大了,即使误报率极低(0.1%),误报出来的绝对数量也远超真正有病的数量。
贝叶斯原理就是在提醒你:别只看检测准确率,还要看这个病本身有多罕见。
# 从具体例子到通用公式
刚才我们算了两件事:
查出阳性,真有病的概率: P(B1|A) = 0.01% / (0.01% + 0.1%) ≈ 9%
查出阳性,其实没病的概率: P(B2|A) = 0.1% / (0.01% + 0.1%) ≈ 91%
2
注意到了吗?分母是一样的,都是 0.01% + 0.1%,分子不同。
把分子分母替换回之前的式子:
0.01% = P(B1) × P(A|B1) — 有病且查阳的概率
0.1% = P(B2) × P(A|B2) — 没病但查阳的概率
2
所以:
P(B1|A) = P(B1) × P(A|B1) / [P(B1)×P(A|B1) + P(B2)×P(A|B2)]
P(B2|A) = P(B2) × P(A|B2) / [P(B1)×P(A|B1) + P(B2)×P(A|B2)]
2
这就是二元情况的贝叶斯公式。
# 推广到通用情况
刚才只有两种可能:有病、没病。但现实中可能有3种、5种、N种可能。
比如:
- 你的邮件可能是:垃圾邮件、促销邮件、正常邮件、诈骗邮件(4种)
- 你的病症可能是:感冒、流感、新冠、过敏(4种)
原理完全一样,只是把2种情况扩展到N种:
P(Bi) × P(A|Bi)
P(Bi|A) = ————————————————————————
P(B1)×P(A|B1) + P(B2)×P(A|B2) + ... + P(Bn)×P(A|Bn)
2
3
用求和符号写成:
P(Bi) × P(A|Bi)
P(Bi|A) = ——————————————————————
n
∑ P(Bj) × P(A|Bj)
j=1
2
3
4
5
就这。 之前两个情况是N=2的特例,通用公式就是把2扩展成N。
# 分母是什么?
分母就是把所有可能情况下,A发生的概率全加起来。
用邮件分类举例:
A = 邮件含有"恭喜中奖" B1=垃圾邮件,B2=促销邮件,B3=正常邮件,B4=诈骗邮件
P(A) = P(垃圾)×P(中奖|垃圾) + P(促销)×P(中奖|促销) + P(正常)×P(中奖|正常) + P(诈骗)×P(中奖|诈骗)
就是不管邮件是什么类型,出现"恭喜中奖"的总概率。
这个分母叫证据因子(也叫归一化常数),作用就是保证所有 P(Bi|A) 加起来等于100%。
# 通用公式翻译成人话
某种原因导致当前结果的概率 = 这种原因的先验概率 × 这种原因下结果的条件概率 / 所有原因导致这个结果的总概率
再简化:
某个猜测靠谱的程度 = 这个猜测本来有多靠谱 × 证据多支持这个猜测 / 证据出现的总可能性
核心思想始终没变:用你已经知道的信息(先验+似然),推算你不知道的信息(后验)。
# 朴素贝叶斯
朴素贝叶斯:
- 一种简单但极为强大的预测建模算法
- 假设每个输入变量是独立的。这是一个强硬的假设,实际情况并不一定,但是这项技术对于绝大部分的复杂问题仍然非常有效
朴素贝叶斯模型由两种类型的概率组成:
- 每个类别的概率P(Cj)
- 每个属性的条件概率P(Ai|Cj)
什么是类别概率:
•假设我有7个棋子,其中3个是白色的,4个是黑色的那么棋子是白色的概率就是3/7,黑色的概率就是4/7=>这个是类别概率
什么是条件概率:
•假设我把这7个棋子放到了两个盒子里,其中盒子A里面有2个白棋,2个黑棋;盒子B里面有1个白棋,2个黑棋那么在盒子A中抓到白棋的概率就是1/2,抓到黑棋的概率也是1/2,这个就是条件概率,也就是在某个条件(比如在盒子A中)下的概率
# 训练朴素贝叶斯模型的过程:
- 在朴素贝叶斯中,我们要统计的是属性的条件概率,也就是假设取出来的是白色的棋子,那么它属于盒子A的概率是2/3
- 先给出训练数据,以及这些数据对应的分类
- 计算类别概率和条件概率
- 使用概率模型(基于贝叶斯原理)对新数据进行预测
# 朴素贝叶斯分类(离散值):
- 如何根据身高,体重,鞋码,判断是否为男女,比如一个新的数据:身高“高”、体重“中”,鞋码“中”=>男or女?
- 求在A1、A2、A3属性下,Cj的概率
好,我用这个例子一步步带你算。
先看表格数据
| 编号 | 身高 | 体重 | 鞋码 | 性别 |
|---|---|---|---|---|
| 1 | 高 | 重 | 大 | 男 |
| 2 | 高 | 重 | 大 | 男 |
| 3 | 中 | 中 | 大 | 男 |
| 4 | 中 | 中 | 中 | 男 |
| 5 | 矮 | 轻 | 小 | 女 |
| 6 | 矮 | 轻 | 小 | 女 |
| 7 | 矮 | 中 | 中 | 女 |
| 8 | 中 | 中 | 中 | 女 |
现在来了一个人:身高"高"、体重"中"、鞋码"中",猜男还是女?
第一步:算类别概率
8个人里,4男4女:
- P(男) = 4/8 = 1/2
- P(女) = 4/8 = 1/2
第二步:算条件概率
男性的条件概率(C1=男):
- P(身高=高|男) = 1/2
- P(体重=中|男) = 1/2
- P(鞋码=中|男) = 1/4
朴素贝叶斯的"朴素"就在这里——假设三个属性互相独立,直接乘起来:
P(A1A2A3|男) = 1/2 × 1/2 × 1/4 = 1/16
女性的条件概率(C2=女):
- P(身高=高|女) = 0(4个女性没有一个是"高"的)
- P(体重=中|女) = 1/2
- P(鞋码=中|女) = 1/2
乘起来:
P(A1A2A3|女) = 0 × 1/2 × 1/2 = 0
第三步:比较大小
因为分母 P(A1A2A3) 对男女都一样,直接比分子:
- 男性:P(A1A2A3|男) × P(男) = 1/16 × 1/2 = 1/32
- 女性:P(A1A2A3|女) × P(女) = 0 × 1/2 = 0
1/32 > 0,所以分类结果是男性。
这个例子最值得注意的一点:
女性那边的概率直接变成0了,就因为训练数据里没有"身高=高"的女性。这就是朴素贝叶斯的一个坑——某个条件概率为0,整个乘积就归零了。
# 朴素贝叶斯分类(连续值):
| 编号 | 身高(CM) | 体重(斤) | 鞋码(欧码) | 性别 |
|---|---|---|---|---|
| 1 | 183 | 164 | 45 | 男 |
| 2 | 182 | 170 | 44 | 男 |
| 3 | 178 | 160 | 43 | 男 |
| 4 | 175 | 140 | 40 | 男 |
| 5 | 160 | 88 | 35 | 女 |
| 6 | 165 | 100 | 37 | 女 |
| 7 | 163 | 110 | 38 | 女 |
| 8 | 168 | 120 | 39 | 女 |
身高180、体重120,鞋码41,请问该人是男是女呢
- 可以假设男性和女性的身高、体重、鞋码都是正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数
- 有了密度函数,就可以把值代入,算出某一点的值
比如,男性的身高是均值179.5、标准差为3.697的正态分布。所以男性的身高为180的概率为0.1069
同理可以计算得出男性体重为120的概率为0.000382324,男性鞋码为41号的概率为0.120304111
P(A1A2A3|C1)=P(A1|C1)P(A2|C1)P(A3|C1)=0.10690.0003823240.120304111=4.9169e-6
P(A1A2A3|C2)=P(A1|C2)P(A2|C2)P(A3|C2)=0.000001474890.0153541440.120306074=2.7244e-9
很明显这组数据分类为男的概率大于分类为女的概率
# 朴素贝叶斯分类:
常用于文本分类,文本过滤、情感预测、推荐系统等,尤其是对于英文等语言来说,分类效果很好
准备阶段,需要确定特征属性,属性值以及label =>训练集
训练阶段,输入是特征属性和训练样本,输出是分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率
应用阶段,使用分类器对新数据进行分类
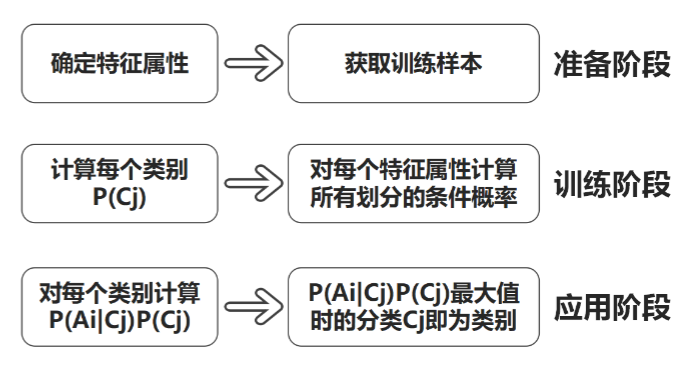
朴素贝叶斯分类,就像教一个小孩认东西。
整个流程就三步:
第一步:准备阶段——把"教材"准备好
你要教小孩认男生女生,得先告诉他"看什么来判断"。
- 特征属性:就是你要看的东西。比如身高、体重、鞋码
- 属性值:每个属性具体有哪些可能。比如身高有高/中/矮
- Label:就是你要分的类别。比如男/女
- 训练样本:就是教材例题,一堆已经标好男女的人的数据
这一步就是:定好看什么、分什么、准备好例题。
第二步:训练阶段——让小孩"背规律"
把例题给小孩看,让他自己总结规律。他不会去理解为什么,就是纯背数字。
背两样东西:
P(Cj)——类别概率:男生占多少、女生占多少
- 8个人里4男4女 → 男生50%,女生50%
P(Ai|Cj)——条件概率:在男生里,身高高的占多少?体重中的占多少?
- 男生4人里2人身高高 → P(身高=高|男) = 1/2
- 男生4人里1人鞋码中 → P(鞋码=中|男) = 1/4
背完了,"分类器"就训练好了。 分类器说白了就是一堆概率数字的表格。
第三步:应用阶段——新人来了,判断!
来了一个人,身高高、体重中、鞋码中,你猜男女?
小孩就翻他背的表格,算两笔账:
- 男生的分数 = P(男) × P(身高=高|男) × P(体重=中|男) × P(鞋码=中|男)
- 女生的分数 = P(女) × P(身高=高|女) × P(体重=中|女) × P(鞋码=中|女)
哪边分数高,就判哪边。就这么简单粗暴。
再用一个生活比喻总结:
想象你是相亲红娘:
- 准备阶段:你收集了一堆会员资料(身高、收入、学历,以及他们最终有没有相亲成功)
- 训练阶段:你翻资料,总结规律——比如成功的会员里80%年收入30万以上,失败的里只有20%
- 应用阶段:来了个新人,你根据他的条件,对照你总结的规律,算一下成功的概率大还是失败的概率大,给出预测
朴素贝叶斯就是这样一个"只看统计概率、不问为什么"的方法。 它不理解因果关系,但它靠着大量的数据统计,往往效果还不错。
# sklearn工具使用:
- from sklearn.naive_bayes import GaussianNB
高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度
GaussianNB(priors=None)#模型创建
priors,先验概率大小,如果没有给定,模型则根据样本数据自己计算(利用极大似然法)
查看模型对象的属性:
class_prior_:每个样本的概率
class_count_:每个类别的样本数量
theta_:每个类别中每个特征的均值
sigma_:每个类别中每个特征的方差
- from sklearn.naive_bayes import MultinomialNB
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的TF-IDF值等
MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
alpha:先验平滑因子,默认等于1,当等于1时表示拉普拉斯平滑
fit_prior:是否去学习类的先验概率,默认是True
class_prior:各个类别的先验概率,如果没有指定,则模型会根据数据自动学习,每个类别的先验概率相同,即类别数N分之一
模型对象的属性:
class_count_:训练样本中各类别对应的样本数
feature_count_:每个类别中各个特征出现的次数
- from sklearn.naive_bayes import BernoulliNB
伯努利朴素贝叶斯:特征变量是布尔变量,符合0/1分布,在文档分类中特征是单词是否出现
BernoulliNB(alpha=1.0, fit_prior=True, class_prior=None)
alpha:平滑因子,与多项式中的alpha一致
fit_prior:是否去学习类的先验概率,默认是True
class_prior:各个类别的先验概率,如果没有指定,则模型会根据数据自动学习,每个类别的先验概率相同,即类别数N分之一
模型对象的属性:
class_count_:训练样本中各类别对应的样本数
feature_count_:每个类别中各个特征出现的次数
# 决策树与随机森林
# 决策树:
决策树基本上就是把我们以前的经验总结出来
- 常见的决策树算法有C4.5、ID3和CART
- Thinking:如何构造一个判断是否去打篮球的决策树
将哪个属性(天气、温度、湿度、刮风)作为根节点是个关键问题
| 天气 | 温度 | 湿度 | 刮风 | 是否打球 |
|---|---|---|---|---|
| 晴天 | 高 | 中 | 否 | 否 |
| 晴天 | 高 | 中 | 是 | 否 |
| 阴天 | 高 | 高 | 否 | 是 |
| 小雨 | 高 | 高 | 否 | 是 |
| 小雨 | 低 | 高 | 否 | 否 |
| 晴天 | 中 | 中 | 是 | 是 |
| 阴天 | 中 | 高 | 是 | 否 |
好,用你这个打篮球的例子来讲。
决策树是什么?
就是一棵"问问题"的树。从根节点开始,每个节点问一个问题,根据回答走不同的分支,最终到达叶子节点给出结论。
比如:先问天气,晴天→再问温度,高温→不打球。就这么一步步问下去。
核心问题:先问哪个属性?
天气、温度、湿度、刮风,哪个放根节点?这是决策树最关键的问题。
选错了,树会又深又乱;选对了,几步就能得出结论。
怎么选?看谁最能区分"打不打球"
我们来算一下,用"信息增益"来衡量——哪个属性最能减少不确定性。
先算总体不确定性:
7条数据:
- 打球:3条
- 不打球:4条
总体不确定性(信息熵)= 不确定性混合度,打球不打球各占一部分
再看每个属性怎么切分:
天气:
- 晴天(3条):2不打、1打 → 很乱
- 阴天(2条):1打、1不打 → 很乱
- 小雨(2条):1打、1不打 → 很乱
天气切完,每组还是很混乱,说明天气不是最好的根节点。
湿度:
- 高(4条):2打、2不打 → 还是乱
- 中(3条):1打、2不打 → 也乱
刮风:
- 否(4条):2打、2不打 → 乱
- 是(3条):1打、2不打 → 乱
看起来每个属性单独切都不太干净,这是因为数据量太少(才7条)。但逻辑是一样的——选让分组后最"纯"的那个属性当根节点。
用大白话理解:
想象你是教练,要判断今天打不打球。你会先看最关键的那个因素。
如果"湿度=高"的时候基本都打球(3条里有3条打),那湿度就是最好的根节点,因为一问湿度就能直接做决定。
这就是信息增益的含义:哪个属性能把数据切得最"纯",就先选它。
三种算法的区别:
| 算法 | 怎么选属性 | 特点 |
|---|---|---|
| ID3 | 用信息增益 | 偏好取值多的属性,容易被骗 |
| C4.5 | 用信息增益率 | 修正了ID3的偏好问题 |
| CART | 用基尼系数 | 既可分类也可回归,sklearn默认 |
最终画出来的树大概长这样:
天气?
/ | \
晴天 阴天 小雨
| | |
温度? 打球 湿度?
/ \ / \
高 中 高 低
| | | |
不打 打 打球 不打
2
3
4
5
6
7
8
9
每到一个节点就问一个问题,一路问下去,直到得出结论。
和朴素贝叶斯对比一下:
- 朴素贝叶斯:同时看所有属性,概率乘起来比大小
- 决策树:一个一个属性看,像走迷宫一样,走到头就是答案
决策树的好处是可解释性强——你能看到它每一步怎么判断的,不像贝叶斯是个黑盒概率。
# 信息、熵以及信息增益:
# 一、信息:越不可能的事,信息量越大
公式:I(X=xᵢ) = -log₂ p(xᵢ)
别被公式吓到,它说的就是一句话:一件事越不可能发生,它发生时带给你的信息量越大。
举几个例子:
- "明天太阳从东边升起" → 肯定会发生,概率≈1 → 信息量≈0(废话,谁都知道)
- "你买彩票中了500万" → 概率极低 → 信息量巨大(所有人都会震惊)
- "今天下雨了" → 概率大概50% → 信息量中等
用公式算一下感受:
- 概率100%(1.0):-log₂(1.0) = 0 → 零信息量
- 概率50%(0.5):-log₂(0.5) = 1 → 1比特信息
- 概率1%(0.01):-log₂(0.01) ≈ 6.64 → 大信息量
概率越小,信息量越大,这就是那个公式的意思。
# 二、熵:混乱程度的度量
公式:H(X) = -Σ p(xᵢ) × log₂ p(xᵢ)
熵就是"平均信息量",衡量的是一组数据有多混乱。
用最直白的方式理解:
想象一个盒子,里面有两种球:红球和蓝球。
情况1:10个全是红球
- 你闭着眼摸,肯定摸到红的,没有任何不确定性
- 熵 = 0(完全不混乱,完全可预测)
情况2:5红5蓝
- 你摸一次,完全猜不到是红是蓝
- 熵 = 1(最混乱,最不确定)
情况3:9红1蓝
- 大概率摸到红的,有一定把握但不是完全确定
- 熵 = 0.47(有点混乱,但不多)
所以:熵越大 = 越混乱 = 越不确定 = 越难预测
# 三、信息增益:切一刀之后,混乱减少了多少
公式:g(D, A) = H(D) - H(D|A)
翻译成人话:
信息增益 = 切之前的不确定性 - 切之后的不确定性
还是用打篮球的例子:
7条数据,3打4不打,整体是混乱的(熵比较高)
现在我用"天气"这个属性来切一刀:
- 晴天的一组
- 阴天的一组
- 小雨的一组
切完之后,看每组内部是不是比之前更"纯"了。
如果切完每组都很纯(比如晴天全不打、阴天全打),说明"天气"这个属性很管用,信息增益大。
如果切完每组还是很混乱,说明"天气"没啥用,信息增益小。
决策树就是每次选信息增益最大的属性来切,切得越纯越好。
# 用打比方串起来
想象你有一锅混在一起的红豆和绿豆,你想把它们分开。
- 熵:这锅豆子混得多厉害。全是一种豆就是熵0,各占一半就是熵最大
- 信息增益:你用筛子筛了一下的效果。筛完之后如果一边全是红豆一边全是绿豆,信息增益就大;如果筛完还是混的,信息增益就小
- 决策树的构建过程:不断找最好的筛子(属性),一次筛一点,直到完全分开
所以整个流程就是:
- 算当前数据的熵(有多混乱)
- 对每个属性算信息增益(用这个属性切一刀能减少多少混乱)
- 选信息增益最大的属性当节点
- 切完之后对每个子组重复1-3
- 直到切不动了(纯了)为止
# 随机森林的生成:
好,接着决策树来讲随机森林。
# 先回答一个问题:决策树有什么毛病?
决策树很容易过拟合——就是它把训练数据记得太死了,换一批新数据就不灵了。
打个比方:一个学生把模拟卷的答案全背下来了,考试考一样的内容满分,题目稍微换一下就懵了。这就是过拟合。
随机森林就是来治这个毛病的。
# 核心思想:三个臭皮匠,顶个诸葛亮
一棵决策树容易过拟合,那我就造很多棵树,每棵树独立判断,最后投票决定。
- 5棵树说"打球",3棵树说"不打球" → 少数服从多数 → 结论:打球
这就是随机森林。
# 怎么造出"不一样"的树?
如果每棵树用的数据一样、选的特征一样,那造出来的树全都一样,投票就没意义了。
所以随机森林做了两次随机:
第一次随机:随机抽数据(Bagging)
- 训练集有N条数据,每棵树随机有放回地抽N条
- "有放回"就是同一条数据可能被抽到多次,也可能一次都没抽到
- 所以每棵树看到的训练数据都不一样
举个例子:
- 原始数据7条:1号、2号、3号、4号、5号、6号、7号
- 树A抽到:1号、3号、3号、5号、7号、2号、2号(3号和2号重复了,4号和6号没抽到)
- 树B抽到:2号、4号、6号、6号、1号、5号、3号(6号重复,7号没抽到)
每棵树的训练集都不一样,长出来的树自然就不一样了。
第二次随机:随机选特征
- 假设有4个特征(天气、温度、湿度、刮风),指定每次只随机挑2个来选
- 每个节点只在挑出的2个特征里选最优的那个来切分
- 这又进一步让树长得不一样
# 为什么要这样?
一棵树:可能被某些异常数据带偏,判断失误
很多棵树:每棵树可能犯不同的错,但投票之后,少数错误会被多数正确给压下去
就像考试:
- 一个学生可能蒙对一道题,也可能蒙错
- 100个学生分别蒙,取多数人的答案,正确的概率就高很多
# 用一张图总结
原始数据
│
├── 有放回抽样 → 训练集A → 随机选特征 → 树1 → 投票:打
├── 有放回抽样 → 训练集B → 随机选特征 → 树2 → 投票:不打
├── 有放回抽样 → 训练集C → 随机选特征 → 树3 → 投票:打
├── 有放回抽样 → 训练集D → 随机选特征 → 树4 → 投票:打
└── 有放回抽样 → 训练集E → 随机选特征 → 树5 → 投票:不打
↓
3打 vs 2不打 → 结论:打
2
3
4
5
6
7
8
9
# 名词解释
| 术语 | 大白话 |
|---|---|
| Bagging | 每棵树随机抽不同的数据来训练,最后投票 |
| Bootstrap | 有放回地抽样的方式 |
| 弱分类器 | 每棵树单独看都不算特别强 |
| 强分类器 | 很多弱分类器投票后,整体变强 |
| 过拟合 | 训练数据记太死,新数据不行 |
| 方差 | 每次训练结果波动大,随机森林能减少这个波动 |
一句话总结:随机森林 = 很多棵不同的决策树 + 投票,靠数量和多样性取胜。
# 决策树工具:
- from sklearn.tree import DecisionTreeClassifier
- DecisionTreeClassifier(criterion='entropy')
criterion,gini或者entropy,默认是基尼系数,后者是信息熵
max_depth,决策树最大深度,默认为None
min_samples_split,内部节点再划分所需最小样本数
max_leaf_nodes,最大叶子节点数
class_weight,类别权重
# 随机森林工具:
- from sklearn.ensemble importRandomForestClassifier
- RandomForestClassifier(n_estimators=10, criterion='gini')
n_estimators,森林中决策树的个数,默认为10
max_features,寻找最佳分割时需要考虑的特征数目,默认
为auto,即max_features=sqrt(n_features)
criterion,gini或者entropy,默认是基尼系数,后者是信息熵
max_depth,决策树最大深度,默认为None
min_samples_split,内部节点再划分所需最小样本数
max_leaf_nodes,最大叶子节点数
class_weight,类别权重
# SVM工具
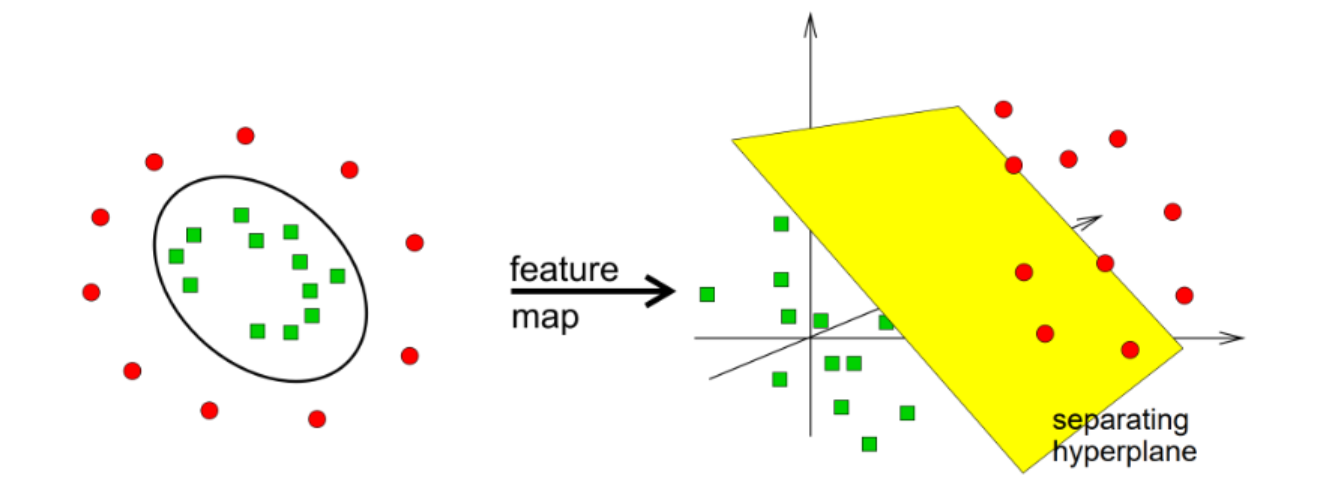
# 先理解一个概念:什么是"线性可分"?
就是你能画一条直线(或平面),把两类东西完全分开。
能分开的例子:
- 男生站左边,女生站右边,中间画条线就隔开了 → 线性可分
分不开的例子:
- 想象一个靶心,红点在圆心,绿点围在外面一圈 → 你怎么画直线都分不开 → 线性不可分
# SVM的核心大招:升维
图里左边那个就是"分不开"的情况:绿点被红点包围,画不出一条线把它们分开。
SVM说:分不开?那就把它变到更高维的空间去,在那个空间里就能分开了。
# 用最经典的例子理解:桌上撒胡椒面
想象一张桌子上,绿棋子放在中间围成一圈,红棋子散在圈外。
你在桌面上看,不管怎么画直线,都没法把绿的红的分开。
但如果你从侧面看呢?
如果你把绿棋子都往上抬高一点(加了一个高度维度),绿的飘在上面,红的还在桌面上。这时候你在中间插一块板子,就能把绿的红的完全隔开了。
这就是升维:
- 二维桌面 → 分不开
- 三维空间(加了一个高度)→ 一块板子就分开了
# 对应图里的内容
左边:低维空间(二维)
- 绿点在中间,红点在外面
- 画不出直线分开 → "complex in low dimensions"
中间箭头:特征映射(feature map)
- 用一个非线性函数,把数据映射到更高维
- 相当于给每个点加了一个"高度"
右边:高维空间(三维)
- 绿点和红点被一个平面(分离超平面)完美隔开
- → "simple in higher dimensions"
# 用大白话总结SVM的思想
| 步骤 | 大白话 |
|---|---|
| 1. 发现问题 | 二维空间里分不开 |
| 2. 升维 | 把数据变到更高维的空间 |
| 3. 分开 | 在高维空间里找一个平面切开 |
| 4. 回来 | 把这个平面的结果映射回原来的维度 |
就像你想把混在一起的沙子和铁粉分开,平面上搅来搅去分不开,但加一块磁铁(升维),铁粉就被吸上去了,一下就分开了。
SVM就是用"升维"这个手段,把分不开的问题变成分得开的问题。
# 名词解释
| 术语 | 大白话 |
|---|---|
| 分离超平面 | 高维空间里那块把两类数据隔开的"板子" |
| 特征映射 | 把数据从低维变到高维的那个函数 |
| 线性不可分 | 画直线分不开 |
| 核函数 | 帮你做升维映射的工具,不用真的算高维坐标 |
SVM现在用得比较少了,因为现在有神经网络了。
SVM工具:
- sklearn中支持向量分类主要有三种方法:SVC、NuSVC、LinearSVC
- sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0,
shrinking=True, probability=False, tol=0.001, cache_size=200,
class_weight=None, verbose=False, max_iter=-1,
decision_function_shape='ovr', random_state=None)
•sklearn.svm.NuSVC(nu=0.5, kernel='rbf', degree=3, gamma='auto',
coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200,
class_weight=None, verbose=False, max_iter=-1,
decision_function_shape='ovr', random_state=None)
•sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', dual=True,
tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True,
intercept_scaling=1, class_weight=None, verbose=0,
random_state=None, max_iter=1000)
常用参数:
C,惩罚系数,类似于LR中的正则化系数,C越大惩罚越大
nu,代表训练集训练的错误率的上限(用于NuSVC)
kernel,核函数类型,RBF, Linear, Poly, Sigmoid,precomputed,默认为RBF径向基核(高斯核函数)
gamma,核函数系数,默认为auto
degree,当指定kernel为'poly'时,表示选择的多项式的最高次数,默认为三次多项式
probability,是否使用概率估计
shrinking,是否进行启发式,SVM只用少量训练样本进行计算
penalty,正则化参数,L1和L2两种参数可选,仅LinearSVC有
loss,损失函数,有‘hinge’和‘squared_hinge’两种可选,前者又称L1损失,后者称为L2损失
tol:残差收敛条件,默认是0.0001,与LR中的一致
SVC,Support Vector Classification,支持向量机用于分类
SVR,Support Vector Regression,支持向量机用于回归
sklearn中支持向量分类主要有三种方法:SVC、NuSVC、LinearSVC
基于libsvm工具包实现,台湾大学林智仁教授在2001年开发的一个简单易用的SVM工具包
SVC,C-Support Vector Classification,支持向量分类
NuSVC,Nu-Support Vector Classification,核支持向量分类,和SVC类似,不同的是可以使用参数来控制支持向量的个数
LinearSVC,Linear Support Vector Classification线性支持向量分类,使用的核函数是linear
libsvm中自带了四种核函数:线性核、多项式核、RBF以及sigmoid核
Kernel核的选择技巧的:
•如果样本数量<特征数:
方法1:简单的使用线性核就可以,不用选择非线性核
方法2:可以先对数据进行降维,然后使用非线性核
•如果样本数量>=特征数
可以使用非线性核,将样本映射到更高维度,可以得到比较好的结果
# 逻辑回归模型
# 逻辑回归是什么
逻辑回归就做一件事:把东西分成两类。
比如:
- 这封邮件是垃圾邮件还是正常邮件?
- 这个用户会点击广告还是不会?
- 这个人会违约还款还是不会?
答案只有两个:是或否,0或1。
逻辑回归的四个关键步骤:
- 假设数据服从伯努利分布 → 后面详细讲
- 极大化似然函数 → 后面详细讲
- 梯度下降求解参数 → 后面详细讲
- 二分类 → 就是分两类
# 两个假设 + Sigmoid函数
# 假设1:伯努利分布
什么是伯努利分布?
就是"只有两种结果"的分布。比如:
- 抛硬币:正面或反面
- 考试:及格或不及格
- 明天:下雨或不下雨
每次结果只有两种可能,而且每次之间互不影响。
逻辑回归假设你要预测的事情就是这样——要么是1(正类),要么是0(负类),没有第三种可能。
# 假设2:Sigmoid函数
这是逻辑回归的核心。先看问题:
我想预测一封邮件是垃圾邮件的概率,概率应该在0到1之间,对吧?0%到100%。
但普通的线性方程 y = θ₁x₁ + θ₂x₂ + ... 算出来的值可能是负数,也可能大于1,比如算出来-3或者5,这就不是概率了。
Sigmoid函数就是来解决这个问题的——它能把任何数字压缩到0和1之间。
公式:g(z) = 1 / (1 + e⁻ᶻ)
不用怕这个公式,我们用几组数字感受一下:
| z的值 | e⁻ᶻ | 1+e⁻ᶻ | 1/(1+e⁻ᶻ) = g(z) |
|---|---|---|---|
| 0 | 1 | 2 | 0.5 |
| 5 | 0.007 | 1.007 | ≈0.993 |
| -5 | 148.4 | 149.4 | ≈0.007 |
| 100 | ≈0 | ≈1 | ≈1 |
| -100 | 极大 | 极大 | ≈0 |
看出来了吗?
- z很大 → 结果接近1
- z很小(负很多)→ 结果接近0
- z=0 → 结果正好0.5
画出来就是一条S形曲线:
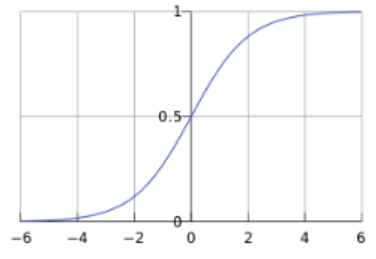
把线性方程的结果塞进Sigmoid,就变成了0到1之间的概率:
p = 1 / (1 + e⁻⁽θᵀˣ⁾)
翻译:把所有特征乘上权重加起来(θᵀx),塞进Sigmoid,得到"属于正类的概率"。
- p > 0.5 → 判断为1(正类)
- p < 0.5 → 判断为0(负类)
# 决策边界 + 损失函数
# 决策边界
就是那条把两类分开的线。
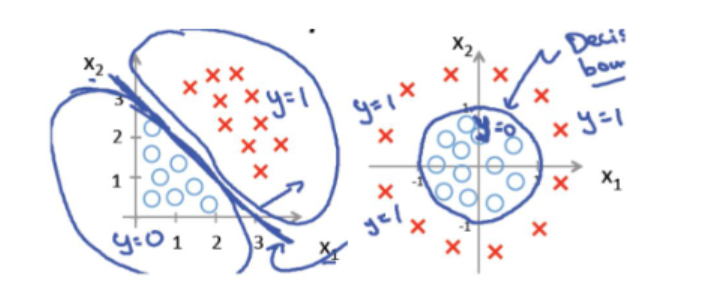
线性决策边界:一条直线就能分开。比如左边是1,右边是0。
非线性决策边界:直线分不开,需要曲线。比如0类被1类包围成一圈。
逻辑回归默认只能画直线(线性边界)。
# 损失函数
什么是损失函数? 就是衡量"预测错得有多离谱"的分数。错得越离谱,损失越大。
为什么不能直接用简单的误差?
比如预测概率0.9,实际是1,误差0.1。预测概率0.1,实际是1,误差0.9。看起来还行?
但逻辑回归用的是概率,不能简单用差值。它用的是:
- 当真实值=1时:Cost = -log(p)
- 当真实值=0时:Cost = -log(1-p)
为什么长这样?用数字感受:
真实值=1时(应该是正类):
| 预测p | -log(p) | 感受 |
|---|---|---|
| 0.99 | 0.01 | 预测对,损失很小 |
| 0.5 | 0.69 | 半对半错,损失中等 |
| 0.01 | 4.6 | 预测严重错误,损失巨大 |
真实值=0时(应该是负类):
| 预测p | -log(1-p) | 感受 |
|---|---|---|
| 0.01 | 0.01 | 预测对,损失很小 |
| 0.5 | 0.69 | 半对半错 |
| 0.99 | 4.6 | 预测严重错误,损失巨大 |
核心逻辑:预测错得越离谱,惩罚越重,而且不是线性增长,是指数级增长。
# 极大似然 + 梯度下降
极大似然就是:找到一组参数θ,让所有训练数据出现的概率最大。
通俗说:你要找一组规则,让"按照这组规则,训练数据最可能长成现在这样"。
梯度下降就是找参数的方法:从某个起点出发,每次往"损失变小"的方向走一步,一步步走到损失最小的位置。
想象你蒙着眼站在山上,想走到谷底。你用脚探一探,哪个方向最陡往下走,就往那个方向迈一步。重复很多次,你就到谷底了。
# 似然函数 + 为什么要去掉相关特征
# 似然函数
概率 vs 似然,很多人分不清:
- 概率:参数已知,预测数据。比如"硬币是均匀的(参数),抛10次出现3次正面的概率是多少?"
- 似然:数据已知,推测参数。比如"抛了10次出现3次正面(数据),硬币有多大概率是均匀的?"
似然函数就是反过来用概率: L(θ|x) = P(X=x|θ)
在逻辑回归里,我们要找让似然函数最大的θ,这叫"极大似然估计"。
# 为什么要去掉高度相关的特征?
比如你预测一个人会不会买房,有两个特征:面积(平米)和面积(平方英尺)。这两个其实是一回事,就是同一个信息说了两遍。
问题:
- 可解释性差:两个特征说同一件事,你分不清到底哪个在起作用
- 训练变慢:多余的特征让计算量增大,浪费时间
所以要把重复的去掉,留一个就行。
# 逻辑回归的优缺点
优点:
- 简单好懂,能解释(不像神经网络是黑盒)
- 能看到每个特征的影响力大小(权重大的特征更重要)
- 工程上经常当baseline(第一版先用逻辑回归跑,够用就不换)
- 训练快,计算量小
- 资源占用小
- 输出是概率,调阈值很方便(比如你可以把0.5改成0.7,让判断更严格)
缺点:
- 准确率不够高,太简单了,拟合不了复杂的分布
- 样本不均衡时表现差(比如99%是0类,1%是1类,模型会全预测0)
- 只能处理线性可分(直线能分开的情况),非线性搞不定
- 不能自动筛选特征,得人工或用别的方法先选好
# 机器学习五大流派总结
| 学派 | 核心信念 | 代表算法 |
|---|---|---|
| 符号学派 | 万事有因果,机器能自己摸索规律 | 决策树 |
| 贝叶斯学派 | 因果不是必然的,是有概率的 | 朴素贝叶斯 |
| 类推学派 | 通过类比学习未知,关键是定义"相似度" | SVM、KNN |
| 联结学派 | 模仿人脑神经元,靠连接方式识别模式 | 神经网络、深度学习 |
| 进化学派 | 适者生存,好的基因被保留 | 遗传算法 |
用大白话理解这五个学派:
- 符号学派像一个严谨的法官:根据规则一条条判断,"如果天气晴且温度高,则不打球"
- 贝叶斯学派像一个老医生:凭经验先猜,看到新症状就更新判断
- 类推学派像一个侦探:这个案件跟之前那个很像,所以结论应该也差不多
- 联结学派像一个模仿者:我不理解为什么,但我看了几万张猫的图片,我就认识猫了
- 进化学派像一个育种师:好的留下来,差的淘汰,一代代优化
# 模型选择
# 1. 线性回归
做什么: 预测一个具体的数字。比如预测房价、预测销量、预测考试分数。
原理: 画一条线,让这条线尽量贴近所有数据点。
举个例子:你想根据面积预测房价
- 50平米 → 100万
- 80平米 → 160万
- 100平米 → 200万
你会发现面积和价格之间大致是"面积越大越贵"的关系,画一条直线穿过这些点,新来一个120平米的,延长线一看就是240万。
一句话:线性回归就是画一条线,用一条线预测未来。
局限: 只能处理"一个东西越大另一个也越大"这种简单直线关系。弯弯曲曲的关系它搞不定。
# 2. 决策树
做什么: 分类或预测,通过不停问问题来做判断。
原理: 你昨天学过了——从挑西瓜到审批贷款,一层层问下去,每个节点选信息增益最大的属性来切分。
一句话:决策树就是不停问问题,问到最后就有答案。
局限: 容易过拟合(死记硬背),一棵树不够稳。
# 3. 随机森林
做什么: 分类或预测,比决策树更准更稳。
原理: 你也学过了——造100棵不同的决策树,每棵树独立判断,最后投票。两次随机(随机抽数据+随机选特征)确保每棵树不一样。
一句话:随机森林就是一群决策树投票,少数服从多数。
优势: 比单棵决策树稳得多,不容易过拟合,是工程上最常用的算法之一。
# 4. 朴素贝叶斯
做什么: 分类,尤其擅长文本分类(垃圾邮件、情感分析)。
原理: 前天你学过——先用经验猜一个概率,看到新线索就更新。假设所有特征互相独立,把条件概率乘起来比大小。
一句话:朴素贝叶斯就是根据经验+新证据,用概率做判断。
局限: "朴素"的独立假设太强硬,现实中特征往往互相关联。但即便假设不成立,效果经常也还不错。
# 5. SVM(支持向量机)
做什么: 分类,找最优的分界线。
原理: ——二维分不开就升到三维去分。找一条离两边数据都最远的分界线(间隔最大),这样分类最稳。
一句话:SVM就是找最宽的隔离带,把两类数据分得最开。
举个例子: 想象两队人面对面站着,你要在中间画一条线把他们隔开。SVM不光画线,还要求这条线离两边最近的人都尽可能远——这样就算新人站得歪一点也不会被分错。
局限: 数据量大的时候训练特别慢,现在不如神经网络流行了。
# 6. XGBoost
做什么: 分类或预测,是目前竞赛和数据科学中最强的算法之一。
原理: 它跟随机森林不一样。随机森林是100棵树同时投票,XGBoost是一棵树接一棵树地练,每棵新树专门修补上一棵树的错误。
举个例子:
- 树1预测,答对了70%,错了30%
- 树2专门盯着那30%的错误来练,又修掉了一半
- 树3再盯着剩下的错误继续修
- ...100棵树下来,错误越来越少
一句话:XGBoost就是一棵树修补一棵树的错误,越修越准。
这种思路叫Boosting(提升),跟随机森林的Bagging(投票)是两个方向。
# 7. LightGBM
做什么: 跟XGBoost一样,分类或预测,但更快。
原理: 核心思路跟XGBoost一样——Boosting,一棵树修一棵树的错。但它在实现上做了优化,训练速度比XGBoost快很多。
它是怎么变快的? 简单说就是XGBoost是一层一层地长树,LightGBM是按叶子来长——哪个叶子收益最大就先长哪个,不浪费计算在没用的地方。
一句话:LightGBM就是速度更快、内存更省的XGBoost。
# 8. CatBoost
做什么: 跟XGBoost、LightGBM一样,分类或预测。
原理: 同样是Boosting思路。它的特色是对类别型特征处理得特别好。
什么是类别型特征?就是非数字的特征,比如"城市名"、"商品类型"、"用户职业"。XGBoost和LightGBM需要你先把这类特征转成数字(比如独热编码),CatBoost直接吃原始数据就行,不需要你手动转换。
一句话:CatBoost就是不用你操心特征预处理的Boosting,开箱即用。
# 对比总结
# 按思路分两大阵营
| 阵营 | 思路 | 代表算法 | 比喻 |
|---|---|---|---|
| Bagging(投票派) | 多棵树同时训练,投票决定 | 随机森林 | 100个专家各自判断,少数服从多数 |
| Boosting(提升派) | 一棵树修一棵树的错,越修越准 | XGBoost、LightGBM、CatBoost | 一个学生做完题,老师指出错误,下一个学生专门练这些错题 |
# 全面对比
| 模型 | 做什么 | 速度 | 准确率 | 可解释性 | 最适合场景 |
|---|---|---|---|---|---|
| 线性回归 | 预测数字 | 极快 | 低 | 高 | 简单直线关系、第一版baseline |
| 决策树 | 分类/预测 | 快 | 中 | 最高 | 需要看懂决策逻辑的场景 |
| 随机森林 | 分类/预测 | 中 | 高 | 中 | 通用场景,表格数据的万金油 |
| 朴素贝叶斯 | 分类 | 极快 | 中 | 中 | 文本分类、垃圾邮件 |
| SVM | 分类 | 慢 | 高 | 低 | 小数据量、高维特征 |
| XGBoost | 分类/预测 | 较慢 | 最高 | 低 | 数据竞赛、追求极限准确率 |
| LightGBM | 分类/预测 | 快 | 最高 | 低 | 大数据量、要求速度 |
| CatBoost | 分类/预测 | 中 | 最高 | 低 | 类别特征多的场景,开箱即用 |
# 怎么选?一句话指南
- 想快想简单 → 线性回归 / 朴素贝叶斯
- 想看懂逻辑 → 决策树
- 通用稳妥 → 随机森林
- 追求最准 → XGBoost / LightGBM / CatBoost
- 数据量大要快 → LightGBM
- 懒得做特征预处理 → CatBoost
- 数据少特征多 → SVM